
【大厂面试必备系列】滑动窗口协议
引言
想象一下这个场景:主机 A 一直向主机 B 发送数据,不考虑主机 B 的接收能力,则可能导致主机 B 的接收缓冲区满了而无法再接收数据,从而导致大量的数据丢包,引发重传机制。而在重传的过程中,若主机 B 的接收缓冲区情况仍未好转,则会将大量的时间浪费在重传数据上,降低传送数据的效率。
所以引入了流量控制机制,主机 B 通过告诉主机 A 自己接收缓冲区的大小,来使主机 A 控制发送的数据量。总结来说:所谓流量控制就是控制发送方发送速率,保证接收方来得及接收。
TCP 实现流量控制主要就是通过 滑动窗口协议。
对于发送方来说,窗口大小就是指无需等待确认应答,可以连续发送数据的最大值。
窗口大小具体由谁来设定呢?
窗口大小和 TCP 报文首部中 16 位的 窗口大小 Window 字段有关:
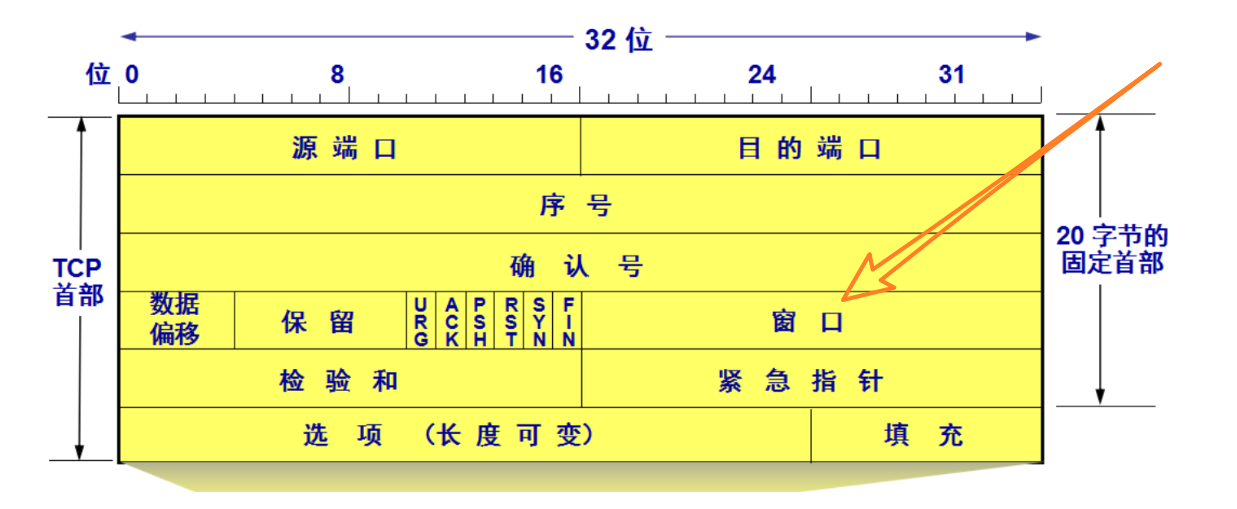
该字段的含义是指自己接收缓冲区的剩余大小,于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。
所以,通常来说窗口大小是由接收方来决定的。
滑动窗口详解
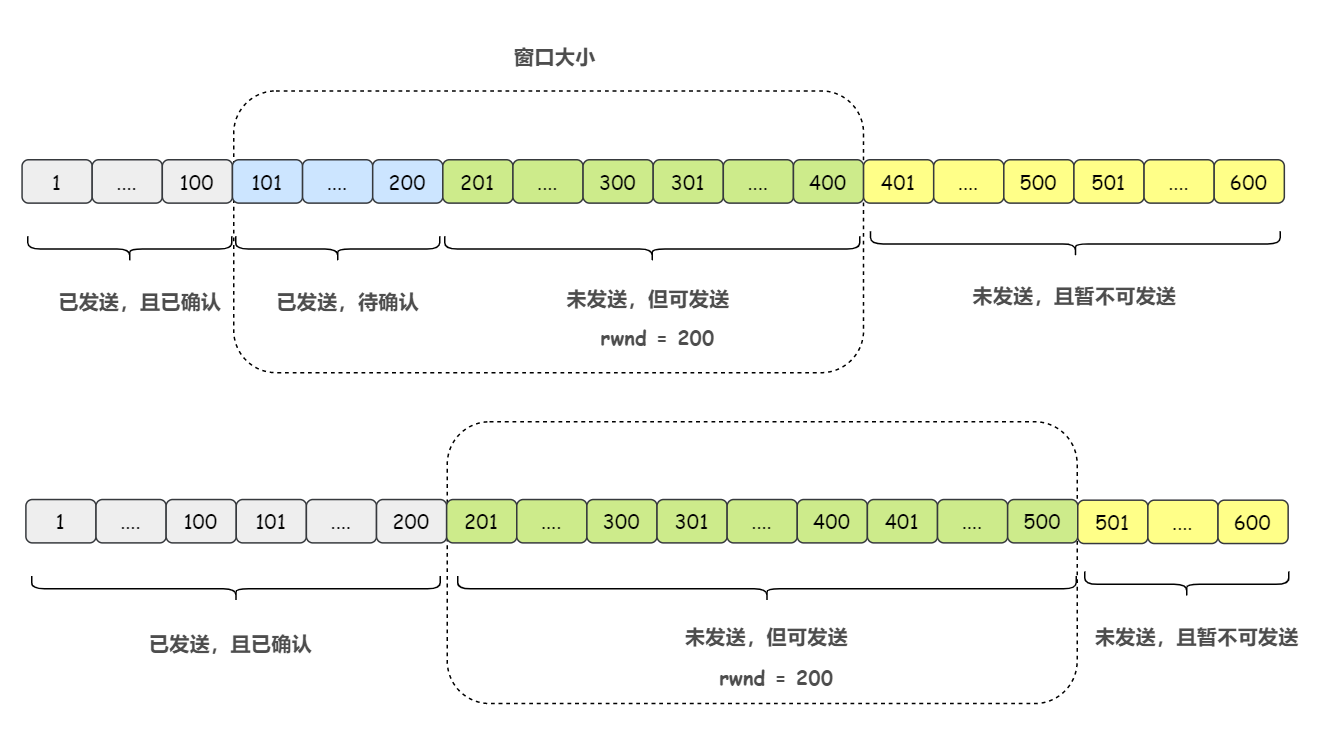
站在发送方的角度,滑动窗口可以分为四个部分:
- 已发送且已确认,这部分已经发送完毕,可以忽略;
- 已发送但未确认,这部分可能在网络中丢失,数据必须保留以便必要时重传;
- 未发送但可发送,这部分接收方缓冲区还有空间保存,可以发出去;
