
MapReduce的工作原理
在MapReduce整个过程可以概括为以下过程:
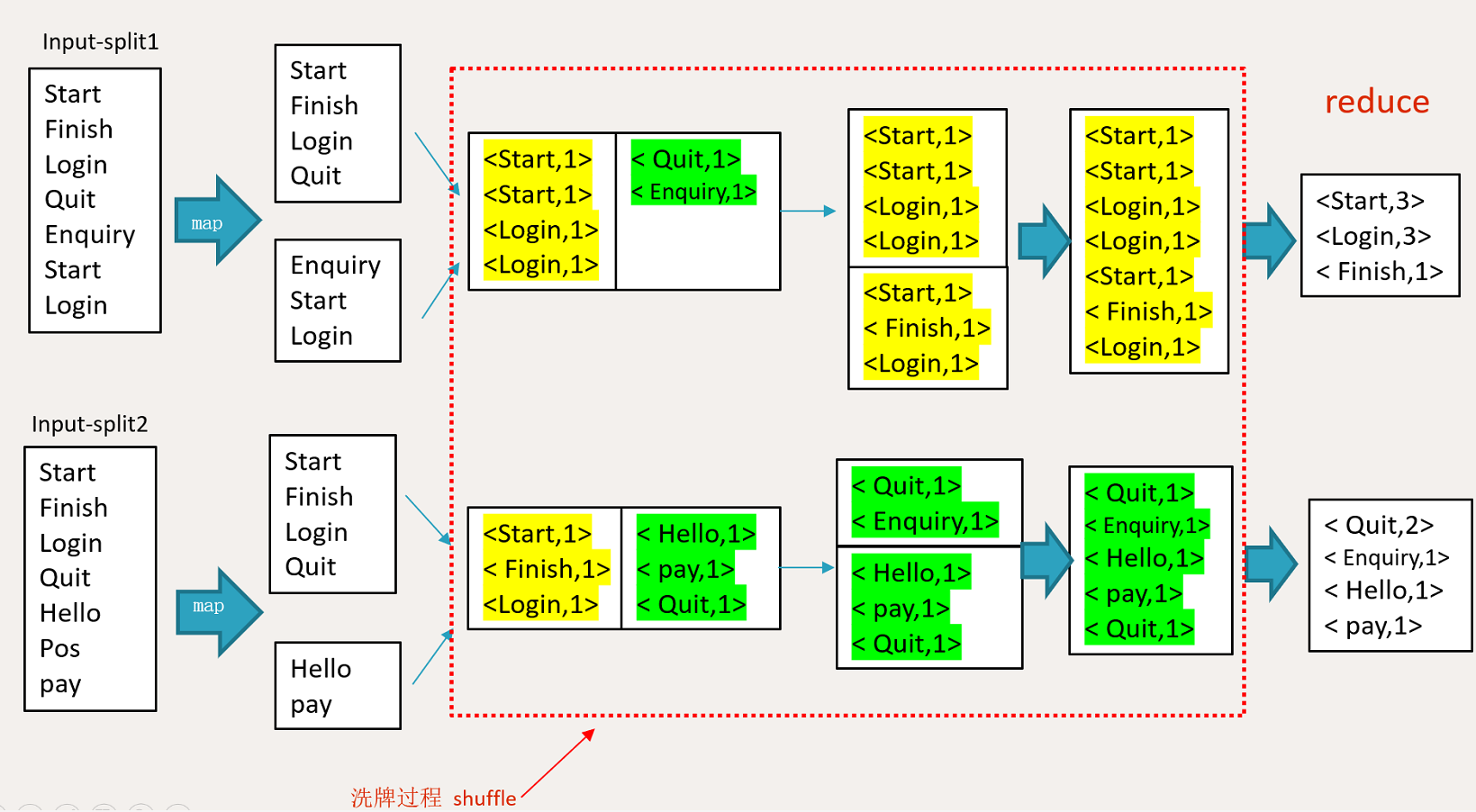
input --> map --> shuffle --> reduce -->输出
输入文件会被切分成多个块,每一块都有一个map task
map阶段的输出结果会先写到内存缓冲区,然后由缓冲区写到磁盘上。默认的缓冲区大小是100M,溢出的百分比是0.8,也就是说当缓冲区中达到80M的时候就会往磁盘上写。如果map计算完成后的中间结果没有达到80M,最终也是要写到磁盘上的,因为它最终还是要形成文件。那么,在往磁盘上写的时候会进行分区和排序。一个map的输出可能有多个这个的文件,这些文件最终会合并成一个,这就是这个map的输出文件。
1、有一个待处理的大数据,被划分成大小相同的数据文件(如64MB),以及与此相应的用户作业程序。
2、系统中有一个负责调度的主节点(Master),以及数据Map和Reduce工作节点(Worker).
