
hive group by 导致的数据倾斜问题
Group By
默认情况下,Map阶段同一Key数据分发给一个reduce,当一个key数据过大时就倾斜了。
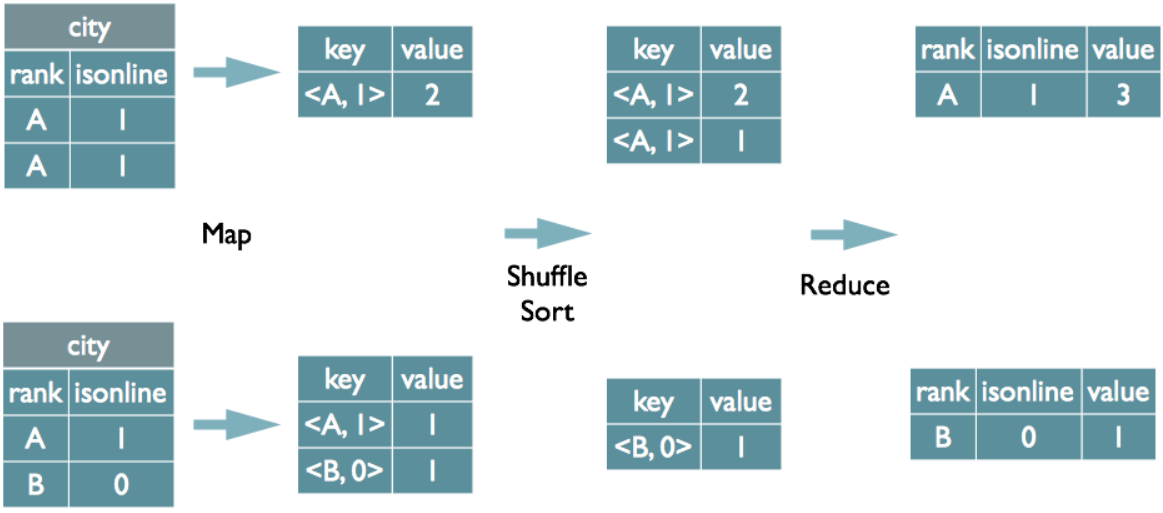
但并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端进行部分聚合,最后在Reduce端得出最终结果。
1)开启Map端聚合参数设置
(1)是否在Map端进行聚合(默认为true)
set hive.auto.convert.join = true;
(2)在Map端进行聚合操作的条目数目
set hive.groupby.mapaggr.checkinterval = 100000
(3)有数据倾斜的时候进行负载均衡(默认是false)
set hive.groupby.skewindata = true
情况一:
select count(distinct member_no),trade_date from uiopdb.sx_trade_his_detail group by trade_date
优化后
select count(member_no),trade_date from ( select member_no,trade_date as trade_date from uiopdb.sx_trade_his_detail group by member_no,trade_date ) d group by trade_date
情况二:
但是对于很大的表,比如需要统计每个会员的总的交易额情况,采用上面的方法也不能跑出来
优化前的代码(交易表中有三千万的数据)
set hive.groupby.skewindata = true; create table tmp_shop_trade_amt as select shop_no ,sum(txn_amt) as txn_amt from uiopdb.sx_trade_his_detail group by shop_no;

优化思路:如果某个key的数据量特别大,数据都集中到某一个reduce Task去进行相关数据的处理,这就导致了数据倾斜问题。
解决方案是首先采用局部聚合,即给key加上100以内的随机前缀,进行一次预聚合,然后对本次预聚合后的结果进行去掉随机前缀,进行一次数据的全局聚合。
优化后:
set hive.groupby.skewindata = true; create table tmp_shop_trade_amt_2 as select split(shop_no,'_')[1] as shop_no
,sum(txn_amt) total_txn_amt from
( select concat_ws("_", cast(ceiling(rand()*99) as string), shop_no) as shop_no
,sum(txn_amt) txn_amt from uiopdb.sx_trade_his_detail group by concat_ws("_", cast(ceiling(rand()*99) as string), shop_no) ) s group by split(shop_no,'_')[1] ;
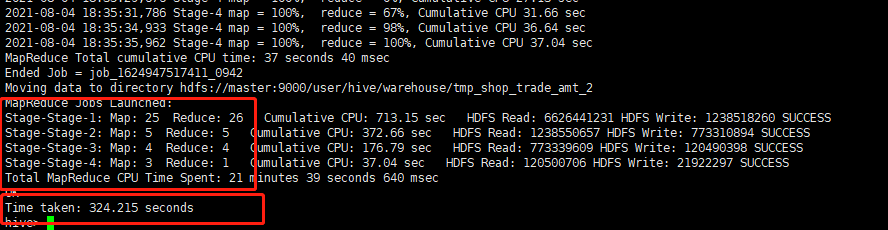
运行结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号