

HIVE经典题目解析
一、hive架构相关
可以结合平时使用hive的经验作答,也可以结合下图从数据的读入、解析、元数据的管理,数据的存储等角度回答:
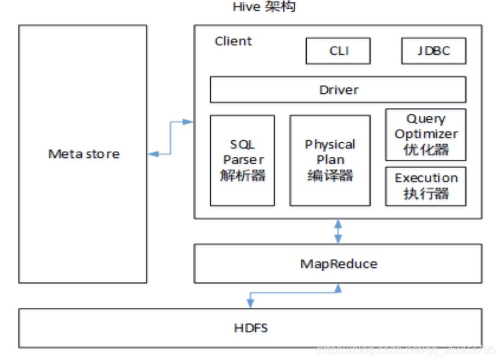
二、hive的特点
本题主要为了考察对hive的整体使用场景的掌握程度,毕竟只有知道了hive的特点,才能有针对性的在实际项目中的合适场景下使用hive。
可以从下面四个角度去分析:
1.数据存储位置
Hive的数据存储在hdfs上,元数据可以存储在指定的地方比如mysql,PostgreSQL等。
2.数据更新
Hive处理数据时一般不对数据进行改写,因为它不支持行级别的增删操作,如果要进行更新数据,一般可以通过分区或者表直接覆盖。
3.执行效率
Hive 执行延迟较高。虽然在小数据量时传统数据库延迟更低,但是当数据规模大到超过传统数据库的处理能力的时候,Hive 的并行计算显然能体现出优势。
4.数据规模
Hive 支持大规模的数据计算,通常是PB级别的数据。
三、内部表和外部表的区别
1. 内部表(MANAGED_TABLE):内部表其实就是管理表,当我们删除一个管理表时,Hive 也会删除这个表中数据。因此管理表不适合和 其他工具共享数据。
2. 外部表(EXTERNAL_TABLE):删除该表并不会删除掉原始数据,删除的是表的元数据。
四、4个by的区别
- Sort By:在同一个分区内排序
- Order By:全局排序,只有一个Reducer;
- Distrbute By:类似 MapReduce 中Partition,进行分区,一般结合sort by使用。
- Cluster By:当 Distribute by 和 Sort by 字段相同时,可以使用Cluster by方式。Cluster by 除了具有 Distribute by 的功能外还兼具 Sort by 的功能。但是只能升序排序,不能指定排序规则为ASC或者DESC。
五、介绍一下有哪些常用函数
5.1、行转列函数
1. CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字符串。
例如: concat( aa, ‘:’, bb) 就相当于把aa列和bb列用冒号连接起来了,aa:bb。
- CONCAT_WS(separator, str1, str2,…):CONCAT_WS() 代表 CONCAT With Separator ,是CONCAT()的特殊形式。第一个参数是其它参数的分隔符。分隔符的位置放在要连接的两个字符串之间。分隔符可以是一个字符串,也可以是其它参数。如果分隔符为 NULL,则结果为 NULL。函数会忽略任何分隔符参数后的 NULL 值。但是CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。
- COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。
5.2、列转行函数
1. EXPLODE(col):将hive某列中复杂的array或者map结构拆分成多行。
- LATERAL VIEW:常和UDTF函数一起使用。
用法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias
解释:用于和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
5.3、Rank排名函数
1. RANK() 排序相同时会重复,总数不会变;
2. DENSE_RANK() 排序相同时会重复,总数会减少;
3. ROW_NUMBER() 根据顺序计算排名。
在实际开发中,以上三个rank函数通常是和开窗函数一起使用的。
5.4、窗口函数(开窗函数)
1. OVER():用于指定分析函数工作时的数据窗口大小,这个数据窗口大小可能会随着行的变而变化;
2. CURRENT ROW:当前行;
- n PRECEDING:往前n行数据;
- n FOLLOWING:往后n行数据;
- UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点;
- LAG(col,n,default_val):往前第n行数据;
- LEAD(col,n, default_val):往后第n行数据;
- NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。这个函数需要注意:n必须为int类型。
六、UDF、UDAF、UDTF相关题
6.1. UDF、UDAF、UDTF的区别
当Hive自带的函数无法满足我们的业务处理需求时,hive允许我们自定义函数来满足需求。
根据自定义函数的类别分为以下三种:
- UDF:User-Defined-Function,用户自定义函数,数据是一进一出,功能类似于大多数数学函数或者字符串处理函数;
- UDAF:User-Defined Aggregation Function,用户自定义聚合函数,数据是多进一出,功能类似于 count/max/min;
- UDTF:User-Defined Table-Generating Functions,用户自定义表生成函数,数据是一进多处,功能类似于lateral view explore();
6.2、怎么自定义UDF、UDAF、UDTF函数
