
Antipodal Robotic Grasping using Generative Residual Convolutional Neural Network(基于生成卷积神经网络的对跖机器人抓取)
原论文地址:https://arxiv.org/abs/1909.04810
代码地址:https://github.com/skumra/robotic-grasping
摘要:-在本文中,该文提出了一个模块化的机器人系统来解决从场景n通道图像中生成和执行对跖机器人抓取未知物体的问题。我们提出了一种新的生成残差卷积神经网络(GR-Convnet),可以实时(~20ms)下从N通道输入生成鲁棒的对跖抓取。该文在标准数据集和不同家庭对象上评估所提出的模型体系结构,在Conerll和Jacquard抓取数据集上,该文分别达到了97.7%和94.6%的准确率。该文也证明了使用7自由度的机械臂在家庭和对抗物体上的抓取成功率分别为95.4%和93%。
Ⅰ INTRODUCTION
由于人类具有基于自身经验本能快速、轻松地抓住未知物体地固有特征,机器人操作经常被拿来与人进行比较。随着越来越多的研究正在进行,以使机器人更智能,存在一个普遍的技术,以推断快速和鲁棒的抓取任何类型的物体。机器人遇到的主要挑战是如何能够精确地将机器人学习到地知识转移到真实世界的物体上。
该文提出了一种模块化的机器人不可知论方法来解决抓取未知物体的问题。我们提出了一种生成残差卷积神经网络,它对n通道中的每个像素生成对趾抓取,我们使用术语“抓取”来区分我们的方法和其他方法,其他方法输出一个抓取成功概率或者抓取分类样本,用来预测最佳的抓取。与之前在机器人抓取【1】,【2】,【3】,【4】不同,通过多个抓取概率中选择最佳的抓取概率,和预测所需概率为一个抓取矩形不同,我们网络生成了三个图像,从这些图像中我们可以推断出多个物体的抓取矩形。此外,可以从GR-ConvNet的输出中一次推断出多个物体的多个抓取,从而减少了总体计算时间。
图一显示了所提议的系统架构。它由两个主要模块组成:推理模块和控制模块。推理模块从RGB-D相机中获取场景RGB和对齐深度图像。图像经过预处理以匹配GR-ConvNet的输入格式,网络生成质量、角度、和宽度图像,利用上述输出推断对跖抓取位姿。所述控制模块包括任务控制器,该任务控制器准备并执行计划,以使用所述推理模块生成的抓取姿态执行拾取和放置任务。它通过使用轨迹规划和控制器的ROS接口向机器人传达所需的动作。
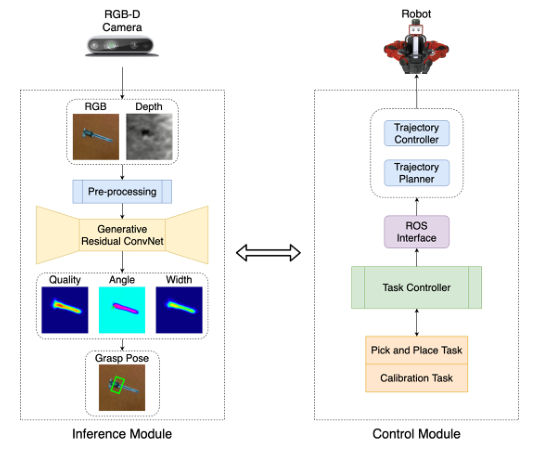
图一:提出了系统的概述。推理模块预测相机视场中物体合适的抓取姿势。控制模块使用这些抓取姿势来规划和执行机器人的轨迹来执行对跖抓取。
本文的主要贡献可以总结如下:
1、我们提出了一个模块化的机器人系统,用来预测、计划、并执行对跖抓取在场景中的对象并且将文中提到的inference和Control模块开源。
2、我们提出了一种新的生成残差卷积神经网络体系结构,该体系结构可以预测相机视觉场景内物体合适的对跖抓取配置。
3、我们在公开的数据集上评估了我们的模型,在Cornell和Jacquard抓取数据集上分别达到了97.7%和94.6%的精度。
4、我们证明了所提出的模型可以部署在机械臂上以实时的速度在家用物体和对抗物体上执行对跖抓取,并分别达到95.4%和93%的成功率。
Ⅱ RELATED WORK
机器人抓取:在机器人领域,特别是机器人抓取领域,已经有了广泛的正在进行的研究。尽管问题似乎仅仅是找到目标物体合适的抓取位置,但是实际任务涉及到多方面的元素比如被抓取的目标物体、目标物体的形状、对象的物理特性和抓取物体的钳子。这一领域的早期研究涉及到手动设计【5】【6】特征,这可能是一项乏味和耗时的任务,但是对用多个手指抓取物体有意义,如【7】【8】
