Reinforcement Learning 的那点事——强化学习(一)
引言
最近实验室的项目需要用到强化学习的有关内容,就开始学习起强化学习了,这里准备将学习的一些内容记录下来,作为笔记,方便日后忘记了好再方便熟悉,也可供大家参考。该篇为强化学习开篇文章,主要概括一些有关强化学习的内容,以帮助了解什么是强化学习,以及学习方向,部分涉及到的内容将会在后面的篇章中展开详细的叙述。推荐课程(Utubu上的,需FQ),B站上也有。
基础概念和实际运用
定义
首先先看一段定义:Reinforcement learning is learning what to do—how to map situations to actions—so as to maximize a numerical reward signal。感觉看英文的定义很容易可以了解什么叫强化学习。
应用领域
再来看看强化学习在整个科学领域的应用范围。

从图中可以看出,众多学科都与强化学习有关,增强学习本质上是一门决策学科,通过理解最佳的方式来制定决策。决策科学在计算机科学领域,体现为机器学习,尤其是强化学习;在工程领域,最优控制的实现与强化学习有关联;神经科学领域最主要的是研究人类大脑如何做出决策,提出多巴胺系统(前段时间谷歌开源了一个强化学习的框架就叫多巴胺),在强化学习中的运用体现为奖励系统;在心理学领域,也存在类似于神经科学领域的东西,传统的条件作用以及条件反射实验探究动物面对事物是如何做出反应,以及为什么会做出这种反应;在数学方面,可以用一个等价的公式来表示强化学习,可用于研究最优控制,也被称为运筹学;在经济学中,博弈论,效用理论以及有限性理的运用,也都是研究人类如何以及为什么做出决定,并使这些决定的效用最大化。这些都涉及到上述的强化学习的本质。
强化学习、监督学习、无监督学习
What makes reinforcement learning different from other machine learning paradigms?
1、There is no supervisor, only a reward signal. 一个显而易见的地方是进行强化学习训练的时候并不存在监督者,没有人会告诉你,什么行为是正确的。那么强化学习的训练是通过什么方式进行的呢?强化学习的训练类似于小孩不断试错的过程,会创建一个agent,没有监督者,但是有奖励信号,根据奖励信号就可以知道什么是对什么是错,但并不知道采取什么措施才是最好。
2、Feedback is delayed, not instantaneous. 第二个区别是强化学习的反馈并不是立刻得到的,可能会有很大的延迟,因此,在强化学习中,做出的一步决策可能需要在经历很多步之后才能知道这个决策是正确的还是错误的。
3、Time really matters. 另外,在强化学习的过程中,时间很重要,我们是一步一步的进行的,即agent通过采取相应的措施来制定决策,并计算采取措施后会得到多少奖励,然后agent会尝试修改决策,使得最终的结果尽可能的好。而这一过程,我们不是在讨论独立分布的数据,不像传统的监督学习或非监督学习环境那样,只需将独立分布的数据丢给机器,让机器自己学习就行了。在这里,我们面对的是一个动态的系统,agent要和外部环境进行交互,它的每步举措都会影响下一步的行动,agent会根据环境的影响来采取措施,应对环境的变化。
4、Agent’s actions affect the subsequent data it receives.
举几个栗子
光说概念肯定会觉得没意思,下面将通过几个已经实现的例子来让你对强化学习有更好的理解。
一、直升机的飞行特技表演:通过奖励函数,来告知直升飞机什么是好什么是坏,然后直升飞机去执行那些特技。
二、backgammon游戏
三、处理投资组合
四、控制发电站
五、人形机器人行走
不知道你会不会有个疑问,我之前就存在这个疑问,agent的每次测试是会记住之前的路线,还是重新开始?事实上每次都是重新开始。
上述的几个例子在训练过程中都离不开一个东西——Rewards(奖励)。那么,什么是奖励呢?如何定义奖励?