- 未发送且暂不可发送,这部分已超出接收方缓冲区存储空间,就算发出去也没意义;
第 2 和第 3 部分加起来就刚好就是接收方窗口大小,它规定了当前发送方能发送的最大数据量。
发送方在收到确认应答报文之前,必须在窗口中保留已发送的报文段(因为报文段可能在网络中丢失,所以必须把这些未确认的报文段保留这,以便必要时重传);如果在规定时间间隔内收到接收方发来的确认应答报文,就可以将这些报文段从窗口中清除。
当发送方收到接收方发来的确认应答后,就将窗口中那些被确认的报文清除出去,然后窗口向右移动,如下图所示:
随着双方通信的进行,窗口将不断向右移动,因此被形象地称为滑动窗口(Sliding Window)
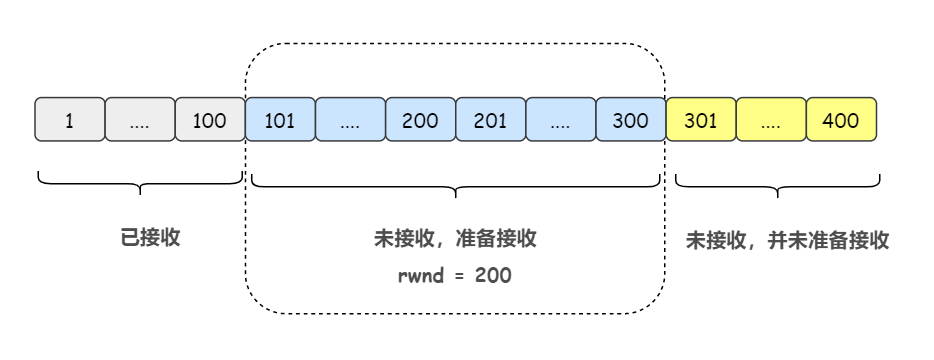
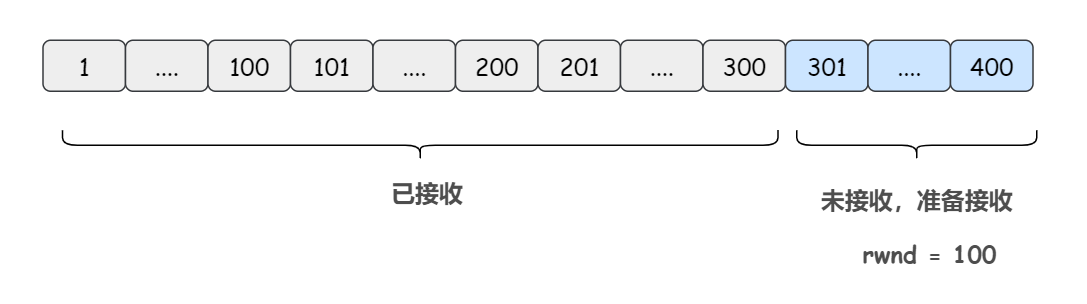
对于 TCP 的接收方,窗口稍微简单点,分为三个部分:
- 已接收
- 未接收准备接收 (也即接收窗口,再强调一遍,接收窗口的大小决定发送窗口的大小)
- 未接收并未准备接收
由于 ACK 直接由 TCP 协议栈回复,默认无应用延迟,不存在 “已接收未回复 ACK”
综上,举个例子,假设发送方需要发送的数据总长度为 400 字节,分成 4 个报文段,每个报文段长度是 100 字节:
1)三次握手连接建立时接收方告诉发送方,我的接收窗口大小(rwnd) 是 300 字节
此时的接收方滑动窗口如下:
