
机器学习预测时label错位对未来数据做预测
前言
这篇文章时承继上一篇机器学习经典模型使用归一化的影响。这次又有了新的任务,通过将label错位来对未来数据做预测。
实验过程
使用不同的归一化方法,不同得模型将测试集label错位,计算出MSE的大小;
不断增大错位的数据的个数,并计算出MSE,并画图。通过比较MSE(均方误差,mean-square error)的大小来得出结论
过程及结果
数据处理(和上一篇的处理方式相同):


1 test_sort_data = sort_data[:5000] 2 test_sort_target = sort_target[:5000] 3 4 sort_data1 = _sort_data[5000:16060] 5 sort_data2 = _sort_data[16060:] 6 sort_target1 = _sort_target[5000:16060] 7 sort_target2 = _sort_target[16060:]
完整数据处理代码:
1 #按时间排序 2 sort_data = data.sort_values(by = 'time',ascending = True) 3 4 sort_data.reset_index(inplace = True,drop = True) 5 target = data['T1AOMW_AV'] 6 sort_target = sort_data['T1AOMW_AV'] 7 del data['T1AOMW_AV'] 8 del sort_data['T1AOMW_AV'] 9 10 from sklearn.model_selection import train_test_split 11 test_sort_data = sort_data[16160:] 12 test_sort_target = sort_target[16160:] 13 14 _sort_data = sort_data[:16160] 15 _sort_target = sort_target[:16160] 16 17 from sklearn.model_selection import train_test_split 18 test_sort_data = sort_data[:5000] 19 test_sort_target = sort_target[:5000] 20 21 sort_data1 = _sort_data[5000:16060] 22 sort_data2 = _sort_data[16060:] 23 sort_target1 = _sort_target[5000:16060] 24 sort_target2 = _sort_target[16060:] 25 26 import scipy.stats as stats 27 dict_corr = { 28 'spearman' : [], 29 'pearson' : [], 30 'kendall' : [], 31 'columns' : [] 32 } 33 34 for i in data.columns: 35 corr_pear,pval = stats.pearsonr(sort_data[i],sort_target) 36 corr_spear,pval = stats.spearmanr(sort_data[i],sort_target) 37 corr_kendall,pval = stats.kendalltau(sort_data[i],sort_target) 38 39 dict_corr['pearson'].append(abs(corr_pear)) 40 dict_corr['spearman'].append(abs(corr_spear)) 41 dict_corr['kendall'].append(abs(corr_kendall)) 42 43 dict_corr['columns'].append(i) 44 45 # 筛选新属性 46 dict_corr =pd.DataFrame(dict_corr) 47 dict_corr.describe()
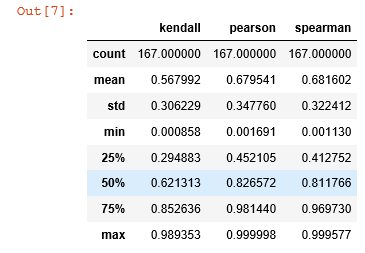
选取25%以上的;
1 new_fea = list(dict_corr[(dict_corr['pearson']>0.41) & (dict_corr['spearman']>0.45) & (dict_corr['kendall']>0.29)]['columns'].values)
包含下面的用来画图:
1 import matplotlib.pyplot as plt 2 lr_plt=[] 3 ridge_plt=[] 4 svr_plt=[] 5 RF_plt=[]
正常的计算mse(label没有移动):
1 from sklearn.linear_model import LinearRegression,Lasso,Ridge 2 from sklearn.preprocessing import MinMaxScaler,StandardScaler,MaxAbsScaler 3 from sklearn.metrics import mean_squared_error as mse 4 from sklearn.svm import SVR 5 from sklearn.ensemble import RandomForestRegressor 6 import xgboost as xgb 7 #最大最小归一化 8 mm = MinMaxScaler() 9 10 lr = Lasso(alpha=0.5) 11 lr.fit(mm.fit_transform(sort_data1[new_fea]), sort_target1) 12 lr_ans = lr.predict(mm.transform(sort_data2[new_fea])) 13 lr_mse=mse(lr_ans,sort_target2) 14 lr_plt.append(lr_mse) 15 print('lr:',lr_mse) 16 17 ridge = Ridge(alpha=0.5) 18 ridge.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1) 19 ridge_ans = ridge.predict(mm.transform(sort_data2[new_fea])) 20 ridge_mse=mse(ridge_ans,sort_target2) 21 ridge_plt.append(ridge_mse) 22 print('ridge:',ridge_mse) 23 24 svr = SVR(kernel='rbf',C=100,epsilon=0.1).fit(mm.fit_transform(sort_data1[new_fea]),sort_target1) 25 svr_ans = svr.predict(mm.transform(sort_data2[new_fea])) 26 svr_mse=mse(svr_ans,sort_target2) 27 svr_plt.append(svr_mse) 28 print('svr:',svr_mse) 29 30 estimator_RF = RandomForestRegressor().fit(mm.fit_transform(sort_data1[new_fea]),sort_target1) 31 predict_RF = estimator_RF.predict(mm.transform(sort_data2[new_fea])) 32 RF_mse=mse(predict_RF,sort_target2) 33 RF_plt.append(RF_mse) 34 print('RF:',RF_mse) 35 36 bst = xgb.XGBRegressor(learning_rate=0.1, n_estimators=550, max_depth=4, min_child_weight=5, seed=0, 37 subsample=0.7, colsample_bytree=0.7, gamma=0.1, reg_alpha=1, reg_lambda=1) 38 bst.