

spark在windows环境下安装和配置 详解
背景:一,在用python编辑spark时,需要在windows本地搭建一套spark环境,然后将编辑好的.py上传到hadoop集群,再进行调用;二,在应用spark进行机器学习时,更多时候还是在windows环境下进行会相对比较方便。
组件准备:
- 1、Python3.6.7
- 2、JDK(本文中使用JDK1.8)
- 3、Scala(Scala-2.12.8)
- 4、Spark(spark-2.4.5-bin-hadoop2.7.gz)
- 5、Hadoop(Hadoop 2.7)
- 6、winutils.exe
备注,尽量使用python3.6对应spark的2.4,不然会版本不兼容。本次安装采用的python3.6.7和spark2.4.5。
一,python的安装
在python的官网下载 https://www.python.org/ftp/python/3.6.7/ 并进行安装,
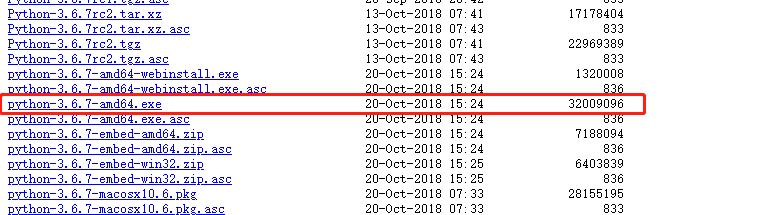
安装,如果为自定义安装,需要自己配置一下相关的环境变量

查看是否安装成功,

二,JDK安装
JDK下载地址:https://www.oracle.com/cn/java/technologies/javase/javase-jdk8-downloads.html
安装完成以后,配置环境变量。配置环境变量的方法为电脑[右键]——>属性——>环境变量,编辑环境变量
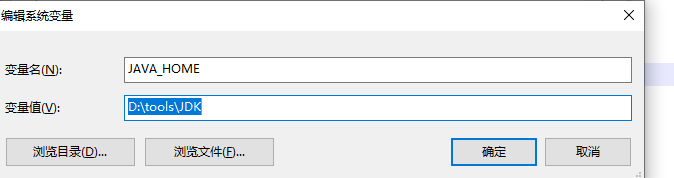
配置Java环境变量主要有三个:
path中
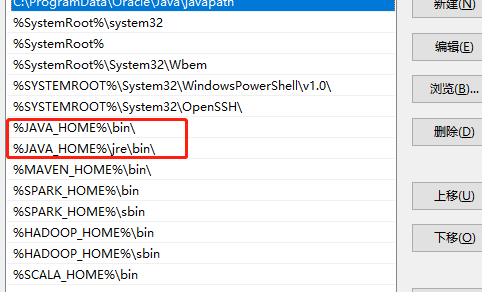
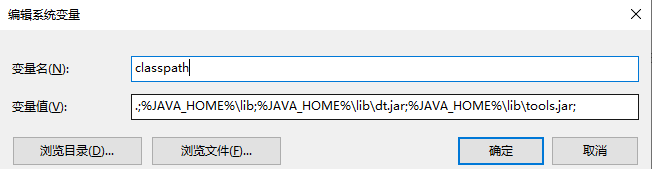
其中Java_Home变量则为Java安装路径,CLASS_PATH可以看成Java安装目录下lib文件目录,Path一般为系统自带变量,修改时直接新增Java安装目录下的bin目录。
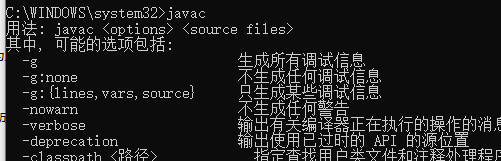
Java如果安装成功,则在cmd窗口中分别输入java 和javac,如果均出现如下图所示结果,则表示安装Java成功

3、Scala(Scala-2.12.8)
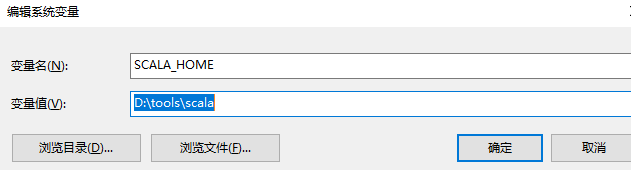
下载好后,进行安装,然后配置环境变量配置
安装好后运行cmd命令提示符,输入Scala后,如果能够正常进入到Scala的交互命令环境则表明安装成功