为了获得稳定的抓取,首先研究了末端执行器和物体接触时的力学和接触运动学,并根据【9】【10】的调查结果进行了抓取分析。之前在机器人抓取新物体方面的工作【11】涉及到使用监督学习,这种学习是根据合成数据进行训练的,但仅限于办公室、厨房和洗碗机环境。Satish等人【12】引入了一种全卷积抓取质量卷积神经网络(FC-GQ-CNN),该网络通过使用数据收集策略和综合训练环境来预测鲁棒的抓取质量。该方法使使抓握次数在0.625S内增加到5000次。然而目前的研究更多地依赖于利用RGB-D数据来预测抓取姿态。这些方法完全依赖于深度学习技术。
面向抓取的深度学习:自从ImageNet的成功问世以及GPU等快速计算技术的使用以来,深度学习一直使研究的热点。此外,廉价的RGB-D传感器可用性使得深度学习技术能够直接从图像中学习物体的特征。最近使用的深度神经网络【2】【13】【14】的实验表明,他们可以有效的计算稳定抓取。pinto等人【3】使用了一种类似于AlexNet的架构,表明通过增加数据的大小,他们的CNN能够更好的地泛化到新的数据。V【15】提出了一种有趣的方法,通过形状来完成抓取规划,其中使用3D CNN来训练从不同视点捕获的对象数据集上的3D原型上的网络。Guo等人[16]使用触觉数据和视觉数据来训练混合的深度架构。Mahler等人[17]提出了一种抓取质量卷积神经网络(GQ-CNN),该网络从Dex-Net 2.0抓取规划数据集上训练的合成点云数据预测抓取。Levine等人[18]讨论了使用单目图像进行手眼协调,并使用深度学习框架进行机器人抓取。他们使用CNN进行抓取成功预测,并进一步使用连续伺服对机械手进行连续伺服以纠正错误。Antanas等人的[19]讨论了一种有趣的方法,称为概率逻辑框架,据说可以提高机器人的抓取能力这个框架结合了高级推理和低级抓取。高级推理包括对象启示、类别和基于任务的信息,而低级推理使用视觉形状特征。这已经被观察到在厨房相关的场景中工作得很好。
利用单模态数据抓取:约翰斯等人的[24]使用模拟深度图像来预测每个预测的抓取姿态的抓取结果,并使用一个抓取不确定性函数来平滑预测的姿态,从而选择最佳的抓取。莫里森等人的[20]讨论了抓取的生成方法。生成抓取CNN架构使用深度图像生成抓取姿势,网络以像素为基础计算抓取。[20]说明它减少了现有离散采样的缺点和计算复杂度。另一种最近的方法仅仅依赖深度数据作为深度CNN的唯一输入,如[13]所示。
利用多模态数据抓取:有不同的方法来处理物体的多模态。许多人使用单独的特征来学习可以在计算上穷举的模式。Wang等人提出了将多模态信息视为相同的方法。Jiang等人使用RGB-D图像基于两步学习过程来推断抓取。第一步缩小搜索空间,第二步从第一种方法得到的顶部抓取点计算最优抓取矩形。lenz等人使用类似的两部走的深度学习框架,但是可能不是适合所有类型的对象,经常预测并不是最优抓取位置的抓取,比如在【26】中算法预测鞋带的抓取位置,在实践中经常失败,而在【1】中,由于使用了RGB-D传感器和局部信息,算法有时候无法预测那种抓取更加实用。yan【27】使用点云预测网络,首先对数据进行预处理,获得颜色、深度、蒙面图像,然后获得物体的三维点云,送入网络预测抓取。chu【21】等人提出了一种新颖的结构,可以同时预测多个物体的多个抓取,而不是单个物体,为此,他们使用了自己的多对象数据集。该模型还在Cornell进行测试。Ogas讨论了一种机器人抓取方法,该方法用于物体识别的卷积神经网络和用于操纵物体的抓取方法组成。