写一手漂亮的代码,走向极致的编程 二、代码运行时内存分析
前言
上篇文章中介绍了如何对代码性能进行分析优化,这篇文章将介绍如何对代码运行时内存进行分析。
说到内存,就想起之前在搞数据挖掘竞赛的时候,往往要跑很大的数据集,经常就是炸内存。当时的解决办法就是对着任务管理器用 jupyter notebook 分 cell 的跑代码,将需要耗费大量内存的代码块找出来,然后考虑各种方式进行优化。
这篇文章将会介绍些更好的方法,来对代码运行时内存进行分析,通过这些方法了解了代码的内存使用情况之后,我们可以思考:
- 能不能重写这个函数让它使用更少的 RAM 来工作得更有效率
- 我们能不能使用更多的 RAM 缓存来节省 CPU 时间
开始分析
代码仍采用上篇文章中的
memory_profiler
通过 pip install memory_profiler 来安装这个库。在需要进行分析的函数前加上修饰器 @profile
from memory_profiler import profile
...
...
@profile
def calculate_z_serial_purepython(maxiter, zs, cs):
...
@profile
def calc_pure_python(desired_width, max_itertions):
...
...
然后命令行输入
python -m memory_profiler code_memory.py
跑得十分的慢 - -,跑了一个多小时,输出如下
Length of x: 1000
Total elements: 1000000
Filename: code_memory.py
Line # Mem usage Increment Line Contents
================================================
30 159.1 MiB 159.1 MiB @profile
31 def calculate_z_serial_purepython(maxiter, zs, cs):
32 166.7 MiB 7.6 MiB output = [0] * len(zs)
33 166.7 MiB 0.0 MiB for i in range(len(zs)):
34 166.7 MiB 0.0 MiB n = 0
35 166.7 MiB 0.0 MiB z = zs[i]
36 166.7 MiB 0.0 MiB c = cs[i]
37 166.7 MiB 0.0 MiB while n < maxiter and abs(z) < 2:
38 166.7 MiB 0.0 MiB z = z * z + c
39 166.7 MiB 0.0 MiB n += 1
40 166.7 MiB 0.0 MiB output[i] = n
41 108.3 MiB 0.0 MiB return output
calculate_z_serial_purepython took 8583.605925321579 seconds
Filename: code_memory.py
Line # Mem usage Increment Line Contents
================================================
43 80.9 MiB 80.9 MiB @profile
44 def calc_pure_python(desired_width, max_itertions):
45 80.9 MiB 0.0 MiB x_step = (float(x2 - x1)) / float(desired_width)
46 80.9 MiB 0.0 MiB y_step = (float(y2 - y1)) / float(desired_width)
47 80.9 MiB 0.0 MiB x, y = [], []
48 80.9 MiB 0.0 MiB ycoord = y1
49 80.9 MiB 0.0 MiB while ycoord < y2:
50 80.9 MiB 0.0 MiB y.append(ycoord)
51 80.9 MiB 0.0 MiB ycoord += y_step
52 80.9 MiB 0.0 MiB xcoord = x1
53 80.9 MiB 0.0 MiB while xcoord < x2:
54 80.9 MiB 0.0 MiB x.append(xcoord)
55 80.9 MiB 0.0 MiB xcoord += x_step
56 80.9 MiB 0.0 MiB zs, cs = [], []
57 159.1 MiB 0.0 MiB for ycoord in y:
58 159.1 MiB 0.1 MiB for xcoord in x:
59 159.1 MiB 0.9 MiB zs.append(complex(xcoord, ycoord))
60 159.1 MiB 0.1 MiB cs.append(complex(c_real, c_imag))
61 159.1 MiB 0.0 MiB print(f"Length of x: {len(x)}")
62 159.1 MiB 0.0 MiB print(f"Total elements: {len(zs)}")
63 159.1 MiB 0.0 MiB start_time = time.time()
64 108.6 MiB 0.0 MiB output = calculate_z_serial_purepython(max_itertions, zs, cs)
65 108.6 MiB 0.0 MiB end_time = time.time()
66 108.6 MiB 0.0 MiB secs = end_time - start_time
67 108.6 MiB 0.0 MiB print("calculate_z_serial_purepython took", secs, "seconds")
68
69 108.6 MiB 0.0 MiB assert sum(output) == 33219980
可以看到:
- 第 32 行,可以看到分配了 1000000 个项目,导致大约 7M 的 RAM 被加入这个进程
- 在 57 行的父进程中,可以看到 zs 和 cs 列表的分配占用了大约 70M。
注:这里的的数字并不一定是数组的真实大小,只是进程在创建这些列表的过程中增长的大小
