
环境需求: 系统:window 10 eclipse版本:Mars Hadoop版本:2.6.0
资源需求:解压后的Hadoop-2.6.0,原压缩包自行下载:下载地址
丑话前头说:
以下的操作中,eclipse的启动均需要右键“管理员运行”!
在创建MapReduce的Project那块需要配置log4j(级别是debug),否则打印不出一些调试的信息,从而不好找出错的原因。配置这个log4j很简单,大家可以在网上搜索一下,应该可以找得到相关的配置。
1)首先需要利用ant编译自己的Hadoop-eclipse-plugin插件,你也可以自己网上搜索下载,我不喜欢用别人的东西,所以自己编译了一把,你们也可以参考我的另一篇博文,学着自己编译——《利用Apache Ant编译Hadoop2.6.0-eclipse-plugin》
2)把编译好的Hadoop插件放到eclipse目录下的plugins下,然后重启eclipse
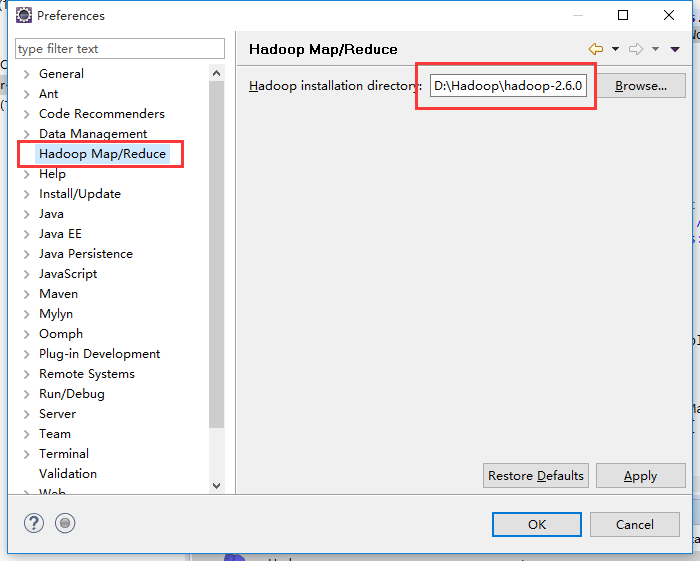
3)打开window-->Preferences-->Hadoop Map/Reduce设置里面的Hadoop安装目录
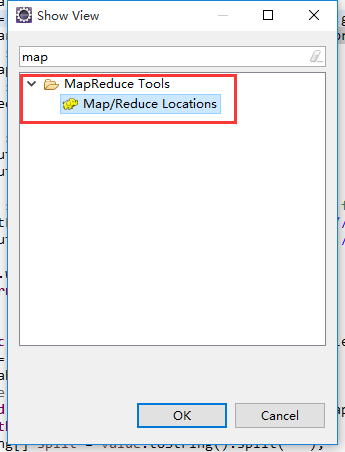
4)打开window-->Show View找到MapReduce Tools下的Map/Reduce Location,确定
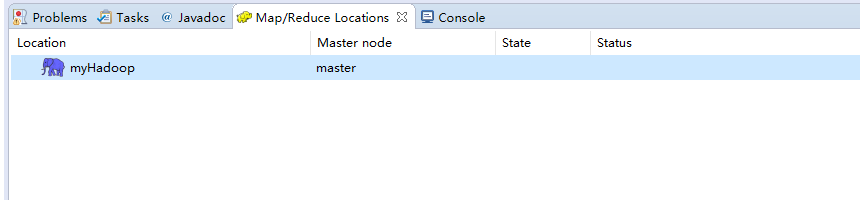
5)然后在eclipse的主界面就可以看到Map/Reduce Location的对话框了
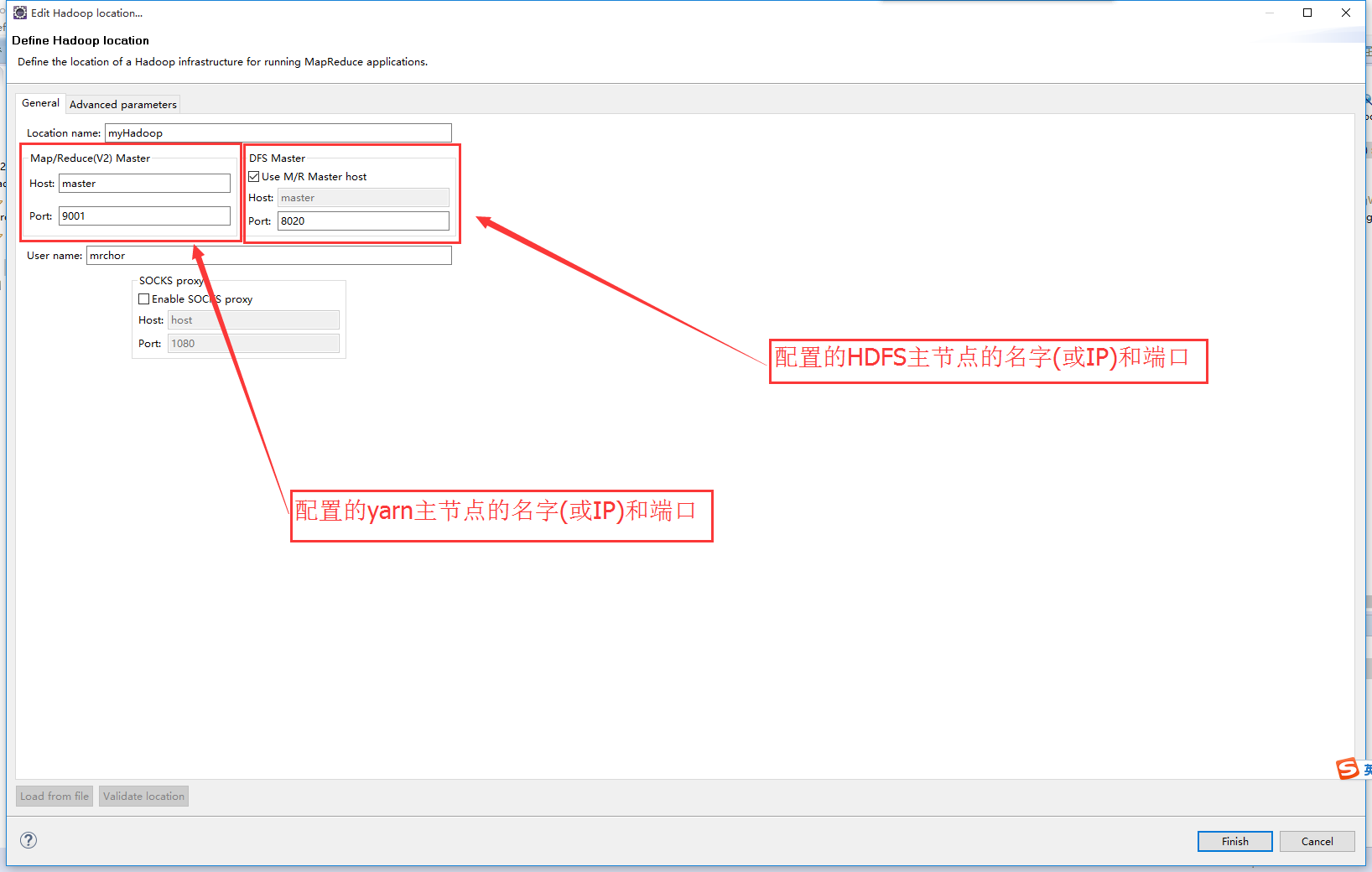
6)新建一个Hadoop Location,修改HDFS和yarn的主节点和端口,finish。
7)这时,在eclipse的Project Explorer中会看到HDFS的目录结构——DFS Locations
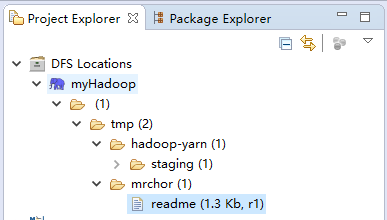
注意:可能你打开这个目录结构的时候回存在权限问题(Premission),这是因为你在Hadoop的HDFS的配置文件hdfs-site.xml中没有配置权限(默认是true,意思是不能被集群外的节点访问HDFS文件目录),我们需要在这儿配置为false,重启hdfs服务,然后刷新上述dfs目录即可:
<property> <name>dfs.permissions.enabled</name> <value>false</value> </property>
8)然后我们创建一个Map/Reduce Project,创建一个wordcount程序,我把Hadoop的README.txt传到/tmp/mrchor/目录下并改名为readme,输出路径为/tmp/mrchor/out。