所述方法假定是一条工业生产装配线,其中假定对象参数预先知道。Kumar[4]等人提出了一种Deep CNN架构,该架构使用残余层来预测鲁棒抓取。研究结果表明,带残差的深度网络具有更好的特征学习能力和更快的性能。Asif引入了一个名为EnsembleeNet的整合框架,其中抓取生成网络生成四种抓握表征,EnsembleeNet将这些生成的抓握进行综合,生成抓握得分,从中选取得分最高的抓握。我们的工作基于类似的概念,旨在推进这一领域的研究。表一提供我们的工作与最近在机器人抓取未知物体方面的相关研究工作的比较。

Ⅲ PROBLEM FORMULATION
在本工作中,我们将机器人抓取问题定义为从n通道图像预测未知物体的对跖抓取,并且在机器人上执行它。
我们没有使用【1】【2】【4】中的五维抓取表征,而是使用了Morrsion等人在【20】中提出的一种改进的抓取表征。我们将机器人框架中的抓取姿态表征为: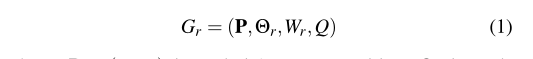
在上述公式中,P=(X,Y,Z)是工具的中心位置是工具绕Z轴旋转的角度,Wr是工具的宽度,Q是抓取的分数。
我们从N通道图像![]() ,其中高度为h,宽度为w,抓取图像可以定义为:
,其中高度为h,宽度为w,抓取图像可以定义为:
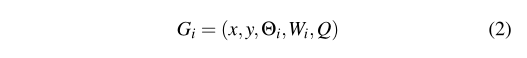
其中(x,y)对应于图像坐标中的抓取中心,![]() 是相机参照系内的旋转,Wi是图像坐标中所需的宽度,Q为式(1)中相同的标量。
是相机参照系内的旋转,Wi是图像坐标中所需的宽度,Q为式(1)中相同的标量。
抓取质量评分Q是图像中每个点的抓取质量,表示为0到1之间的评分值,接近1的评分值表示抓握成功的概率较大。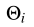 是对跖测量量,测量每个感兴趣的物体所需要的角度旋转量,并表示为【-pi/2,pi/2】中的一个值。Wi表示抓取时抓取器张开的宽度,表示均匀深度的度量,值的范围为【0,Wmax】。Wmax表示抓取器张开的最大宽度。
是对跖测量量,测量每个感兴趣的物体所需要的角度旋转量,并表示为【-pi/2,pi/2】中的一个值。Wi表示抓取时抓取器张开的宽度,表示均匀深度的度量,值的范围为【0,Wmax】。Wmax表示抓取器张开的最大宽度。
要在机器人上执行在图像空间中获得的抓取,我们可以应用下述变化将图像坐标转换为机器人的参照系。

Tci是利用相机的内在参数将图像空间转换为相机的三维空间的变换,Trc是利用相机的位姿标定值将相机空间转换为机器人空间的变换。
这个可以在图像的多次抓取中归一化,所有抓取的集合都可以表示为:
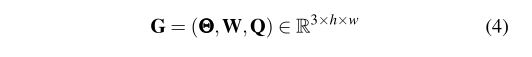
上式中, 分别代表由式(2)计算的每个像素处的抓取角度、抓取宽度、和抓取质量分数。
分别代表由式(2)计算的每个像素处的抓取角度、抓取宽度、和抓取质量分数。
Ⅳ.APPROACH
我们提出了一个双模块系统来预测,计划和执行对跖抓起在场景中的物体。所提出的系统概述如图1所示。推理模块用于预测相机视觉场景内物体核实的抓取姿态。该控制模块使用这些抓取姿态来规划和执行机器人的轨迹,以执行对跖抓取。
A:推理模块
推理模块由三大部分组成。首先,在裁剪、调整大小和规范化的地方对输入数据进行预处理。如果输入有深度图像,则对其进行内绘以获得深度表示【30】。224*224大小,n通道处理后的输入图像被送入GR-ConvNet。它使用n通道输入并不局限于特定的输入模式,比如只使用深度或者只使用rgb的图像作为我们的输入图像。因此,将其推广到任何类型的输入模态。第二部利用GRConvNet对预处理后的图像提取特征,生成三幅图像作为抓取角度、抓取宽度和抓取质量评分的输出。第三部分利用上述三幅图像输出抓取姿势。