mprof
在 memory_profiler 库中,还有一种通过随时间进行采样并画图的方式来展示内存使用变化,叫 mprof。
记得把 @profile 注释掉
mprof run code_memory.py
运行结束后会有一个 .dat 文件,接着命令行输入
mprof plot
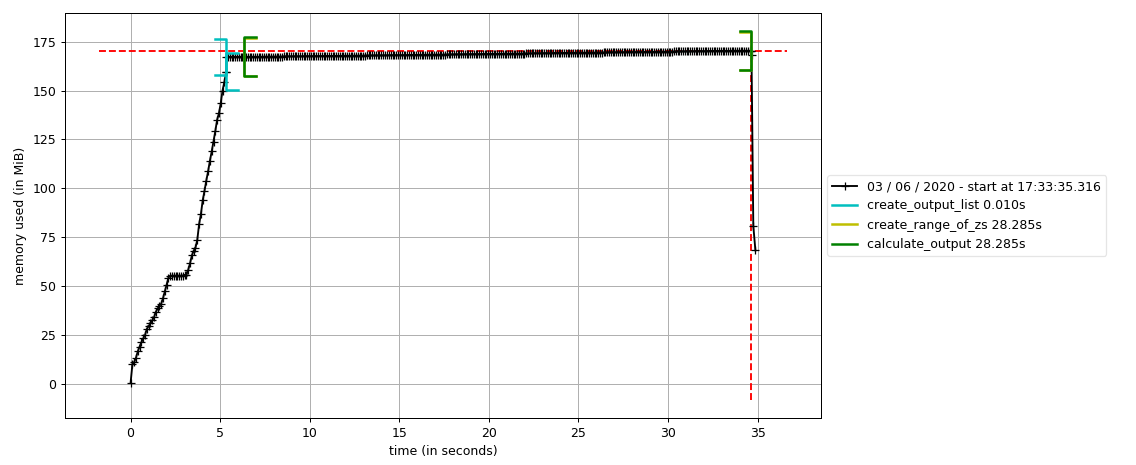
生成图片

这个图看起来好像还不是很直观,并不能看出内存增长是在哪里,修改下函数,这里还要把 from memory_profiler import profile 注释掉
def calculate_z_serial_purepython(maxiter, zs, cs):
with profile.timestamp("create_output_list"):
output = [0] * len(zs)
time.sleep(1)
with profile.timestamp("create_range_of_zs"):
iterations = range(len(zs))
with profile.timestamp('calculate_output'):
for i in iterations:
n = 0
z = zs[i]
c = cs[i]
while n < maxiter and abs(z) < 2:
z = z * z + c
n += 1
output[i] = n
return output
然后命令行
mprof run code_memory.py
画图
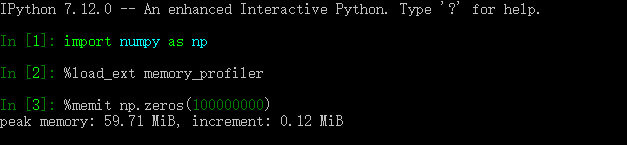
memit
类似于运行时间测量的 timeit,内存测量中也有 memit,可在 ipython 或 jupyter notebook 中使用
heapy 调查堆上对象
当需要知道某一时刻有多少对象被使用,以及他们是否被垃圾收集时,通过对堆的查看,可以很好的得到结果。
安装
pip install guppy3
代码修改如下
import time
import numpy as np
# import imageio
# import PIL
# import matplotlib.pyplot as plt
from guppy import hpy
# import cv2 as cv
from functools import wraps
x1, x2, y1, y2 = -1.8, 1.8, -1.8, 1.8
c_real, c_imag = -0.62772, -0.42193
def timefn(fn):
@wraps(fn)
def measure_time(*args, **kwargs):
t1 = time.time()
result = fn(*args, **kwargs)
t2 = time.time()
print("@timefn:" + fn.__name__ + " took " + str(t2 - t1), " seconds")
return result
return measure_time
def calculate_z_serial_purepython(maxiter, zs, cs):
output = [0] * len(zs)
for i in range(len(zs)):
n = 0
z = zs[i]
c = cs[i]
while n < maxiter and abs(z) < 2:
z = z * z + c
n += 1
output[i] = n
return output
def calc_pure_python(desired_width, max_itertions):
x_step = (float(x2 - x1)) / float(desired_width)
y_step = (float(y2 - y1)) / float(desired_width)
x, y = [], []
ycoord = y1
while ycoord < y2:
y.append(ycoord)
ycoord += y_step
xcoord = x1
while xcoord < x2:
x.append(xcoord)
xcoord += x_step
print("heapy after creating y and x lists of floats")
hp = hpy()
h = hp.heap()
print(h)
print("")
zs, cs = [], []
for ycoord in y:
for xcoord in x:
zs.append(complex(xcoord, ycoord))
cs.append(complex(c_real, c_imag))
print("heapy after creating zs and cs using complex numbers")
h = hp.heap()
print(h)
print("")
print(f"Length of x: {len(x)}")
print(f"Total elements: {len(zs)}")
start_time = time.time()
output = calculate_z_serial_purepython(max_itertions, zs, cs)
end_time = time.time()
secs = end_time - start_time
print("calculate_z_serial_purepython took", secs, "seconds")
print("")
print("heapy after calling calculate_z_serial_purepython")
h = hp.heap()
print(h)
assert sum(output) == 33219980
if __name__ == "__main__":
calc_pure_python(desired_width=1000, max_itertions=300)
在使用的时候发现不能 import imageio 这个库,不然调用 hp.heap() 的时候会直接退出。。。。
输出
heapy after creating y and x lists of floats
Partition of a set of 96564 objects. Total size = 12355685 bytes.