package com.mrchor.HadoopDev.hadoopDev; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountApp { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, WordCountApp.class.getSimpleName()); job.setJarByClass(com.mrchor.HadoopDev.hadoopDev.WordCountApp.class); // TODO: specify a mapper job.setMapperClass(MyMapper.class); // TODO: specify a reducer job.setReducerClass(MyReducer.class); // TODO: specify output types job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); // TODO: specify input and output DIRECTORIES (not files) FileInputFormat.setInputPaths(job, new Path("hdfs://master:8020/tmp/mrchor/readme")); FileOutputFormat.setOutputPath(job, new Path("hdfs://master:8020/tmp/mrchor/out")); if (!job.waitForCompletion(true)) return; } public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ Text k2 = new Text(); LongWritable v2 = new LongWritable(); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { String[] split = value.toString().split(" "); for (String word : split) { k2.set(word); v2.set(1); context.write(k2, v2); } } } public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ long sum = 0; @Override protected void reduce(Text k2, Iterable<LongWritable> v2s, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { for (LongWritable one : v2s) { sum+=one.get(); } context.write(k2, new LongWritable(sum)); } } }
9)右键Run As-->Run on Hadoop:
A)注意:这边可能报错:
java.io.IOException: HADOOP_HOME or hadoop.home.dir are not set.