B:控制模块
该控制模块主要包括一个任务控制器,执行拾取和校准等任务。控制器从推理模块请求一个抓取姿态,推理模块返回质量得分最高的抓取姿态。然后利用手眼标定【31】计算得到的变换将摄像机坐标抓换为机器人坐标。此外,机器人框架中的抓取姿态被用来轨迹规划,通过使用ROS接口使用逆运动学执行拾取和放置动作。然后机器人执行计划的轨迹。由于我们模块化方法和ROS集成,该系统可以用于任何机械臂。

C:模型架构
图2显示了本文提出的GR-ConvNet模型,这是一种生成架构,它接收n通道输入图像,并以三幅图像的形式生成像素级抓取。n通道图像经过3个卷积层,然后经过5个残差层和卷积转置层,生成4幅图像,这些输出图像由抓取质量分值、角度由sin2(sita)和con2(sita)组成以及末端执行器所需要的宽度。由于对跖抓取在±(pi/2)周围式均匀的,我们以两个元素sin2(sita)和con2(sita)的形式提取角度,这两个元素输出不同的值,并组合成所需的角度。
卷积层从输入图像中提取特征。然后将卷积层的输出作为输入放进5个剩余层。正如我们所知,精度随着层数的增加而增加。但是,当超过一定的数量的层时,就不是这样了,这会导致梯度消失和维数误差的问题,从而导致饱和和精度下降。因此,使用剩余层可以让我们通过跳过连接更好地学习特征函数。当图像经过这些卷积层和残差层后,图像地大小减小到56*56,这可能很难解释。因此,为了便于对卷积后的图像进行解释和保留空间特征,我们对图像进行卷积转置运算。这样,我们得到的输出图像的大小与输入图像的大小相同。
我们的网络总共有1900900个参数,这表明我们的网络相对于其他网络【4】,【22】,【29】来说比较短。因此,与使用包含百万个参数和复杂架构的类似抓取预测技术的其他架构相比,它的计算成本更低,速度更快。该模型的轻量化特性使其适合于在高达50HZ的速率下进行闭环控制。
D:训练方法

使用Adam优化器【32】。标准反向传播和小批量SGD技术【33】对模型进行训练。学习率设置为10-3,使用8个小批量。我们使用三种随机种子训练模型,报告三种种子的平均值。
E:损失函数
我们分析了我们网络中的各种损失函数的性能,经过几次实验后发现,为了处理梯度爆炸,平滑L1损失也被称为Huber损失最有效。我们把损失定义为:

Ⅴ.EVALUATION
A. 数据集
公开的对跖抓取数据集数量有限。表二显示了公开可用的对跖抓取数据集摘要。我们使用其中的两个数据集来训练和评估我们的模型。第一个是Cornell抓取数据集,这是最常用的抓取数据集,用于基准测试结果。第二个是Jacquard抓取数据集【34】。它比Cornell数据集大50多倍。

Cornell抓取数据集的扩展版本包含了1035张RGB-D图像,分辨率为640*480像素,包含了240个不同真实物体的5100的正抓取和2909的负抓取。被标注的Groud truth由每个物体的抓取的可能性的抓取矩形组成,对于我们的网络来说,Cornell数据集是一个小样本数据集,因此我们使用随机剪裁、缩放、和旋转创建一个增强数据集,从而有效的拥有51k个抓取样本。在训练过程中,只考虑从数据集中得到正向标记的抓取。
Jacquard抓取数据集建立在大型CAD模型数据集ShapeNet的一个子集上。它由54KRGB-D图像和基于模拟环境中抓取尝试的成功抓取位置标注组成。总共由110万个抓取样例。由于该数据集足够大,可以训练我们的模型,因此不执行增强操作。
B:抓取检测指标
