
标准化和归一化对机器学习经典模型的影响
归一化
归一化也称标准化,是处理数据挖掘的一项基础工作,使用归一化的原因大体如下:
数据存在不同的评价指标,其量纲或量纲单位不同,处于不同的数量级。解决特征指标之间的可比性,经过归一化处理后,各指标处于同一数量级,便于综合对比。求最优解的过程会变得平缓,更容易正确收敛。即能提高梯度下降求最优解时的速度。提高计算精度。适合进行综合对比评价。
MinMaxScaler
线性归一化,也称为离差标准化,是对原始数据的线性变换,MinMax标准化方法的缺陷在当有新数据加入时,可能会导致X.max和X.min的值发生变化,需要重新计算。其转换函数如下:
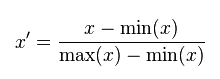
StandardScaler
标准差归一化,也叫Z-score标准化,这种方法给予原始数据的均值(mean,μ)和标准差(standard deviation,σ)进行数据的标准化。经过处理后的数据符合标准正态分布,即均值为0,标准差为1,转化函数为:
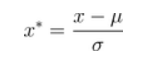
MaxAbsScaler
原理与MinMaxScaler很像,只是数据会被规模化到[-1,1]之间。也就是特征中,所有数据都会除以最大值。这个方法对那些已经中心化均值维0或者稀疏的数据有意义。
模型
本次实验使用了5个模型,分别为Lasso、Redige、SVR、RandomForest、XGBoost。
方法:
- 以不同方式划分数据集和测试集
- 使用不同的归一化(标准化)方式
- 使用不同的模型
- 通过比较MSE(均方误差,mean-square error)的大小来得出结论
部分代码及结果


1 import numpy as np 2 import pandas as pd 3 import matplotlib.pyplot as plt 4 5 #data = pd.read_csv('路径') 6 7 data = data.sort_values(by='time',ascending=True) 8 data.reset_index(inplace=True,drop=True) 9 10 target = data['T1AOMW_AV'] 11 del data['T1AOMW_AV'] 12
数据处理:
去除缺失值
1 # 没有缺失值 2 All_NaN = pd.DataFrame(data.isnull().sum()).reset_index() 3 All_NaN.columns = ['name','times'] 4 All_NaN.describe()

所有数据中,干掉 方差小于1的属性
1 feature_describe_T = data.describe().T 2 std_feature = feature_describe_T[feature_describe_T['std']<1].index 3 feature = [column for column in data.columns if column not in std_feature] # 筛选方差大于1的属性 4 data = data[feature] 5 6 del data['time']
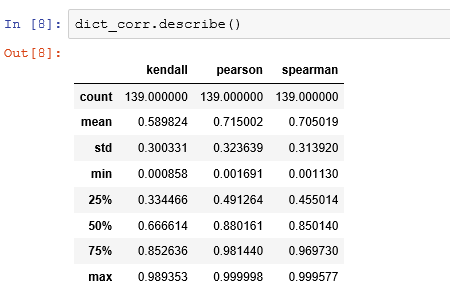
1 test_data = data[:5000] 2 3 data1 = data[5000:16060] 4 target1 = target[5000:16060] 5 data2 = data[16060:] 6 target2 = target[16060:] 7 8 import scipy.stats as stats 9 dict_corr = { 10 'spearman' : [], 11 'pearson' : [], 12 'kendall' : [], 13 'columns' : [] 14 } 15 16 for i in data.columns: 17 corr_pear,pval = stats.pearsonr(data[i],target) 18 corr_spear,pval = stats.spearmanr(data[i],target) 19 corr_kendall,pval = stats.kendalltau(data[i],target) 20 21 dict_corr['pearson'].append(abs(corr_pear)) 22 dict_corr['spearman'].append(abs(corr_spear)) 23 dict_corr['kendall'].append(abs(corr_kendall)) 24 25 dict_corr['columns'].append(i) 26 27 # 筛选新属性 28 dict_corr =pd.DataFrame(dict_corr) 29 new_fea = list(dict_corr[(dict_corr['pearson']>0.32) & (dict_corr['spearman']>0.48) & (dict_corr['kendall']>0.44)]['columns'].values) 30 # 选取原则,选取25%分位数 以上的相关性系数 31 dict_corr.describe() 32 len(new_fea)