所谓奖励,它仅仅是一个数字,一个标量的反馈信号,我们用随机变量Rt表示,即每一步T对应一个反馈信号Rt,表明agent每一步做的怎么样,然后将每一步获得的Rewards加起来,最终获得一个结果。agent的目标就是使这一结果达到最大。当然,我们可能不仅仅只有这一种方法来训练agent,但是,这个方法无疑是适用于解决各种各样问题的。强化学习都遵循这么一种假设的模型 All goals can be described by the maximisation of expected cumulative reward. 因此可以笼统的将强化学习概括为累计求最大化的问题,我们可以通过标量反馈信号来求出最大值。
对于奖励的定义,比如上面说的直升飞机的特技表演,每当飞机飞行轨迹或者转圈半径符合我们的期望时,就会得到一个正向的奖励,当飞机坠毁时就会得到一个巨大的惩罚。当玩backgammon的时候,胜利了就获得正向奖励,这样agent就会自己寻找获取最大化奖励的方式,让agent尝试不同的决策,以期望在最后获取最大的奖励。对于投资组合问题,奖励信号就是钱,最终利润越大自然越好。对于发电站调控问题,每当产生一单元的电力的时候就获得正向奖励,发电量超过安全上限或是调控不符合预期就获得负向奖励。对于机器人行走,每向前移动一步,就可以获取一个正向的奖励单位,摔倒的时候就获得负向的奖励。
上述的问题都是不同的,乍一看并不存在一个框架适用于所有的这些问题,但我们的目标就是建立统一的框架,使用机器学习的方法,或是用相同的形式应对各种各样不同的问题,因此,解决这些问题只需要使用相同的agents,相同的想法。
需要指出的是,我们需要提前计划,考虑未来。因为此时的行动的影响可能是长期的,可能现在不是我们想要的结果,但经过了几步之后就变成了想要的结果了。这也就意味着现在需要放弃一些好的奖励,而在不久的未来则会得到更高的奖励(更经典算法里的贪心有些相反)。例如金融投资问题,直升机表演时加油的问题等
大致的训练过程如下图
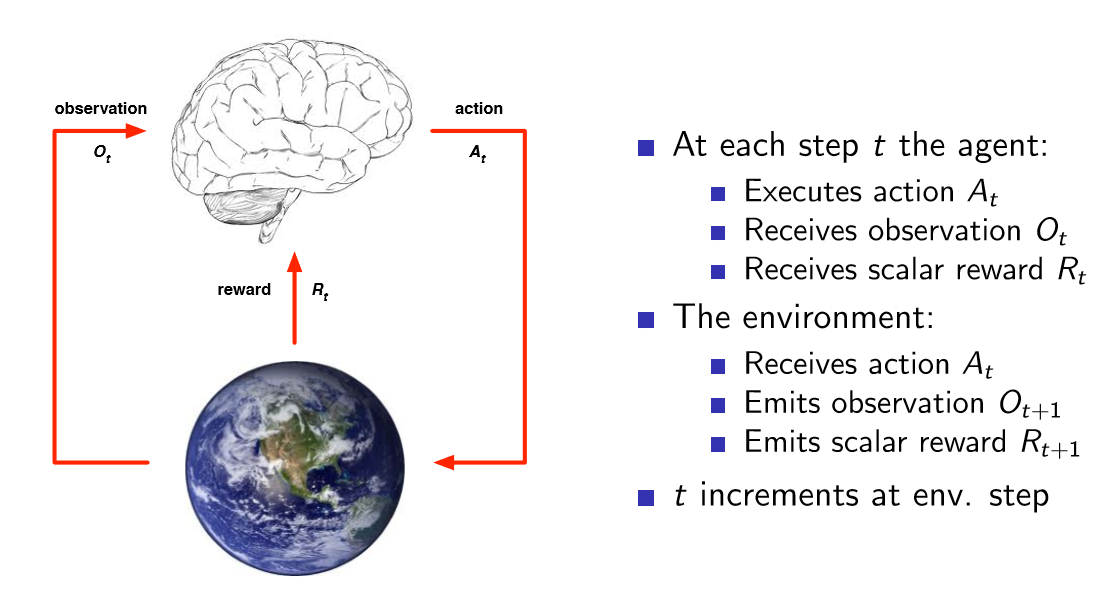
我们在大脑中创建一个算法即agent,然后再根据周围的环境的影响以及agent的决策,不断进行调整,最终达到目的。
再来几个概念
History
agent在训练时,一系列的选项序列,观察,行动,奖励,称为history,即agent目前所知道的东西。每一步agent都会采取行动,进行观察,获取奖励一直到第T步,所有的这些过程组成了history,即Ht。