为了与我们的结果进行比较,我们使用了Jiang等人提出的矩形度量【26】来报告我们系统的性能。根据本文提出的矩形度量,当一个抓取满足以下两个条件时,认为该抓取是有效的:
1、ground truth抓取矩形和预测抓取矩形的IoU相交值大于25%
2、预测的抓取矩形与ground truth抓取矩形的抓取方向偏差小于30°
这个度量要求一个抓取矩形表示,但是我们的模型使用方程2预测基于图像的抓取表示。因此,为了将基于图像的抓握表示转换为矩形表示,需要将输出图像中的每个像素对应的值映射为其等效的矩形表示。
Ⅵ. EXPERIMENTS
在我们的实验中,我们评估了我们的方法:(i)两个标准数据集,(ii)家庭对象,(iii)对抗对象和(Ⅳ)杂乱对象。
A:Setup
为了获得真实世界实验的场景图像,我们使用了立体视觉计算深度的英特尔RealSense深度相机D435。它由一堆RGB传感器、深度传感器和一个红外投影仪组成。实验是在Rethinking Robotics公司的7自由度Baxter机器人上进行的。采用两指平行夹持器抓取被试物体。摄像机安装在机器人手臂的后面,从肩膀上看过去。我们提出的pr-convnet的执行实践是在一个运行ubuntu16.04和inter Core i7-7800x cpu(3.50GHZ)和NVIDIA GeForce GTX1080Ti显卡(CUDA10)的系统上测试的。
B:家庭物件
共选择了35个家庭对象来测试我们的系统的性能。每个物体都被单独测试了10个不同的位置和方向,导致了350次抓取尝试。每个物体都代表不同的形状、大小和几何形状;而且彼此之间几乎没有相似之处。我们创造了一种可变形的、难以抓握的、反射性的和需要高精度的小物体的混合。图3a显示了用于实验的一组对象
C:对抗测试物品
另一个包含10个复杂几何对抗对象的集合被用来评估我们所提出的系统的精度。这些3D打印的物体具有不确定的表面和边缘的抽象几何,难以感知和把握。每一个物体都被单独测试了10个不同的方向和位置,总共有100次抓握尝试。图3b显示了实验中使用的对抗对象。

D:杂乱的对象
工业应用程序(如仓库)要求对象能够从杂乱中分离出来。因此,为了在杂乱的物体上进行实验,我们用60个看不见的物体进行了10次运行。每次运行都有一组不同的对象,这些对象都是从之前未见过的新对象中挑选出来的,从而创造出一个混乱的场景。这方面的一个例子如图5所示。当相机的视野中没有物体时,每次运行都会终止。
Ⅶ. RESULTS
在本节中,我们将讨论我们的实验结果。我们在Cornell和Jacquard数据集上评估GR-ConvNet,根据数据集的大小、训练数据的类型等因素检查每个数据集的结果,并展示我们的模型对任何类型的对象进行泛化的能力。此外,我们还证明了我们的模型不仅能够为孤立的对象生成单个抓取,而且能够为杂乱环境中的多个对象生成多个抓取。
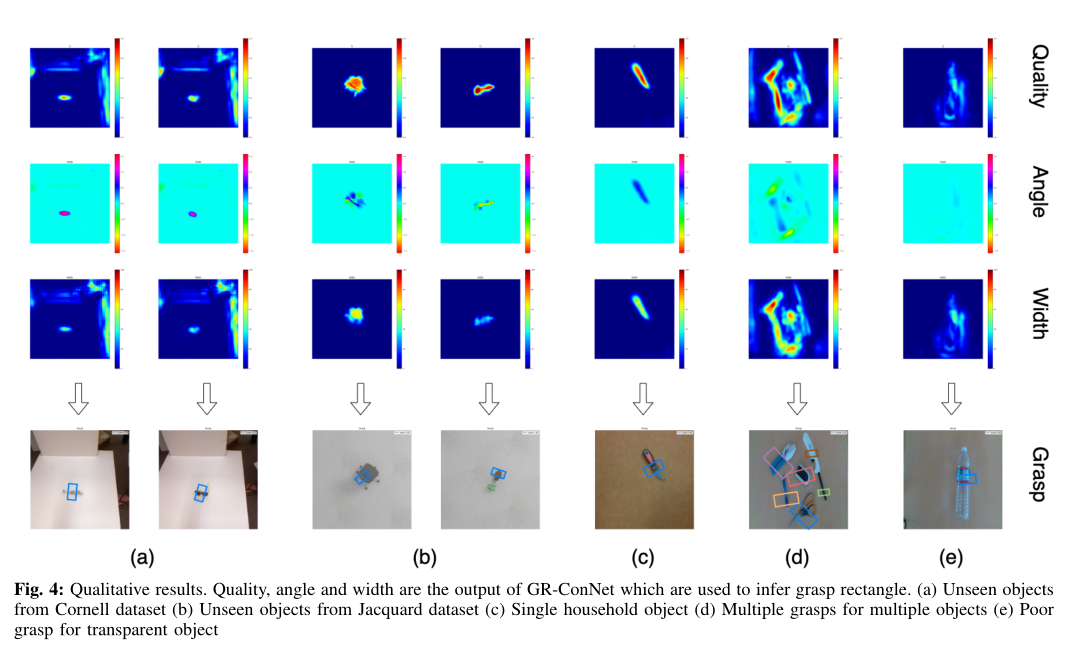
图4显示了在以前看不见的物体上获得的定性结果。图的输出以图像Gi表示,Gi由抓取质量分数Q、抓取所需角度(sita),和夹取器宽度Wi。它还包括以矩形抓取表示形式的输出投影到RGB图像上。
此外,通过测量网络在不同类型对象上的性能,我们通过与其他方法的比较,证明了我们方法的可行性。此外,我们评估我们的网络在不同输入模式下的性能。模型所测试的模式包括单模态,如只包含深度和只包含RGB输入图像,以及RGB-D图像等多模态输入。表三显示,与单模态数据相比,我们的网络在多模态的数据上表现更好,因为多种输入模式能够更好地学习输入特征。
A. Cornell Dataset
