

Hive分桶表创建和详解
1. 创建分桶分区表
set hive.enforce.bucketing=true; --设置自动分桶参数 CREATE Table `tmp_wfll_log_url` ( `log_time` string, `log_key` string, `url_detail` string, `url_briefly` string, `url_action` string, `time_situation` string ) partitioned by(dt STRING) clustered by (log_key) sorted by (log_time) INTO 5 buckets --分5个通 row format delimited fields terminated by ',' lines terminated by '\n';
2. 往分区分桶后的表里插入数据
insert into `tmp_wfl_log_url` partition (dt='20210630') select `log_time` ,log_key ,url_detail ,url_briefly ,url_action ,time_situation from wfbmal.wfbwall_log_url
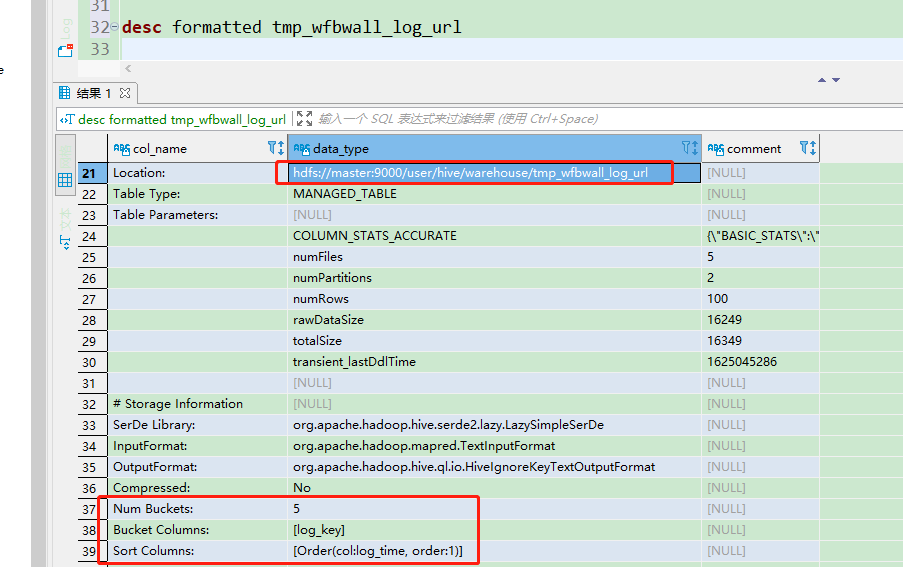
3. 查看分桶表的存放位置,和分桶信息
4. 检查分桶文件信息,已经被分成了5个桶

分桶抽样查询
对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结果。Hive可以通过对表进行抽样来满足这个需求。
select * from tmp_wll_log_url tablesample(bucket 1 out of 2 on log_key);
注:tablesample是抽样语句,语法:TABLESAMPLE(BUCKET x OUT OF y) 。
y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。例如,table总共分了4份,当y=2时,抽取(4/2=)2个bucket的数据,当y=8时,抽取(4/8=)1/2个bucket的数据。
x表示从哪个bucket开始抽取,如果需要取多个分区,以后的分区号为当前分区号加上y。例如,table总bucket数为4,tablesample(bucket 1 out of 2),表示总共抽取(4/2=)2个bucket的数据,抽取第1(x)个和第3(x+y)个bucket的数据。
注意:x的值必须小于等于y的值,否则
FAILED: SemanticException [Error 10061]: Numerator should not be bigger than denominator in sample clause for table stu_buck

 浙公网安备 33010602011771号
浙公网安备 33010602011771号