机器学习 Logistic 回归
Logistic regression
适用于二分分类的算法,用于估计某事物的可能性。
logistic分布表达式
$ F(x) = P(X<=x)=\frac{1}{1+e^{\frac{-(x-\mu)}{\gamma}}} $
$ f(x) = F{'}(x)=\frac{e{\gamma}}}{\gamma(1+e{\frac{-(x-\mu)}{\gamma}}){2}} $
函数图像
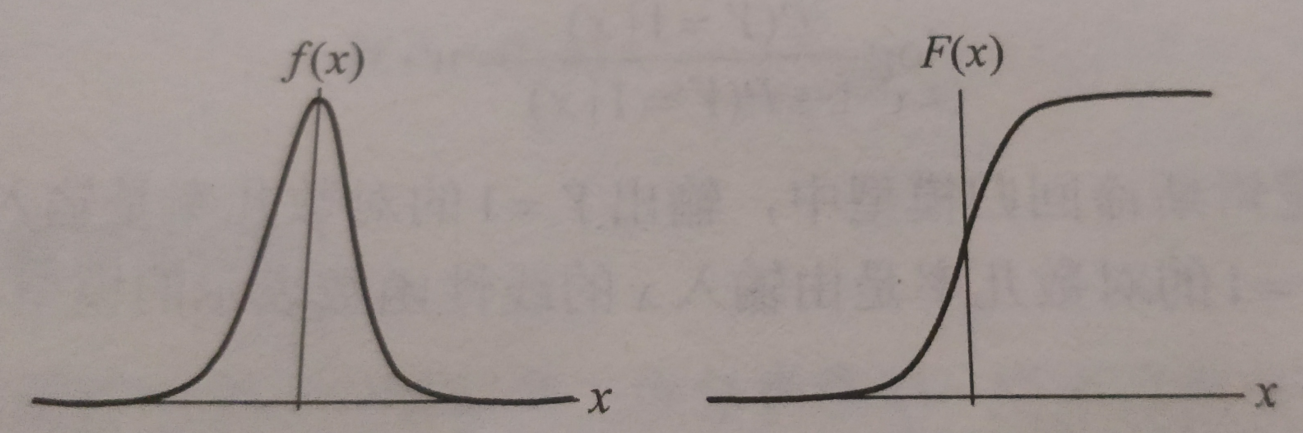
分布函数属于逻辑斯谛函数,以点 \((\mu,\frac{1}{2})\) 为中心对称
逻辑回归是一种学习算法,用于有监督学习问题时,输出y都是0或1。逻辑回归的目标是最小化预测和训练数据之间的误差。
公式推导

代码实现
from math import exp
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
data = np.array(df.iloc[:100, [0, 1, -1]])
return data[:, :2], data[:, -1]
class LogisticRegressionClassifier:
def __init__(self, max_iter=200, learning_rate=0.01, random_state=4):
self.max_iter = max_iter
self.learning_rate = learning_rate
self.weights = None
def sigmoid(self, x):
return 1 / (1 + exp(-x))
def data_matrix(self, X):
data_mat = []
for d in X:
data_mat.append([1.0, *d])
return data_mat
def fit(self, X, y):
data_mat = self.data_matrix(X)
self.weights = np.zeros((len(data_mat[0]), 1), dtype=np.float32)
for iter_ in range(self.max_iter):
for i in range(len(X)):
result = self.sigmoid(np.dot(data_mat[i], self.weights))
error = y[i] - result
self.weights += self.learning_rate * error * np.transpose([data_mat[i]])
print('LogisticRegression Model(learning_rate={},max_iter={})'.format(self.learning_rate, self.max_iter))
def score(self, X_test, y_test):
right = 0
X_test = self.data_matrix(X_test)
for x, y in zip(X_test, y_test):
result = np.dot(x, self.weights)
if (result > 0 and y == 1) or (result < 0 and y == 0):
right += 1
return right / len(X_test)
if __name__ == '__main__':
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
lr_clf = LogisticRegressionClassifier()
lr_clf.fit(X_train, y_train)
print('the score = {}'.format(lr_clf.score(X_test, y_test)))
x_ponits = np.arange(4, 8)
y_ = -(lr_clf.weights[1] * x_ponits + lr_clf.weights[0]) / lr_clf.weights[2]
plt.plot(x_ponits, y_)
# lr_clf.show_graph()
plt.scatter(X[:50, 0], X[:50, 1], label='0')
plt.scatter(X[50:, 0], X[50:, 1], label='1')
plt.legend()
plt.show()
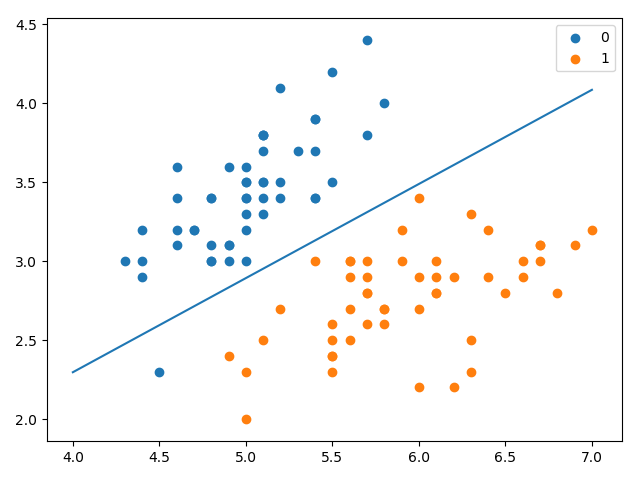
LogisticRegression Model(learning_rate=0.01,max_iter=200)
the score = 0.9666666666666667
sklearn中的logistic regression
sklearn.linear_model.LogisticRegression
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=200, multi_class='warn',
n_jobs=None, penalty='l2', random_state=None, solver='liblinear',
tol=0.0001, verbose=0, warm_start=False)
solver参数决定了我们对逻辑回归损失函数的优化方法,有四种算法可以选择,分别是:
- a) liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
- b) lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- c) newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- d) sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候。
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(max_iter=200,solver='liblinear')
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
print(clf.coef_, clf.intercept_)
输出
0.9666666666666667
[[ 1.96863514 -3.31358598]] [-0.36853861]