我们按照前面的工作[1]、[2]、[4]、[23]、[16]中的交叉验证设置,使用图像方式(IW)和对象方式(OW)数据分割。表三显示了我们的系统在多种模式下的性能,并与其他用于抓取预测的技术进行了比较。使用RGB-D数据,我们获得了最先进的图像分割准确率为97.7%,对象分割准确率为96.6%,优于所有竞争方法,如表三所示。在数据集中之前未见过的对象上获得的结果表明,我们的网络可以预测验证集中不同类型的对象的鲁棒抓取。在康奈尔抓取数据集上进行的数据扩充提高了网络的整体性能。此外,记录的预测速度为20ms表明GR-ConvNet适用于实时闭环应用。
B.Jacquard Dataset
对于Jacquard数据集,我们在90%的数据集图像上训练我们的网络,并在剩余数据集的10%上进行验证。因为Jacquard数据集比Cornell数据集大得多,所以不需要增加数据。我们在Jacquard数据集上使用多种模式进行实验,以RGB-D数据作为输入,获得了最先进的结果,精度为94.6%。从表四可以看出,我们的网络不仅在Cornell抓取数据集上得到了最好的结果,而且在Jacquard数据集上也优于其他方法。

C. 抓取从未见过的目标物体
在两个标准数据集上的最先进的结果,我们也证明了我们的系统在新的真实世界的机器人抓取实验中同样表现出色。我们使用了35个家用物体和10个对抗物体来评估我们的系统在物理世界中使用百特机械臂的性能。每个物体都被测试了10个不同的位置和方向。在家用物体的350次抓取尝试中,机器人成功抓取334次,准确率为95.4%;在对抗物体的100次抓取尝试中,机器人成功抓取93次,准确率为93%。表V显示了我们与其他基于深度学习的机器人抓取方法的比较结果。从表V和图4中得到的结果表明,GRConvNet能够很好地推广到它以前从未见过的新对象。该模型能够生成所有物体的抓手,除了一个透明的瓶子。
D.杂乱环境中的目标物体
在预测新的真实目标的最佳抓取的同时,我们的鲁棒模型能够预测杂波中多个目标的多次对跖抓取。每次运行都进行了物体替换和不进行物体替换,通过在每次运行中每次成功的抓取尝试的平均抓取成功,我们获得了93.5%的抓取成功。尽管该模型只对孤立的物体进行训练,但它能够有效地预测多种物体的抓取情况。此外,图4(d)为多目标预测抓取,图5为杂乱环境下机器人抓取家庭和对抗对象。这表明GR-ConvNet可以推广到所有类型的物体,并可以预测杂波中多个物体的鲁棒抓取

E. 失败案例分析
在我们的实验结果中,只有少数情况可以算作失败。其中,掌握分数极低的对象和那些从夹持器被关闭时滑落的是最常见的。这可能是由于来自相机的不准确的深度信息和夹持器与附近物体的碰撞导致的夹持器不对准。
另一个模型不能很好把握的例子是透明瓶,如图4(e)所示。这可能是由于由于物体的反射,相机捕捉到的深度数据不准确。然而,通过结合深度数据和RGB数据,模型仍然能够很好地把握透明对象。
Ⅷ. CONCLUSION
我们提出了一个模块化的解决方案,以抓取新的目标使用我们的生成残差卷积神经网络它使用n通道输入数据生成图像,可用于推断图像中每个像素的抓取矩形。我们在两个标准数据集上评估了GR-ConvNet, Cornell抓取数据集和Jacquard数据集,并在这两个数据集上获得了最先进的结果。我们也使用机械臂在杂波中的新真实物体上验证了所提出的系统。结果表明,我们的系统可以预测和执行准确的抓取之前看不见的物体。此外,该模型推理时间短,适合于闭环机器人抓取。在未来的工作中,我们希望将我们的解决方案扩展到不同类型的夹持器,如单、多吸盘和多指夹持器。我们也希望利用深度预测技术来准确预测反射物体的深度,这有助于提高对瓶子等反射物体的抓握预测精度。