Index Count % Size % Cumulative % Kind (class / dict of class)
0 27588 29 4021242 33 4021242 33 str
1 25226 26 1920104 16 5941346 48 tuple
2 12595 13 962362 8 6903708 56 bytes
3 6336 7 912831 7 7816539 63 types.CodeType
4 5855 6 796280 6 8612819 70 function
5 922 1 789656 6 9402475 76 type
6 255 0 499248 4 9901723 80 dict of module
7 922 1 496880 4 10398603 84 dict of type
8 514 1 284608 2 10683211 86 set
9 529 1 276160 2 10959371 89 dict (no owner)
<248 more rows. Type e.g. '_.more' to view.>
heapy after creating zs and cs using complex numbers
Partition of a set of 2096566 objects. Total size = 93750677 bytes.
Index Count % Size % Cumulative % Kind (class / dict of class)
0 2000003 95 64000096 68 64000096 68 complex
1 536 0 17495680 19 81495776 87 list
2 27588 1 4021242 4 85517018 91 str
3 25226 1 1920104 2 87437122 93 tuple
4 12595 1 962362 1 88399484 94 bytes
5 6336 0 912831 1 89312315 95 types.CodeType
6 5855 0 796280 1 90108595 96 function
7 922 0 789656 1 90898251 97 type
8 255 0 499248 1 91397499 97 dict of module
9 922 0 496880 1 91894379 98 dict of type
<248 more rows. Type e.g. '_.more' to view.>
Length of x: 1000
Total elements: 1000000
calculate_z_serial_purepython took 24.96058201789856 seconds
heapy after calling calculate_z_serial_purepython
Partition of a set of 2196935 objects. Total size = 104561033 bytes.
Index Count % Size % Cumulative % Kind (class / dict of class)
0 2000003 91 64000096 61 64000096 61 complex
1 537 0 25495744 24 89495840 86 list
2 27588 1 4021242 4 93517082 89 str
3 102343 5 2870796 3 96387878 92 int
4 25226 1 1920104 2 98307982 94 tuple
5 12595 1 962362 1 99270344 95 bytes
6 6336 0 912831 1 100183175 96 types.CodeType
7 5855 0 796280 1 100979455 97 function
8 922 0 789656 1 101769111 97 type
9 255 0 499248 0 102268359 98 dict of module
<248 more rows. Type e.g. '_.more' to view.>
可以发现:
- 在创建了 zs 和 cs 列表后,内存增长了大约 80M, 2000003 个复数对象消耗了 64000096 字节内存,占用了当前大部分的内存。
- 第 3 段中,计算完集合后占用了 104M 的内存,除了之前的复数,现在还保存了大量的整数,列表中的项目也增多了。
hpy.setrelheap() 可以用来创建一个断点,当后续调用 hpy.heap() 时,会产生一个跟这个断点的差额,这样可以略过断点前产生的内存分配。
小节
这篇文章介绍了一些对于代码运行时内存的分析方法,相信通过合理运用这些方法对代码进行分析修改,能写出性能更优的代码。
这是彩蛋
之前在做数据挖掘竞赛的时候,有一个经常使用的分批处理的模板(针对 .csv 数据),就在这里分享给大家
import pandas as pd
import tqdm
data = pd.read_csv(path, iterator=True)
chunk_size = 500000 # 每一批读入数据大小
data_size = 300000 # 采样时用
tmp_df = data.get_chunk(chunk_size).head(data_size)
# 每次读取 chunk_size 大小的数据,迭代 n 次
with tqdm.tqdm(range(n), 'Training..') as t:
for _ in t:
try:
# your code here
except StopIteration:
break

 浙公网安备 33010602011771号
浙公网安备 33010602011771号