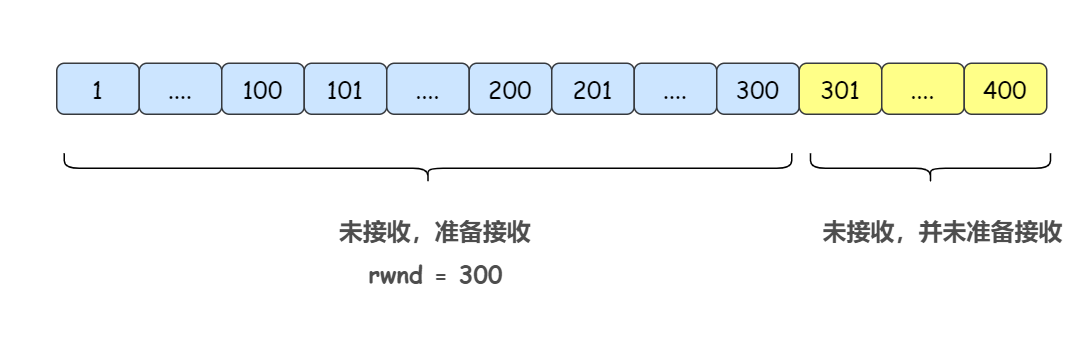
此时的发送方滑动窗口如下:
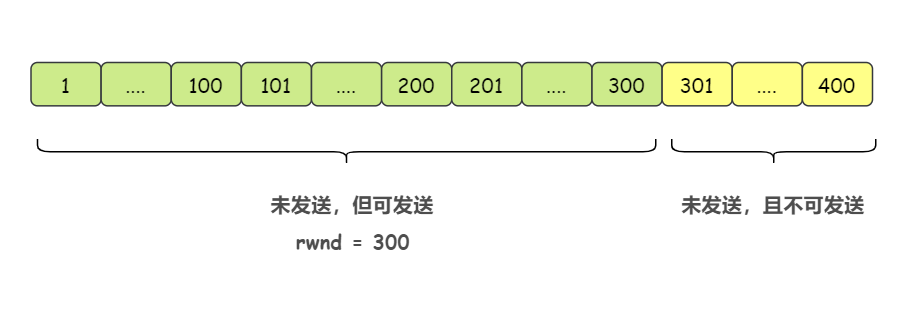
2)发送方发送第一个报文段(序号 1 - 100),还能再发送 200 个字节
3)发送方发送第二个报文段(序号 101 - 200),还能再发送 100 个字节
4)发送方发送第三个报文段(序号 201 - 300),还能再发送 0 个字节
此时,发送方的窗口中存了三个报文段了
此时的发送方滑动窗口如下:
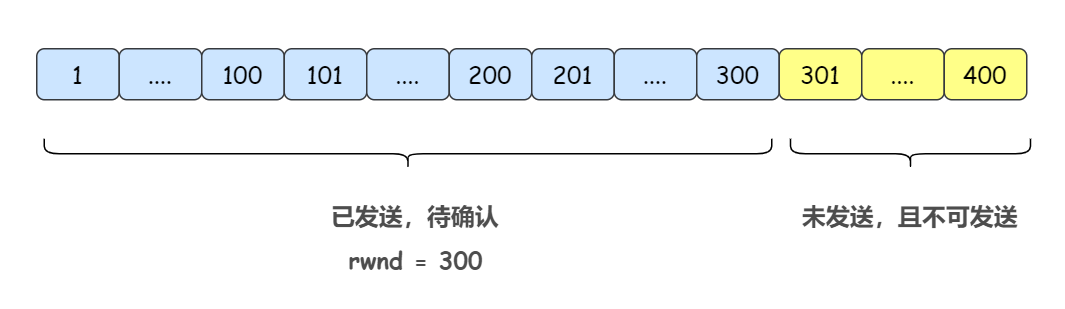
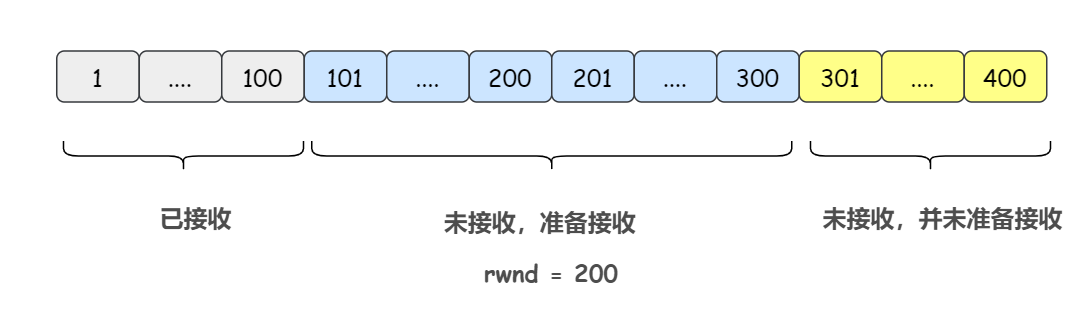
5)接收方接收到了第一个报文段和第三个报文段,中间第二个报文段丢失。此时接收方返回一个报文段 ack = 101, rwnd = 200(假设这里发生流量控制,把窗口大小降到了 200,允许发送方继续发送起始序号为 101,长度为 200 的报文)
此时的接收方滑动窗口如下(本来窗口右端应该右移,但是这里发生了流量控制,接收方希望缩小窗口大小,所以正好,这里就不需要向右扩展了):
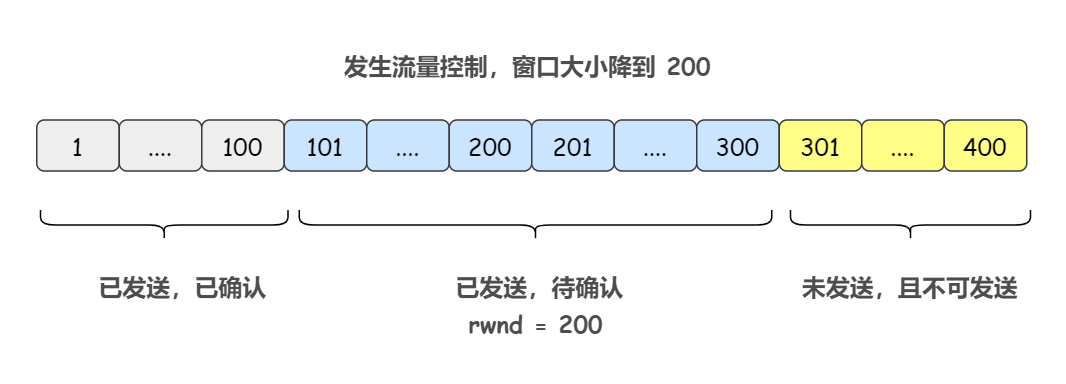
发送方收到了第一个报文段的确认,从窗口中移除掉第一个报文段
此时的发送方滑动窗口如下:
6)发送方一直没有收到第二个报文段的确认应答,在等待超时后重传第二个报文段(序号 101 - 200)
