机器学习数据处理时label错位对未来数据做预测
这篇文章继上篇机器学习经典模型简单使用及归一化(标准化)影响,通过将测试集label(行)错位,将部分数据作为对未来的预测,观察其效果。
实验方式
- 以不同方式划分数据集和测试集
- 使用不同的归一化(标准化)方式
- 使用不同的模型
- 将测试集label错位,计算出MSE的大小
- 不断增大错位的数据的个数,并计算出MSE,并画图
- 通过比较MSE(均方误差,mean-square error)的大小来得出结论
过程及结果
数据预处理部分与上次相同。两种划分方式:
一、
test_sort_data = sort_data[16160:] test_sort_target = sort_target[16160:] _sort_data = sort_data[:16160] _sort_target = sort_target[:16160] sort_data1 = _sort_data[:(int)(len(_sort_data)*0.75)] sort_data2 = _sort_data[(int)(len(_sort_data)*0.75):] sort_target1 = _sort_target[:(int)(len(_sort_target)*0.75)] sort_target2 = _sort_target[(int)(len(_sort_target)*0.75):]
二、
test_sort_data = sort_data[:5000] test_sort_target = sort_target[:5000] sort_data1 = _sort_data[5000:16060] sort_data2 = _sort_data[16060:] sort_target1 = _sort_target[5000:16060] sort_target2 = _sort_target[16060:]
一开始用的第一种划分方式,发现直接跑飞了

然后仔细想了想,观察了上篇博客跑出来的数据,果断换了第二种划分方式,发现跑出来的结果还不错
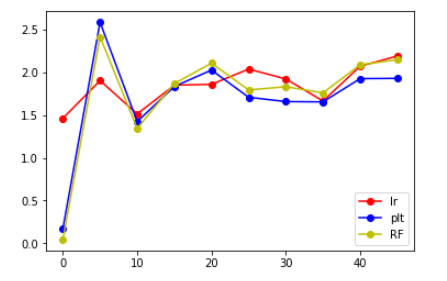
MaxMinScaler()
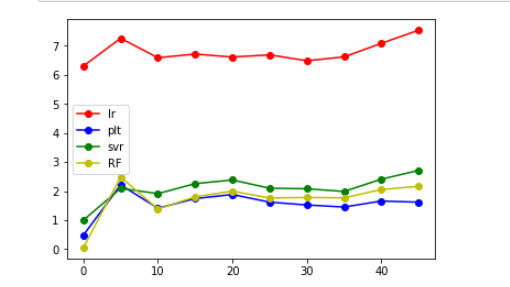
看到lr模型明显要大,就舍弃了
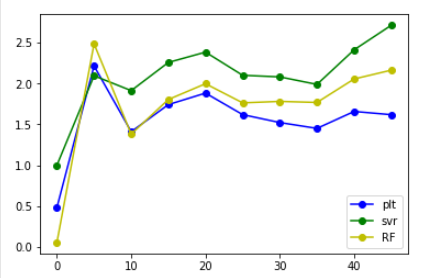
(emmmmm。。。这张图看起来就友好很多了)
MaxAbsScaler()

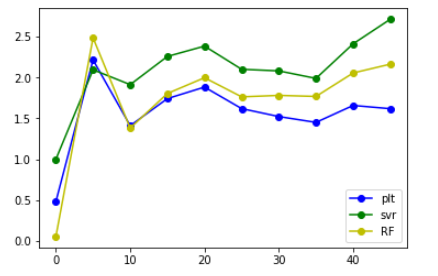
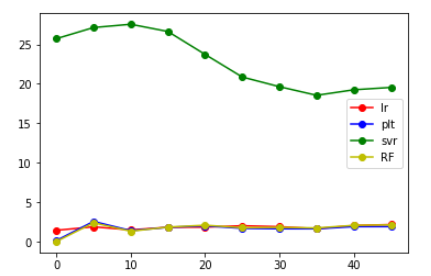
StandardScaler()
代码
其中大部分的代码都是一样的,就是改改归一化方式,就只放一部分了
数据预处理部分见上篇博客
加上这一段用于画图
import matplotlib.pyplot as plt lr_plt=[] ridge_plt=[] svr_plt=[] RF_plt=[]
接着,先计算不改变label时的值
from sklearn.linear_model import LinearRegression,Lasso,Ridge from sklearn.preprocessing import MinMaxScaler,StandardScaler,MaxAbsScaler from sklearn.metrics import mean_squared_error as mse from sklearn.svm import SVR from sklearn.ensemble import RandomForestRegressor import xgboost as xgb #最大最小归一化 mm = MinMaxScaler() lr = Lasso(alpha=0.5) lr.fit(mm.fit_transform(sort_data1[new_fea]), sort_target1) lr_ans = lr.predict(mm.transform(sort_data2[new_fea])) lr_mse=mse(lr_ans,sort_target2) lr_plt.append(lr_mse) print('lr:',lr_mse) ridge = Ridge(alpha=0.5) ridge.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1) ridge_ans = ridge.predict(mm.transform(sort_data2[new_fea])) ridge_mse=mse(ridge_ans,sort_target2) ridge_plt.append(ridge_mse) print('ridge:',ridge_mse) svr = SVR(kernel='rbf',C=100,epsilon=0.1).fit(mm.fit_transform(sort_data1[new_fea]),sort_target1) svr_ans = svr.predict(mm.transform(sort_data2[new_fea])) svr_mse=mse(svr_ans,sort_target2) svr_plt.append(svr_mse) print('svr:',svr_mse) estimator_RF = RandomForestRegressor().fit(mm.fit_transform(sort_data1[new_fea]),sort_target1) predict_RF = estimator_RF.predict(mm.transform(sort_data2[new_fea])) RF_mse=mse(predict_RF,sort_target2) RF_plt.append(RF_mse) print('RF:',RF_mse) bst = xgb.XGBRegressor(learning_rate=0.1, n_estimators=550, max_depth=4, min_child_weight=5, seed=0, subsample=0.7, colsample_bytree=0.7, gamma=0.1, reg_alpha=1, reg_lambda=1) bst.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1) bst_ans = bst.predict(mm.transform(sort_data2[new_fea])) print('bst:',mse(bst_ans,sort_target2))