Ht = O1,R1,A1,...,At−1,Ot,Rt
后面会发生什么,实际上都取决于history,agent实际上事从history到action的映射,因此,我们的目标就是创建一个映射,算法就是从一个history到下一个action的映射,所以agent接下来的action完全依赖于history。
State
然而,history并不是很有用,因为它通常会很巨大,而我们希望agents可以活的更久,可以在很短时间内进行交互,因此,我们要研究的是state,state是对信息的总结,state决定下一步的action,即state包含了我们需要的所有信息,通过这些信息,我们就可以采取下一步的action。
那么,什么是state呢?每经历一个时间步长T,我们就构建一个状态,它是关于history的函数,
表示为 St=f(Ht)
因为state只是关于history的函数,所以state只有经过最后一次观测才能使合理有效的。
再来讲讲state的种类
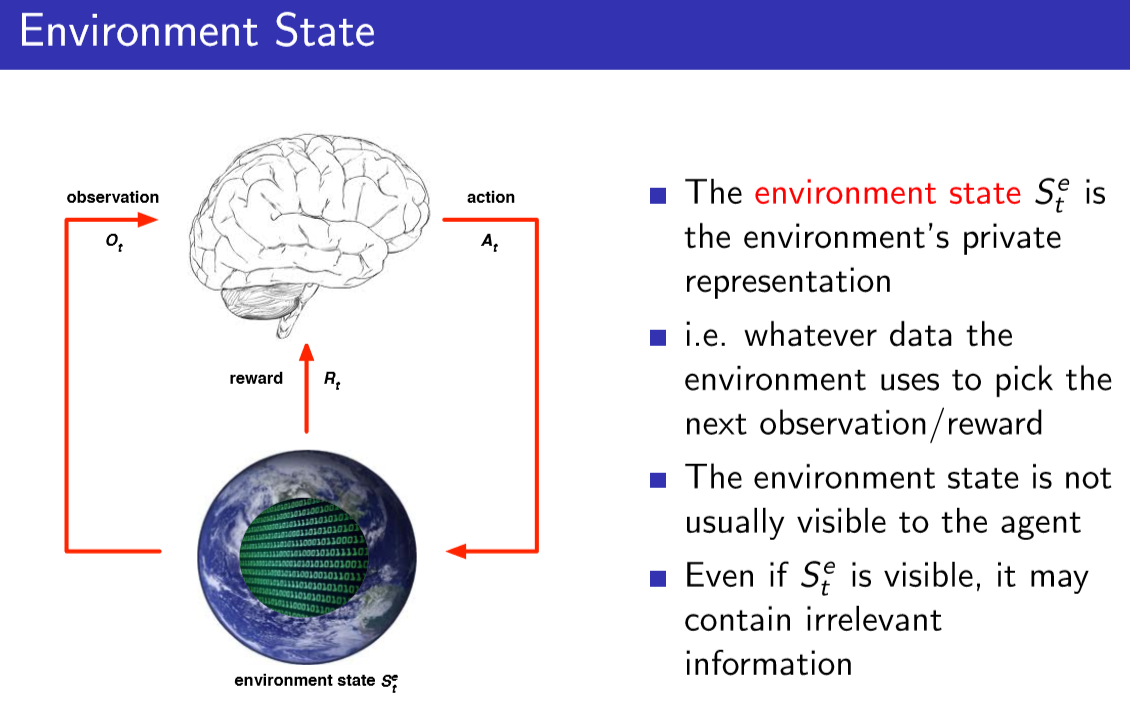
1.Environment State:agent所处环境中的信息决定接下来会发生什么,例如,机器人在和真实的环境进行交互,真实的环境可以抽象为某些数字的集合,这些数字决定了接下来会发生什么;或者说一个Atria模拟器,模拟器内有一些内置的状态,这些状态决定了模拟器下一步的行动。也就是基于目前所知道的东西,由某种数字集合决定了接下来会发生什么事情会存在某种状态来代表此时的所有已知东西,该状态在下一次观测与奖励的时候,又会被重新拆分。但是关于环境,我们需要特别注意的是,环境的状态对于agents并非总是可见的。
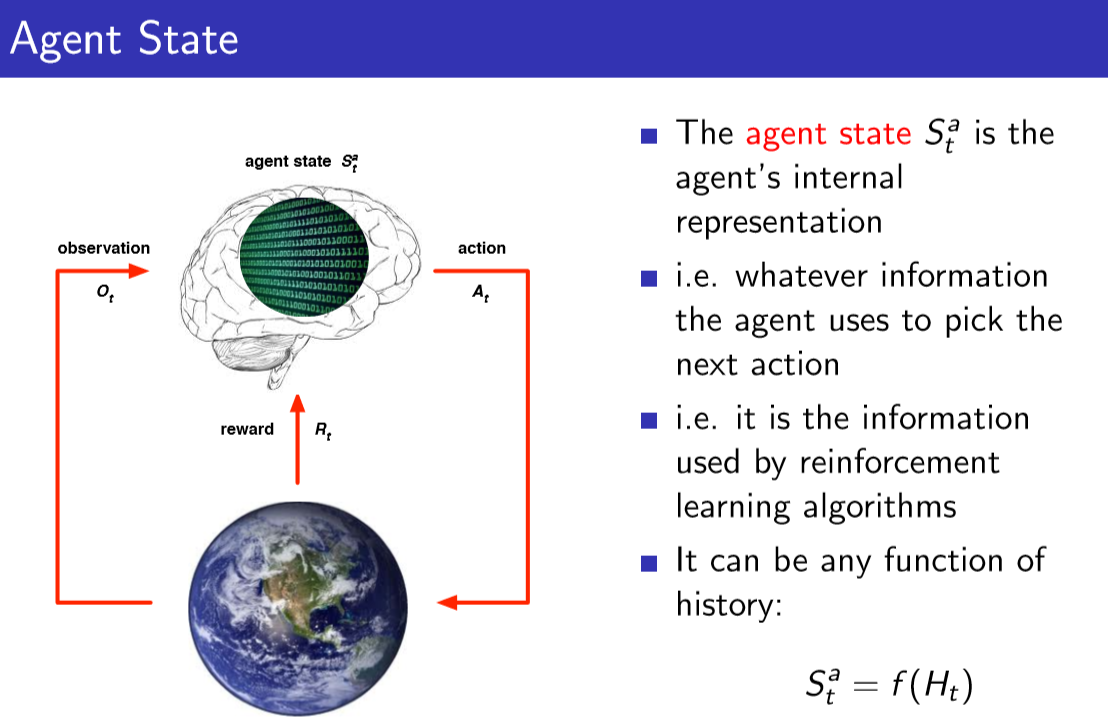
2.agent state:agent state也是数字的集合,这个集合存在于我们的算法当中,通过算法,我们可以使用某个数字的集合,来表示agent目前得到了什么,接下来该采取的action。无论储存什么信息,捕获什么信息,我们都能用agent状态来决定下一步的action。要做的action就是如何处理这些观测信息,应该记住什么,抛弃什么。在创建算法时,我们经常要讨论agent的状态,通过agent的状态来挑选下一步的行动。
