k8s-RC-Service-deploy四
一同一个pod下的容器的网络与pod容器的IP共享
[root@k8s-master k8s]# cat nginx_pod.yaml apiVersion: v1 kind: Pod metadata: name: nginx-pod labels: app: web spec: containers: - name: nginx123 image: 192.168.23.146:5000/nginx:1.13 ports: - containerPort: 80

从上图可以看出pod是落在了docekr01主机上,我们在docker01主机上看,创建的容器有2个,通过inspect可以找到哪个是起的容器IP,容器和pod共用一个IP,pod容器IP是71.2,pod容器ID是7a9*,.我们在yaml文件定义了一个nginx1容器
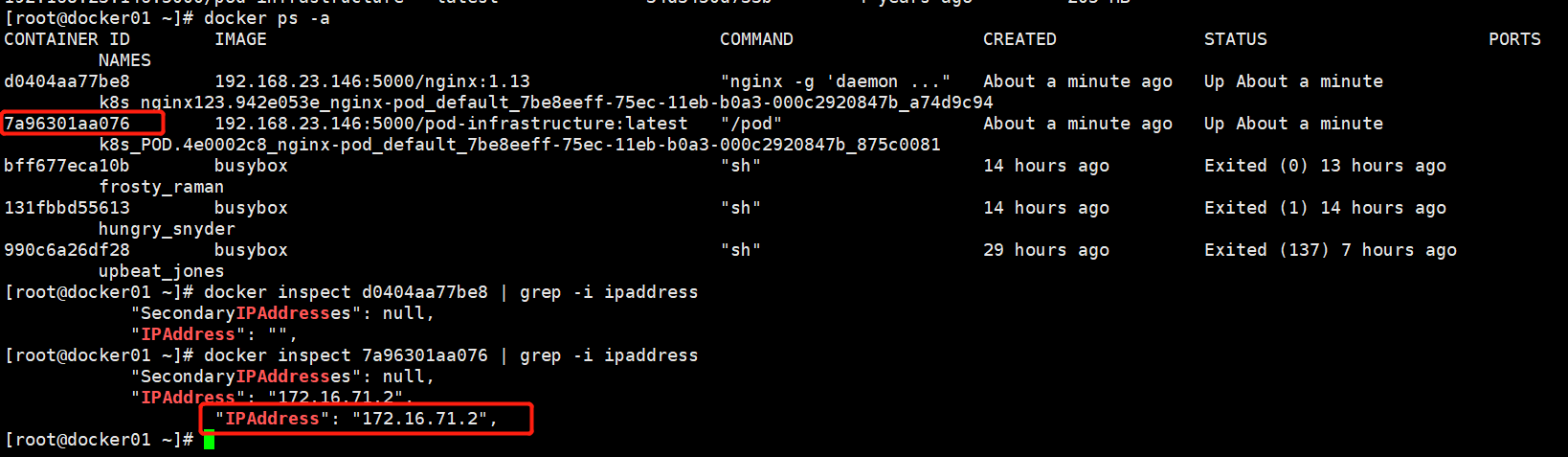
我们可以看出nginx的网络类型是container,nginx容器是和7a963这个pod容器共用一个IP,pod和容器端口不能共用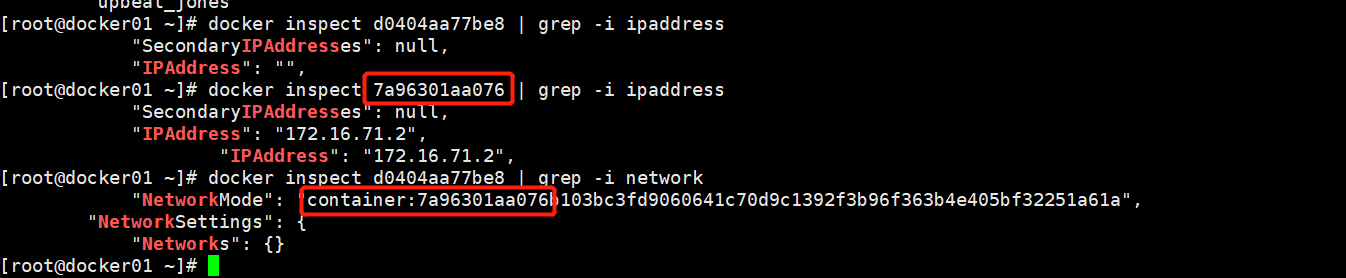
k8s创建一个pod资源,pod资源会控制kubelet,,kubelet会控制docker,启动2个容器,一个容器是业务容器nginx1(yaml里面只配置了一个),一个是基础pod容器.通过网络类型是container把pod容器和普通业务容器绑一块,普通业务只需要提供80端口就行了,,访问80端口会正常访问nginx,其他特性由pod容器提供.
pod资源包括业务容器和pod容器