先将label错位,使得data2的第i位对应target2的第i+5位
change_sort_data2 = sort_data2.shift(periods=5,axis=0) change_sort_target2 = sort_target2.shift(periods=-5,axis=0) change_sort_data2.dropna(inplace=True) change_sort_target2.dropna(inplace=True)
然后用一个循环不断迭代,改变错位的数量
mm = MinMaxScaler() for i in range(0,45,5): print(i) lr = Lasso(alpha=0.5) lr.fit(mm.fit_transform(sort_data1[new_fea]), sort_target1) lr_ans = lr.predict(mm.transform(change_sort_data2[new_fea])) lr_mse=mse(lr_ans,change_sort_target2) lr_plt.append(lr_mse) print('lr:',lr_mse) ridge = Ridge(alpha=0.5) ridge.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1) ridge_ans = ridge.predict(mm.transform(change_sort_data2[new_fea])) ridge_mse=mse(ridge_ans,change_sort_target2) ridge_plt.append(ridge_mse) print('ridge:',ridge_mse) svr = SVR(kernel='rbf',C=100,epsilon=0.1).fit(mm.fit_transform(sort_data1[new_fea]),sort_target1) svr_ans = svr.predict(mm.transform(change_sort_data2[new_fea])) svr_mse=mse(svr_ans,change_sort_target2) svr_plt.append(svr_mse) print('svr:',svr_mse) estimator_RF = RandomForestRegressor().fit(mm.fit_transform(sort_data1[new_fea]),sort_target1) predict_RF = estimator_RF.predict(mm.transform(change_sort_data2[new_fea])) RF_mse=mse(predict_RF,change_sort_target2) RF_plt.append(RF_mse) print('RF:',RF_mse) # bst = xgb.XGBRegressor(learning_rate=0.1, n_estimators=550, max_depth=4, min_child_weight=5, seed=0, # subsample=0.7, colsample_bytree=0.7, gamma=0.1, reg_alpha=1, reg_lambda=1) # bst.fit(mm.fit_transform(sort_data1[new_fea]),sort_target1) # bst_ans = bst.predict(mm.transform(change_sort_data2[new_fea])) # print('bst:',mse(bst_ans,change_sort_target2)) change_sort_target2=change_sort_target2.shift(periods=-5,axis=0) change_sort_target2.dropna(inplace=True) change_sort_data2 = change_sort_data2.shift(periods=5,axis=0) change_sort_data2.dropna(inplace=True)
然后就可以画图了
x=[0,5,10,15,20,25,30,35,40,45] plt.plot(x,lr_plt,label='lr',color='r',marker='o') plt.plot(x,ridge_plt,label='plt',color='b',marker='o') plt.plot(x,svr_plt,label='svr',color='g',marker='o') plt.plot(x,RF_plt,label='RF',color='y',marker='o') plt.legend() plt.show()
结果分析
从上面给出的图来看,发现将label错位后,相比于原来的大小还是有所增大,但是增大后的值并不是特别大,并且大致在某个范围内浮动,大概在错位10个label时能得到的结果是最好的。