1. 自定义UDF函数
(1). 继承org.apache.hadoop.hive.ql.UDF函数;
(2). 重写evaluate方法,evaluate方法支持重载。
2. 自定义UDAF函数
(1).必须继承org.apache.hadoop.hive.ql.exec.UDAF(函数类继承)和org.apache.hadoop.hive.ql.exec.UDAFEvaluator(内部类Evaluator实现UDAFEvaluator接口);
(2). 重写Evaluator方法时需要实现 init、iterate、terminatePartial、merge、terminate 这几个函数:
init():类似于构造函数,用于UDAF的初始化
iterate():接收传入的参数,并进行内部的轮转,返回boolean
terminatePartial():无参数,其为iterate函数轮转结束后,返回轮转数据,类似于 hadoop的Combiner
merge():接收terminatePartial的返回结果,进行数据merge操作,其返回类型为 boolean
terminate():返回最终的聚集函数结果
3. 自定义UDTF函数
(1). 继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF函数;
(2). 重写实现initialize, process, close三个方法。
1. UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息(返回个数,类型)。
2. 初始化完成后,会调用process方法,真正的处理过程在process函数中,在process中,每一次forward()调用产生一行;如果产生多列可以将多个列的值放在一个数组中,然后将该数组传入到forward()函数。
3. 最后close()方法调用,对需要清理的方法进行清理。
通常使用 UDF 函数解析公共字段;用 UDTF 函数解析事件字段。
七、hive怎么解决数据倾斜
1. group by
注:group by 优于 distinct group
情形:group by 维度过小,某值的数量过多
后果:处理某值的 reduce 非常耗时
解决方式:采用 sum() group by 的方式来替换 count(distinct)完成计算。
2. count(distinct)
情形:某特殊值过多
后果:处理此特殊值的 reduce 耗时;只有一个 reduce 任务
解决方式:count distinct 时,将值为空的情况单独处理,比如可以直接过滤空值的行,
在最后结果中加 1。如果还有其他计算,需要进行 group by,可以先将值为空的记录单独处理,再和其他计算结果进行 union。
3. 不同数据类型关联产生数据倾斜
情形:比如用户表中 user_id 字段为 int,log 表中 user_id 字段既有 string 类型也有 int 类型。当按照 user_id 进行两个表的 Join 操作时。
后果:处理此特殊值的 reduce 耗时;只有一个 reduce 任务默认的 Hash 操作会按 int 型的 id 来进行分配,这样会导致所有 string 类型 id 的记录都分配到一个 Reducer 中。
解决方式:把数字类型转换成字符串类型,如
select * from users a
left outer join logs b
on a.usr_id = cast(b.user_id as string)
4. 开启数据倾斜时负载均衡
set hive.groupby.skewindata=true;
思想:就是先随机分发并处理,再按照 key group by 来分发处理。
操作:当选项设定为 true,生成的查询计划会有两个 MRJob。
第一个 MRJob 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 GroupBy Key 有可能被分发到不同的Reduce 中,从而达到负载均衡的目的;
第二个 MRJob 再根据预处理的数据结果按照 GroupBy Key 分布到 Reduce 中(这个过程可以保证相同的原始 GroupBy Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
总结:它使计算变成了两个 mapreduce,先在第一个中在 shuffle 过程 partition 时随机给 key 打标记,使每个 key 随机均匀分布到各个reduce 上计算,但是这样只能完成部分计算,因为相同 key 没有分配到相同 reduce 上。所以需要第二次的 mapreduce,这次就回归正常 shuffle,但是数据分布不均匀的问题在第一次 mapreduce 已经有了很大的改善,因此基本解决数据倾斜。因为大量计算已经在第一次mr 中随机分布到各个节点完成。
5. 控制空值分布
将为空的 key 转变为字符串加随机数或纯随机数,将因空值而造成倾斜的数据分不到多个 Reducer。
注:对于异常值如果不需要的话,最好是提前在 where 条件里过滤掉,这样可以使计算量大大减少。
实践中,可以使用 case when 对空值赋上随机值。此方法比直接写 is not null 更好,因为前者 job 数为 1,后者为 2.