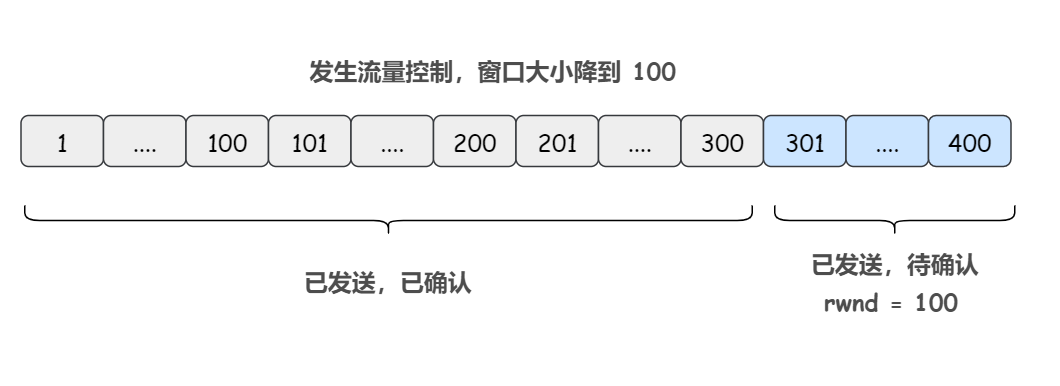
7)接收方成功收到第二个报文段(窗口中有第二个和第三个报文段了),于是向发送方返回一个报文段 ack = 301, rwnd = 100(假设这里发生流量控制,把窗口大小降到了 100)
此时的接收方滑动窗口如下:(本来窗口右端应该右移,但是这里发生了流量控制,接收方希望缩小窗口大小,所以正好,这里就不需要向右扩展了)
发送方收到了第二个和第三个报文段的确认,从窗口中移除掉这俩报文段
8)发送方发送第四个报文段(序号 301 - 400)
此时的发送方滑动窗口如下:
⭐ 窗口的本质
说了半天,窗口好像只是一个虚无缥缈的概念,
实际上,由于 TCP 是内核维护的,所以窗口中的报文数据其实就是存放在内核缓冲区中
注意这里区分下内核缓冲区(buffer)和高速缓存的概念
内核缓冲区大小一般是不会发生改变的,缓冲区大小 > 窗口大小,且窗口大小根据缓冲区中空闲空间的大小在不断发生改变。
对于接收方来说:
- 接收方根据缓冲区空闲的空间大小,计算出后续能够接收多少字节的报文(即接收窗口的大小)
- 当内核接收到报文时,将其存放在缓冲区中,这样缓冲区中空闲的空间就变小了,接收窗口也就随之变小了
- 当进程调用
read函数后(将数据从内核缓冲区复制到用户/进程缓冲区),报文数据被读入了用户空间,内核缓冲区就被清空,这意味着主机可以接收更多的报文,接收窗口就会变大