这是因为你在安装eclipse的这台机子上没有配置Hadoop的环境变量,需要配置一下:
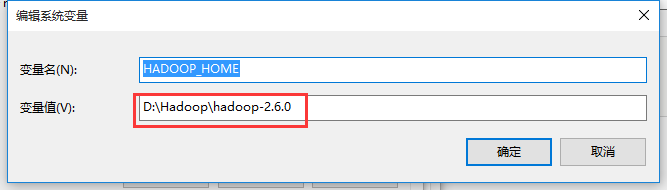
一)右键“我的电脑”或者“此电脑”选择属性:进入到高级系统设置-->高级-->环境变量配置-->系统变量
新建一个HADOOP_HOME,配置解压后的Hadoop-2.6.0的目录
二)重启eclipse(管理员运行)
10)继续运行wordcount程序,Run on Hadoop,可能会报如下错:
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:557)
at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:977)
at org.apache.hadoop.util.DiskChecker.checkAccessByFileMethods(DiskChecker.java:187)
at org.apache.hadoop.util.DiskChecker.checkDirAccess(DiskChecker.java:174)
at org.apache.hadoop.util.DiskChecker.checkDir(DiskChecker.java:108)
at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.confChanged(LocalDirAllocator.java:285)
at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.getLocalPathForWrite(LocalDirAllocator.java:344)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:150)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:131)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:115)
at org.apache.hadoop.mapred.LocalDistributedCacheManager.setup(LocalDistributedCacheManager.java:131)
at org.apache.hadoop.mapred.LocalJobRunner$Job.<init>(LocalJobRunner.java:163)