各种模型的测试:
1 from sklearn.linear_model import LinearRegression,Lasso,Ridge 2 from sklearn.preprocessing import MinMaxScaler,StandardScaler,MaxAbsScaler 3 from sklearn.metrics import mean_squared_error as mse 4 from sklearn.svm import SVR 5 6 mm = MinMaxScaler() 7 lr = Lasso(alpha=0.5) 8 9 lr.fit(mm.fit_transform(data1[new_fea]), target1) 10 lr_ans = lr.predict(mm.transform(data2[new_fea])) 11 12 print("LR : ", mse(lr_ans,target2) )##lr 13 ridge = Ridge(alpha=0.5) 14 ridge.fit(mm.fit_transform(data1[new_fea]),target1) 15 ridge_ans = ridge.predict(mm.transform(data2[new_fea])) 16 17 print("ridge : ",mse(ridge_ans,target2 ))#ridge 18 svr = SVR(kernel='rbf',C=100,epsilon=0.1).fit(mm.fit_transform(data1[new_fea]),target1) 19 svr_ans = svr.predict(mm.transform(data2[new_fea])) 20 print("svr : ",mse(svr_ans,target2) )#svr 21 from sklearn.ensemble import RandomForestRegressor 22 from sklearn.model_selection import train_test_split 23 X_train, X_test, y_train, y_test = train_test_split(data[new_fea],target,test_size=0.25,random_state=12345) 24 25 ss = MaxAbsScaler() 26 ss_x_train = ss.fit_transform(X_train) 27 ss_x_test = ss.transform(X_test) 28 29 estimator_lr = Lasso(alpha=0.5).fit(ss_x_train,y_train) 30 predict_lr = estimator_lr.predict(ss_x_test) 31 print('Lssao:',mse(predict_lr,y_test)) 32 33 estimator_rg = Ridge(alpha=0.5).fit(ss_x_train,y_train) 34 predict_rg = estimator_rg.predict(ss_x_test) 35 print('Ridge:',mse(predict_rg,y_test)) 36 37 estimator_svr = SVR(kernel='rbf',C=100,epsilon=0.1).fit(ss_x_train,y_train) 38 predict_svr = estimator_svr.predict(ss_x_test) 39 print('SVR:',mse(predict_svr,y_test)) 40 41 estimator_RF = RandomForestRegressor().fit(ss_x_train,y_train) 42 predict_RF = estimator_RF.predict(ss_x_test) 43 print('RF:',mse(predict_RF,y_test)) 44 45 predict_XG = xgb.XGBRegressor(learn_rate=0.1,n_estimators = 550,max_depth = 4,min_child_weight = 5,seed=0,subsample=0.7,gamma=0.1,reg_alpha=1,reg_lambda=1) 46 predict_XG.fit(ss_x_train,y_train) 47 predict_XG_ans=predict_XG.predict(ss_x_test) 48 print("predict_XG : ", mse(predict_XG_ans,y_test)) 49 50 结果:
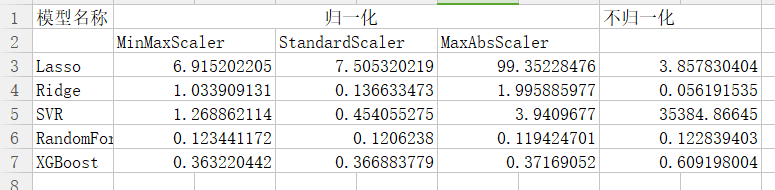
结论:
- 对于Lasso模型,使用MaxAbsScaler方式时,mse增大十分明显,且归一化后结果高于不进行归一化时;
- 对于Redige模型,归一化结果也明显高于不归一化时的结果;
- 对于SVR模型,不进行归一化时,其MSE会非常大;
- 对于RandomForest和XGBoost来说,是否进行归一化对结果影响不大;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号