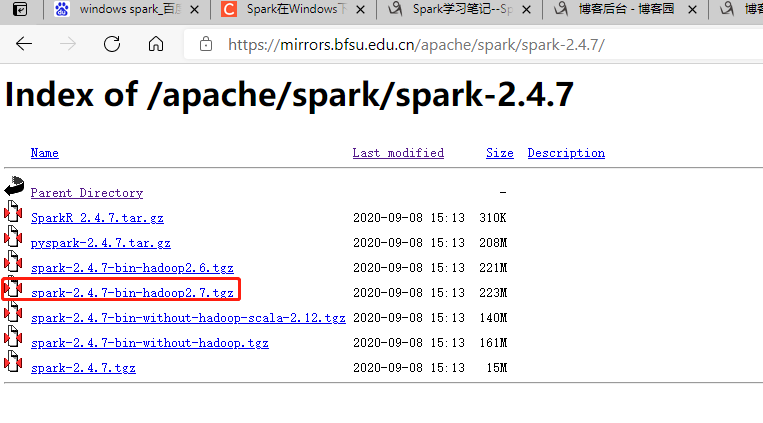
4、Spark(spark-2.4.5-bin-hadoop2.7.gz),下载网址:https://mirrors.bfsu.edu.cn/apache/spark/
然后进行解压,我这里是解压到:D:\tools\spark
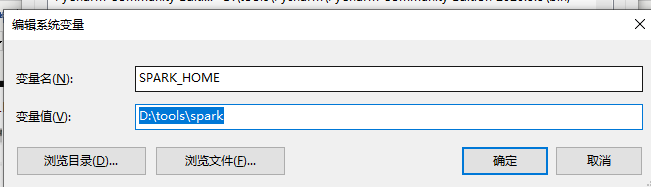
- 5、Hadoop(Hadoop 2.7)
由于spark是基于hadoop建立的,所以需要下载Hadoop,这里选择hadoop 2.7,然后下载后放到本地目录,和之前一样,设置相关的2个地方的环境变量即可!
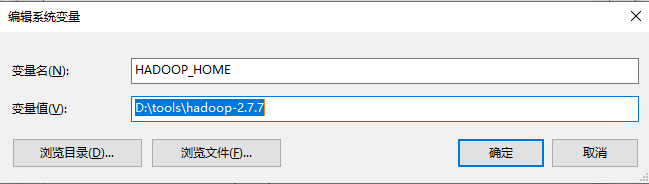
然后在path里面
- 6、winutils.exe
还需要一个插件,winutil.exe,其下载位置在https://github.com/steveloughran/winutils ,对应的hadoop-2.7.1/bin下的

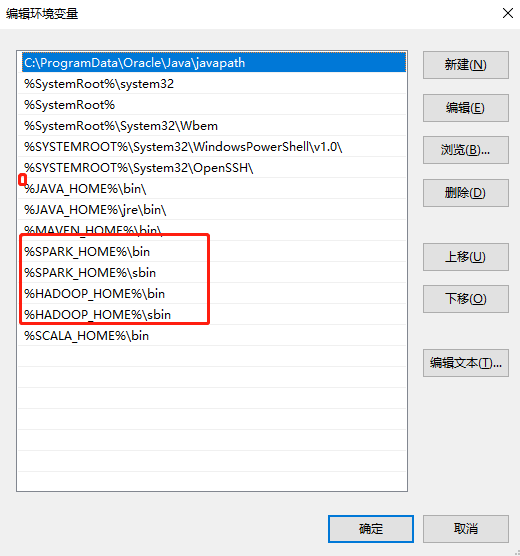
可以通过此方式查看环境变量是否该配置的都配置了

其他相关配置
1),将spark所在目录下(比如我的是E:\spark\spark-2.1.0-bin-hadoop2.7\python)的pyspark文件夹拷贝到python文件夹下(我的是E:\Anaconda2\Lib\site-packages),最好使用此方法进行安装pyspark
2),安装py4j库,可以直接使用pip install py4j安装
3) 修改权限
将winutils.exe文件放到Hadoop的bin目录下,然后以管理员的身份打开cmd,然后通过cd命令进入到Hadoop的bin目录下,然后执行以下命令:
winutils.exe chmod 777 c:\tmp\Hive
这里的c:\tmp\Hive需要事先创建好。
4)验证pyspark启动
在cmd中进行验证pyspark是否成功
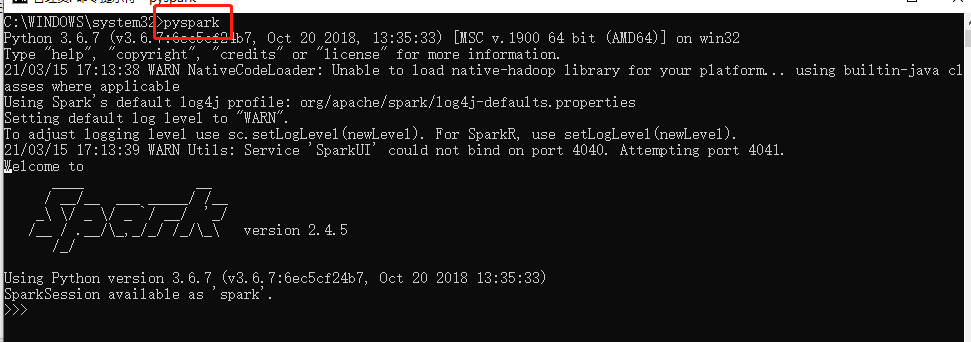
在安装或者使用过程中如出现
Python worker failed to connect back 和TypeError:an integer is required 均是说明版本不兼容

 浙公网安备 33010602011771号
浙公网安备 33010602011771号