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1) 39 bst_ans = bst.predict(mm.transform(sort_data2[new_fea])) 40 print('bst:',mse(bst_ans,sort_target2))
先让label移动5个:
1 change_sort_data2 = sort_data2.shift(periods=5,axis=0) 2 change_sort_target2 = sort_target2.shift(periods=-5,axis=0) 3 change_sort_data2.dropna(inplace=True) 4 change_sort_target2.dropna(inplace=True)
让label以5的倍数移动:
1 mm = MinMaxScaler() 2 3 for i in range(0,45,5): 4 print(i) 5 lr = Lasso(alpha=0.5) 6 lr.fit(mm.fit_transform(sort_data1[new_fea]), sort_target1) 7 lr_ans = lr.predict(mm.transform(change_sort_data2[new_fea])) 8 lr_mse=mse(lr_ans,change_sort_target2) 9 lr_plt.append(lr_mse) 10 print('lr:',lr_mse) 11 12 ridge = Ridge(alpha=0.5) 13 ridge.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1) 14 ridge_ans = ridge.predict(mm.transform(change_sort_data2[new_fea])) 15 ridge_mse=mse(ridge_ans,change_sort_target2) 16 ridge_plt.append(ridge_mse) 17 print('ridge:',ridge_mse) 18 19 svr = SVR(kernel='rbf',C=100,epsilon=0.1).fit(mm.fit_transform(sort_data1[new_fea]),sort_target1) 20 svr_ans = svr.predict(mm.transform(change_sort_data2[new_fea])) 21 svr_mse=mse(svr_ans,change_sort_target2) 22 svr_plt.append(svr_mse) 23 print('svr:',svr_mse) 24 25 estimator_RF = RandomForestRegressor().fit(mm.fit_transform(sort_data1[new_fea]),sort_target1) 26 predict_RF = estimator_RF.predict(mm.transform(change_sort_data2[new_fea])) 27 RF_mse=mse(predict_RF,change_sort_target2) 28 RF_plt.append(RF_mse) 29 print('RF:',RF_mse) 30 31 # bst = xgb.XGBRegressor(learning_rate=0.1, n_estimators=550, max_depth=4, min_child_weight=5, seed=0, 32 # subsample=0.7, colsample_bytree=0.7, gamma=0.1, reg_alpha=1, reg_lambda=1) 33 # bst.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1) 34 # bst_ans = bst.predict(mm.transform(change_sort_data2[new_fea])) 35 # print('bst:',mse(bst_ans,change_sort_target2)) 36 37 change_sort_target2=change_sort_target2.shift(periods=-5,axis=0) 38 change_sort_target2.dropna(inplace=True) 39 change_sort_data2 = change_sort_data2.shift(periods=5,axis=0) 40 change_sort_data2.dropna(inplace=True)
结果如图:
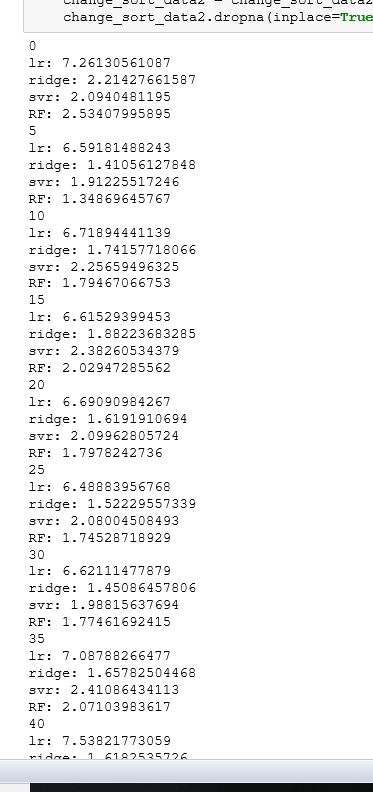
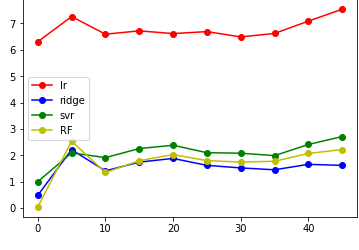
然后就是画图了;
1 plt.plot(x,lr_plt,label='lr',color='r',marker='o') 2 plt.plot(x,ridge_plt,label='ridge',color='b',marker='o') 3 plt.plot(x,svr_plt,label='svr',color='g',marker='o') 4 plt.plot(x,RF_plt,label='RF',color='y',marker='o') 5 plt.legend() 6 plt.show()
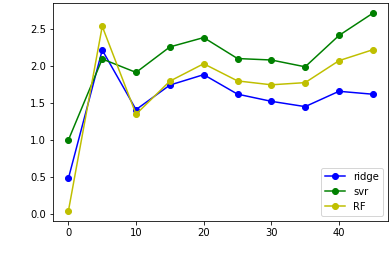
舍去lr,并扩大纵坐标:
1 #plt.plot(x,lr_plt,label='lr',color='r',marker='o') 2 plt.plot(x,ridge_plt,label='ridge',color='b',marker='o') 3 plt.plot(x,svr_plt,label='svr',color='g',marker='o') 4 plt.plot(x,RF_plt,label='RF',color='y',marker='o') 5 plt.legend() 6 plt.show()
其他模型只需将MinMaxScaler改为MaxAbsScaler,standarScaler即可;
总的来说,label的移动会使得mse增加,大约在label=10时候差异最小,结果最理想;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号