at org.apache.hadoop.mapred.LocalJobRunner.submitJob(LocalJobRunner.java:731)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:536)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1296)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1293)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1293)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1314)
at com.mrchor.HadoopDev.hadoopDev.WordCountApp.main(WordCountApp.java:34)
通过源码查看,发现在NativeIO.java有说明——还是权限问题,可能是需要将当前电脑加入到HDFS授权的用户组:
/** * Checks whether the current process has desired access rights on * the given path. * * Longer term this native function can be substituted with JDK7 * function Files#isReadable, isWritable, isExecutable. * * @param path input path * @param desiredAccess ACCESS_READ, ACCESS_WRITE or ACCESS_EXECUTE * @return true if access is allowed * @throws IOException I/O exception on error */
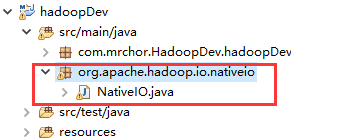
但是,我们这边有一个更加巧妙的办法解决这个问题——将源码中的这个文件复制到你的MapReduce的Project中,这个意思是程序在执行的时候回优先找你Project下的class作为程序的引用,而不会去引入的外部jar包中找:
11)继续运行wordcount程序,这次应该程序可以执行了,结果为:
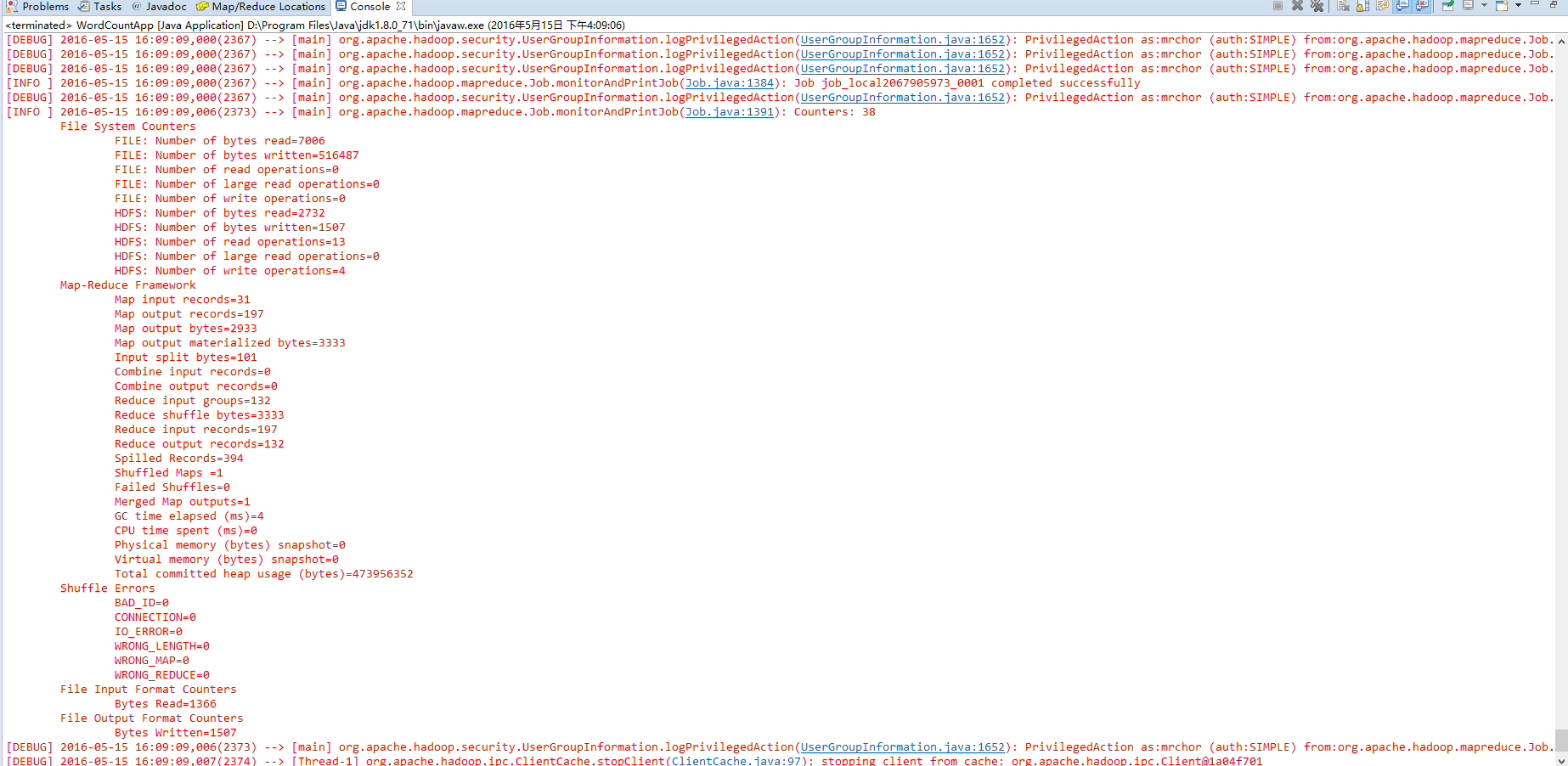
如果得到上面这个结果,说明程序运行正确,打印出来的是MapReduce程序运行结果。我们再刷新目录,可以看到/tmp/mrchor/out目录下有两个文件——_SUCCESS和part-r-00000:
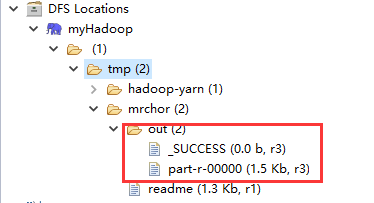

说明程序运行结果正确,此时,我们的eclipse远程调试Hadoop宣告成功!!!大家鼓掌O(∩_∩)O

 浙公网安备 33010602011771号
浙公网安备 33010602011771号