apiVersion: v1 #apisever版本 kind: Pod #类型,这是一个pod,还有service\deployment metadata: #记录了pod自身的元数据,比如pod的名字、属于哪个namespace name: nginx-pod2 labels: app: web spec: #记录了pod内部所有资源的详细信息 containers: #记录了pod内的容器信息。包含了容器名字,容器镜像地址 - name: nginx123 image: 192.168.23.146:5000/nginx:1.13 ports: - containerPort: 80 - name: busybox image: 192.168.23.146:5000/busybox:v1 command: ["sleep","3600"] #让容器hang住,否则执行完容器就退出了 ports: - containerPort: 80


我们发现pod里面的两个业务容器nginx1和busybox与一个pod基础容器共用一个IP

二 ReplicationController控制器
Kubernetes需要保证应用能够持续运行,这是RC的工作内容,它会确保任何时间Kubernetes中都有指定数量的Pod在运行。在此基础上,RC还提供了一些更高级的特性,比如滚动升级、升级回滚等.实际工作中,很少单独操作Pod的,之所以k8s能够“自愈”,就是通过rc(ReplicationController)、rs(ReplicaSet)、Deployment等这些组件.
以上这些组件,就是通过Label标签等机制,对Pod实现“水平维度”的控制.保证pod高可用,rc会一直监控pod容器状态
我们创建rc资源的时候,会创建副本数所对应的pod个数
vi nginx-rc.yaml apiVersion: v1 kind: ReplicationController metadata: name: myweb #rc的名字叫mtweb,pod的名字会以这个开头,创建的pod是myweb-* spec: replicas: 2 #副本数是2个,到时候会启动2个pod selector: #选择器 app: myweb # template: #pod启动模板 metadata: #RC会随机给pod生成2个名字 labels: app: myweb spec: containers: - name: myweb image: 192.168.23.146:5000/nginx:1.13 ports: - containerPort: 80
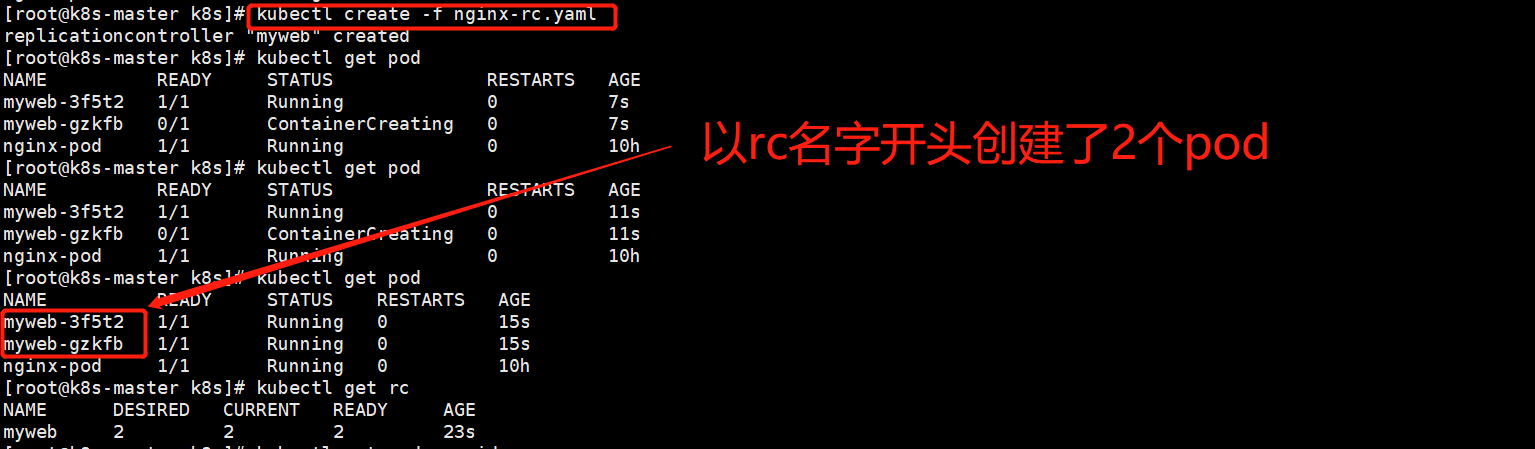
两个pod分别起在了不同的node节点