对于发送方来说,进程在发送报文之前会调用 write 函数(将数据从用户/进程缓冲区写到内核缓冲区),这样,缓冲区中可用空间变小,窗口变小,可发送的数据就变少了,等收到这些发送出去的数据的确认应答后,再从缓冲区中清除掉,从而使得窗口变大。
通俗的例子
下面来更通俗地解释下滑动窗口,看下面这个场景,老师(发送方)说一段话,学生(接收方)来记
最原始的模式,发送方一股脑把所有的报文段全都发出去。
老师说 "危楼高百尺,手可摘星辰,不敢高声语,恐惊天上人"(咱把每个字看成一个报文段,总共 20 个报文段)
学生写道"危楼高百尺,手可......."
上面的模式过于简单粗暴,发送方发送速度太快,接收方跟不上,并且重传成本过高。
于是他们换了一种模式:每发送一个报文段就等待确认一个报文段,收到确认后才能发送下一个
老师说 "危",学生说"确认"
老师说 "楼",学生说"确认"
老师说 "高",学生说"确认"
.........
上面的模式每发一个报文段,必须等到确认后才能再次发送,效率低下。
于是他们又换了一种模式:累积确认,既不是一股脑把所有的报文段全都发出去,也不是一次只发一个报文段,而是分组发送,每次发几个报文段。
老师说 "危楼高百尺" (5 个报文段),学生说 "确认"
老师说 "手可摘星辰",学生说 "手可..."(3 个报文段丢失)
老师说 "不敢高声语",学生说 "确认"
老师一直没有收到 "摘星辰" 的确认,于是重新说了一遍 "摘星辰",学生说 "确认"
老师说 "恐惊天上人",学生说 "确认"
上面的模式提高了效率,连续多个报文段一起进行发送, 但是到底该怎么决定多少个报文段一起发送呢呢?