使用 case when 实例 1
select userid, name from user_info a join ( select case when userid is null then cast (rand(47)* 100000 as int ) else userid end from user_read_log )b on a.userid = b.userid
使用 case when 实例 2
select
'${date}' as thedate,
a.query,
from fdi_search_query_cat_qp_temp a
left outer join brand f
on
f.pt='${date}000000' and case when a.new_brand_id is null then concat('hive',rand() ) else
a.new_brand_id end = f.brand_id;
如果上述的方法还不能解决,比如当有多个 JOIN 的时候,建议建立临时表,然后拆分HIVE SQL 语句。
八、hive优化相关题
1. MapJoin
如果不指定 MapJoin 或者不符合 MapJoin 的条件,那么 Hive 解析器会将 Join 操作转换 成 Common Join,即:在 Reduce 阶段完成 join。容易发生数据倾斜。可以用MapJoin把小 表全部加载到内存在 map 端进行 join,避免 reducer 处理。
2. 行列过滤
列处理:在 SELECT 中,只拿需要的列,如果有,尽量使用分区过滤,少用 SELECT *。
行处理:在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在 Where 后面,那 么就会先全表关联,之后再过滤。
3. 多采用分桶技术
4.结合实际环境合理设置 Map 数
(1)通常情况下,作业会通过 input的目录产生一个或者多个map任务。 主要的决定因素有:input的文件总个数,input的文件大小,集群设置的文件块大小;
(2)map数不是越多越好;如果一个任务有很多小文件(远远小于块大小 128m),则每个小文件 也会被当做一个块,用一个 map 任务来完成,而一个 map 任务启动和初始化的时间远远大 于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的 map 数是受限的。解决这个问题需要减少map数。
(3)并不是每个map处理接近128m的文件块就是完美的;比如有一个 127m 的文件,正常会用一个 map 去完成,但这个文件只 有一个或者两个小字段,却有几千万的记录,如果 map 处理的逻辑比较复杂,用一个 map 任务去做,肯定也比较耗时。解决这个问题需要增加map数。
5. 合并大量小文件
在Map执行前合并小文件,可以减少Map数:CombineHiveInputFormat 具有对小文件进行合并的功能(系统默认的格式)。HiveInputFormat 没有对小文件合并功能。
6.设置合理的Reduce数
Reduce 个数也并不是越多越好
(1)过多的启动和初始化 Reduce 也会消耗时间和资源;
(2)有多少个 Reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题;
(3)在设置Reduce个数的时候也需要考虑这两个原则:处理大数据量利用合适的 Reduce 数;使单个 Reduce 任务处理数据量大小要合适;
7.输出合并小文件常用参数
SET hive.merge.mapfiles = true; -- 默认 true,在 map-only 任务结束时合并小文件 SET hive.merge.mapredfiles = true; -- 默认 false,在 map-reduce 任务结束时合并小文件 SET hive.merge.size.per.task = 268435456; -- 默认 256M SET hive.merge.smallfiles.avgsize = 16777216; -- 当输出文件的平均大小小于 16m 该值时,启动一个独立的 map-reduce 任务进行文件 merge
8.开启 map 端 combiner(不影响最终业务逻辑)
开启命令:
set hive.map.aggr=true;
9 中间结果压缩
设置 map 端输出、中间结果压缩。(不完全是解决数据倾斜的问题,但是减少了 IO 读写和网络传输,能提高很多效率)
九 其他问题
1. Hive join 过程中大表小表的放置顺序?
将最大的表放置在JOIN 语句的最右边,或者直接使用/*+ streamtable(table_name) */指出。
在编写带有join 操作的代码语句时,应该将条目少的表/子查询放在Join 操作符的左边。因为在Reduce 阶段,位于Join 操作符左边的表的内容会被加载进内存,载入条目较少的表可以有效减少OOM(out of memory)即内存溢出。所以对于同一个key 来说,对应的value 值小的放前,大的放后,这便是“小表放前”原则。若一条语句中有多个Join, 依据Join 的条件相同与否,有不同的处理方法。
2. Hive 的两张表关联,使用MapReduce 怎么实现?(☆☆☆☆☆)
如果其中有一张表为小表,直接使用map 端join 的方式(map 端加载小表)进行聚合。
如果两张都是大表,那么采用联合key,联合key 的第一个组成部分是join on 中的公共字段,第二部分是一个flag,0 代表表A,1 代表表B,由此让Reduce 区分客户信息和订单信息;在Mapper 中同时处理两张表的信息,将join on 公共字段相同的数据划分到同一个分区中,进而传递到一个Reduce 中,然后在Reduce 中实现聚合。
3. Hive 中使用什么代替in 查询?
在Hive 0.13 版本之前,通过left outer join 实现SQL 中的in 查询,0.13 版本之后,Hive 已经支持in 查询。
4. 所有的Hive 任务都会有MapReduce 的执行吗?
不是,从Hive0.10.0 版本开始,对于简单的不需要聚合的类似SELECT from
LIMIT n 语句,不需要起MapReduce job,直接通过Fetch task 获取数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号