3、用户作业提交个主节点。
4、输入文件分片,每一片都由一个MapTask来处理
5、Map输出的中间结果会先放在内存缓冲区中,这个缓冲区的大小默认是100M,当缓冲区中的内容达到80%时(80M)会将缓冲区的内容写到磁盘上。也就是说,一个map会输出一个或者多个这样的文件,如果一个map输出的全部内容没有超过限制,那么最终也会发生这个写磁盘的操作,只不过是写几次的问题。
6、从缓冲区写到磁盘的时候,会进行分区并排序,分区指的是某个key应该进入到哪个分区,同一分区中的key会进行排序,如果定义了Combiner的话,也会进行combine操作
7、如果一个map产生的中间结果存放到多个文件,那么这些文件最终会合并成一个文件,这个合并过程不会改变分区数量,只会减少文件数量。例如,假设分了3个区,4个文件,那么最终会合并成1个文件,3个区
8、以上只是一个map的输出,接下来进入reduce阶段
9、每个reducer对应一个ReduceTask,在真正开始reduce之前,先要从分区中抓取数据
10、相同的分区的数据会进入同一个reduce。这一步中会从所有map输出中抓取某一分区的数据,在抓取的过程中伴随着排序、合并。
11、reduce输出
注意:
1 在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据。这样做是为了避免有些reduce任务分配到大量数据,而有些reduce任务却分到很少数据,甚至没有分到数据的尴尬局面。其实分区就是对数据进行hash的过程。然后对每个分区中的数据进行排序,如果此时设置了Combiner,将排序后的结果进行Combianer操作,这样做的目的是让尽可能少的数据写入到磁盘。
Combiner的举例说明:
Combiner:这是一个可以优化MapReduce作业所使用带宽的步骤,这个过程叫Combiner,它在Mapper之后Reducer之前运行。Combiner是可选的,如果这个过程适合于你的作业,Combiner实例会在每一个运行map任务的节点上运行。Combiner会接收特定节点上的Mapper实例的输出作为输入,接着Combiner的输出会被发送到Reducer那里,而不是发送Mapper的输出。Combiner是一个“迷你reduce”过程,它只处理单台机器生成的数据。
词频统计是一个可以展示Combiner的用处的基础例子,上面的词频统计程序为每一个它看到的词生成了一个(start,1)键值对。所以如果在同一个文档内“cat”出现了3次,(”login”,1)键值对会被生成3次,这些键值对会被送到Reducer那里。通过使用Combiner,这些键值对可以被压缩为一个送往Reducer的键值对(”cat”,3)。现在每一个节点针对每一个词只会发送一个值到reducer,大大减少了shuffle过程所需要的带宽并加速了作业的执行。这里面最爽的就是我们不用写任何额外的代码就可以享用此功能!如果你的reduce是可交换及可组合的,那么它也就可以作为一个Combiner。你只要在driver中添加下面这行代码就可以在词频统计程序中启用Combiner。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号