于是他们在上面模式的基础上,做出了一些改进:滑动窗口,接收方认为状态好(窗口比较大)的时候, 让发送方每次多发一点;接收方认为状态不好(窗口比较小)的时候,让发送方每次少发送一点,起到一个流量控制的作用,限制发送方的速度。
学生告诉老师,我一次性可以接收 10 个报文段
老师说 "危楼高百尺,手可摘星辰",学生说 "危楼高百尺,手可..."(3 个报文段丢失,返回 ”可" 的确认应答,一共确认了 7 个报文段,老师的可用窗口右移,窗口中现在还有 “摘星辰” 3 个报文段)
学生说,我状态不行,一次性现在只能接收 5 个报文段(流量控制,缩小窗口)
老师说 "不敢"(窗口中还有 “摘星辰” 3 个报文段,所以只能发送 2 个),学生说 "确认"
老师一直没有收到 "摘星辰" 的确认,于是重新说了一遍,学生说 "确认"
(可用窗口恢复为 5 个)老师说 "恐惊天上人",......
小伙伴们大家好呀,我是小牛肉,公众号【飞天小牛肉】定期推送大厂面试题,提供背诵版 + 详细版,知其然而知其所以然,让八股文变得有价值!)



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 在鹅厂做java开发是什么体验
· 百万级群聊的设计实践
· WPF到Web的无缝过渡:英雄联盟客户端的OpenSilver迁移实战
· 永远不要相信用户的输入:从 SQL 注入攻防看输入验证的重要性
· 全网最简单!3分钟用满血DeepSeek R1开发一款AI智能客服,零代码轻松接入微信、公众号、小程