rc始终会保持pod数量为2 ,我们不妨先删除一个pod,看是不是会自动生成一个:结论就是会自动创建一个,保持pod副本数是2都处于运行中
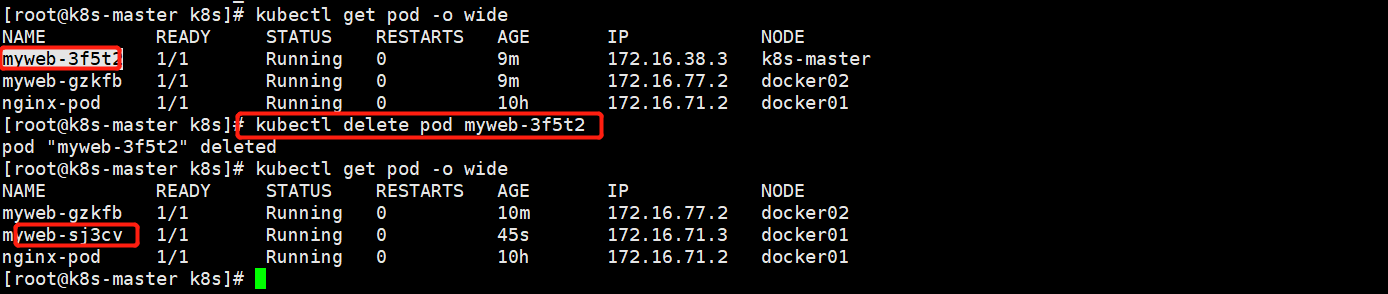
RC与Pod的关联——Label,是根据标签来确定pod是不是我管理的,rc定义的标签是app=myweb,不是这个标签的pod不归我管
selector: #选择器
app: myweb #