3、信息状态:我们有时候将信息状态称之为Markov状态,在我们使用状态表示法的时候,这些state包含history的全部有用信息,我们需要做的就是定义某个具有Markov性质的东西。Markov的定义:A state St is Markov if and only if P[St+1 | St] = P[St+1 | S1,...,St],即下一时刻的状态仅由当前状态决定,与过去的状态并没有太大的关系,换句话说我们只需保留当前状态。例如之前说过的直升飞机表演的例子,我们会有一个标记,表示直升机当前的位置、速度、角速度、角位置等,而10分钟前的标记对于下一刻的action肯定是没有任何影响的,我们只需要关注当前直升飞机的状态即可。

agent
上面讲了那么多,但都只是讲了强化学习中的问题,并没有涉及解决这些问题的方法。现在将谈谈强化学习中的agent。agent大概包含三个函数(当然,并不是所有的agent都要用到):Policy、Value、Model。
Policy:表明agent能够采取的行动,是一个行为函数,以状态作为输入,下一步的决策作为输出。
Value:该函数用来评价agent大某种特殊状态下的好坏,采取某种行动之后的好坏。
Model:用来感知环境如何变化,这里环境指的是agent眼里的环境。
在强化学习中,agent间最主要的不同之处就是有无Model,没有Model,就意味着我们不会尝试去理解环境。相反的是,使用policy和value,根据经验找到最优策略。而对于有Model的强化学习模型,第一步是建立一个model来表示环境的工作原理,通过这个model知道接下来会发生什么,并找到最优策略。
几个问题
一、之前说过奖励是有延时的,那么该怎么使用增强学习的方法呢?
我们会定义一个目标事件,确定一个阶段的开始与结束,然后为这个阶段定义奖励,事实上奖励只会在每个阶段结束的时候出现,agent的目标就是在一个阶段中采取措施,在阶段结束的时刻得到最大化的奖励。
二、如果我们的目标是基于时间的,即我们的目标是最短的时间来做某件事,我们该怎么做?
一般做法是每经历一个时间步长,都会有一个值为-1的奖励信号,完成目标后就会停下来,总奖励就是耗费的时间,此时我们就有两个目标,一是最大化积累的奖励,二是最短时间达到目标。
三、有时候会有不同的目标,且目标相互冲突,对于冲突情况该怎么考虑,比如你该去见你的老板(老师)还是女朋友(当然对我来说是不存在的,没有女朋友....)?
这时候标量的反馈信号足以处理所有的目标了,我们需要给不同的目标赋予不同的权重值,这样我们的agent才能挑选措施采取行动。

