
Python中的MapReduce以及在Hadoop环境下运行之词频统计
一、在Linux中运行
首先在Linux中新建下面的目录,里面什么也不要放,然后进入到目录 /opt/data/mapreduce_test/
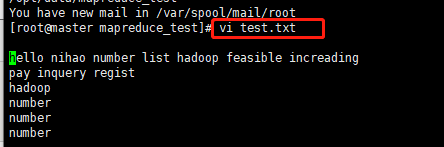
1. 然后在里面创建一个test.txt文件,并往里面添加一些需要统计的单词,
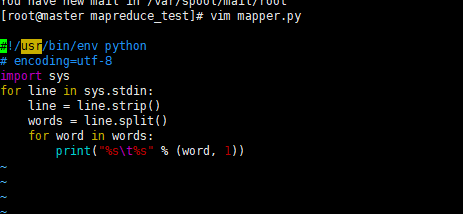
2. 接着编辑mapper.py文件,vim mapper.py
#!/usr/bin/env python
# encoding=utf-8
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print("%s\t%s" % (word, 1))
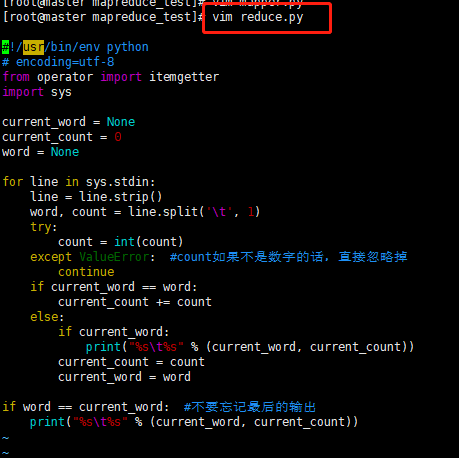
3. 接着新建reduce.py文件, vim reduce.py
#!/usr/bin/env python
# encoding=utf-8
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError: #count如果不是数字的话,直接忽略掉
continue
if current_word == word:
current_count += count
else:
if current_word:
print("%s\t%s" % (current_word, current_count))
current_count = count
current_word = word
if word == current_word: #不要忘记最后的输出
print("%s\t%s" % (current_word, current_count))
4.分别对mapper.py和reduce.py 授权
[root@master mapreduce_test]# chmod -R 777 mapper.py [root@master mapreduce_test]# chmod -R 777 reduce.py [root@master mapreduce_test]# chmod -R 777 test.txt

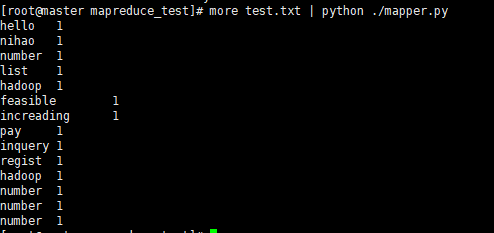
5. 接下来开始运行mapper.py程序运行,
more test.txt | python ./mapper.py
排序运行
more test.txt | python ./mapper.py | sort
more test.txt | python ./mapper.py | sort -k1,1
6. mapper和reduce同时运行
more test.txt | python ./mapper.py | sort -k1,1 | ./reduce.py
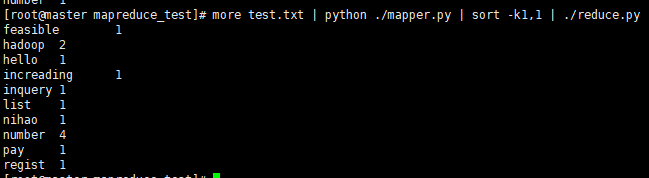
二、在Hadoop环境中运行
还是在这个目录下,新建一个run.sh文件
里面的内容如下:
hadoop jar /opt/soft/hadoop-2.7.7/share/hadoop/tools/lib/hadoop-streaming-2.7.7.jar \ -file /opt/data/mapreduce_test/mapper.py -mapper /opt/data/mapreduce_test/mapper.py \ -file /opt/data/mapreduce_test/reduce.py -reducer /opt/data/mapreduce_test/reduce.py \ -input /tmp/py/input/* -output /tmp/py/output
第一行配置的是hadoop-streaming-2.7.5.jar所在的位置

然后给run.sh添加可执行权限

接着在hdfs环境下新建文件夹,
hdfs dfs -mkdir -p /tmp/py/input
然后把test.txt上传进去
hdfs dfs -put test.txt /tmp/py/input
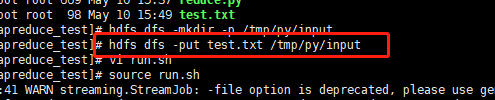
接着运行run.sh
source run.sh
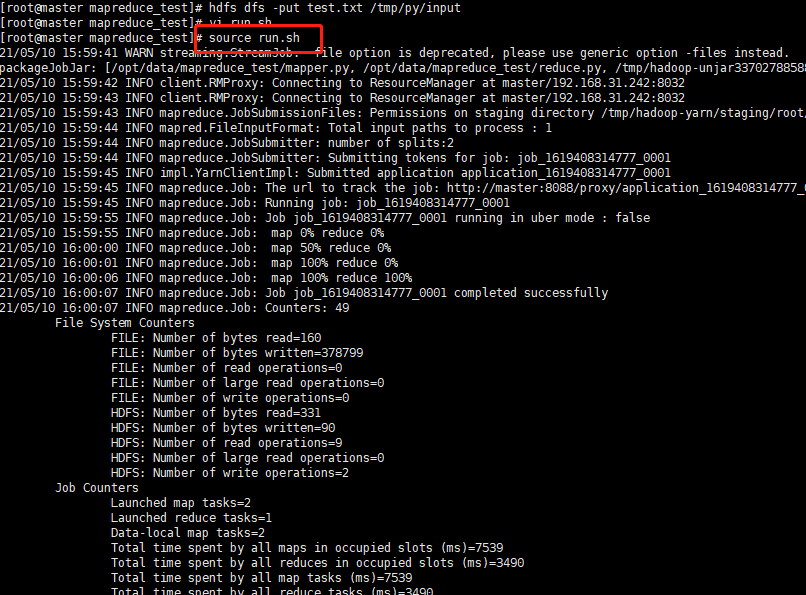
接着查看生成的文件
hdfs dfs -ls /tmp/py/output

其中part-00000就是运行结果,打开看一下
hdfs dfs -cat /tmp/py/output/part-00000
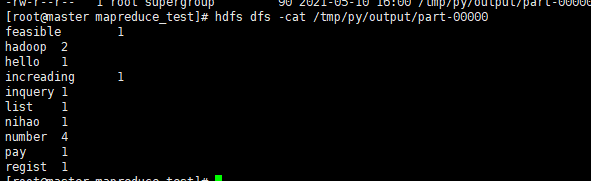
然后把运行结果保存到本地
hdfs dfs -get /tmp/py/output/part-00000 /opt/data
本文参考:Python中的MapReduce以及在Hadoop环境下运行_秦哥的博客-CSDN博客

 浙公网安备 33010602011771号
浙公网安备 33010602011771号