[root@k8s-master ~]# kubectl get all -o wide
创建rc之后会生成svc,也会生成对应的pod副本数,这是查看所有资源

rc的滚动升级
滚动升级是一种平滑过渡的升级方式,通过逐步替换的策略,保证整体系统的稳定,在初始升级的时候就可以及时发现、调整问题,以保证问题影响度不会扩大。Kubernetes中滚动升级的命令如下:
$ kubectl rolling-update myweb -f nginx-rc2.yaml --update-period=10s
升级开始后,首先依据提供的定义文件创建V2版本的RC,然后每隔10s(--update-period=10s默认1分钟)逐步的增加V2版本的Pod副本数,逐步减少V1版本Pod的副本数。升级完成之后,删除V1版本的RC,保留V2版本的RC,及实现滚动升级。
升级过程中,发生了错误中途退出时,可以选择继续升级。Kubernetes能够智能的判断升级中断之前的状态,然后紧接着继续执行升级。当然,也可以进行回退,命令如下:
$ kubectl rolling-update myweb myweb2 --update-period=10s --rollback
案例:我们原先rc版本v1,名字是myweb升级为myweb2,容器镜像从nginx113升级为115
[root@k8s-master k8s]# cat nginx-rc2.yaml apiVersion: v1 kind: ReplicationController metadata: name: myweb2 #rc的名字叫mtweb spec: replicas: 2 #副本数是2个,到时候会启动2个pod selector: #选择器 app: myweb2 # template: #pod启动模板 metadata: #RC会随机给pod生成2个名字 labels: app: myweb2 spec: containers: - name: myweb2 image: 192.168.23.146:5000/nginx:1.15 ports: - containerPort: 80
[root@k8s-master k8s]# kubectl rolling-update myweb -f nginx-rc2.yaml --update-period=10s
myweb是原先rc的名字;-f后面跟要滚动升级的新配置
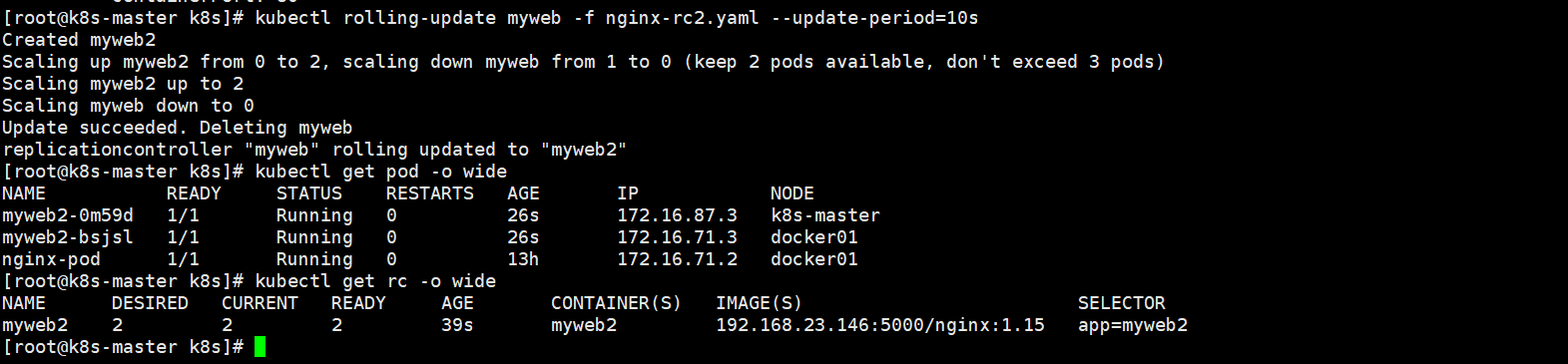
我们发现原先的副本是myweb的2个pod;现在更新成了myweb2的2个pod;容器的镜像版本也更新成了1.15版本.
回滚操作:myweb2----myweb;反向升级
[root@k8s-master k8s]# kubectl rolling-update myweb2 -f nginx-rc.yaml --update-period=10s
当升级到一半我们不想升级了ctrl+C结束后,我们再回退 2个rc的版本名称都存在才能这样操作(kubectl get rc -o wide)
[root@k8s-master k8s]# kubectl rolling-update myweb myweb2 --update-period=10s --rollback
rc扩缩容:
[root@k8s-master ~]# kubectl scale rc myweb --replicas=1 将副本数降低至1,扩容就是把数量增加即可


三\service资源
rc保证了pod的高可用,运行在docker中的业务,想要被外界访问,我们需要为它做端口映射才能被访问,那么运行在k8s中的容器,为什么不能直接为它做端口映射呢?
因为rc保证了pod的高可用性,一旦pod挂了就会重新起个pod,IP也会重新分配,这端口映射就要重新更改策略,service IP--VIP cluster IP
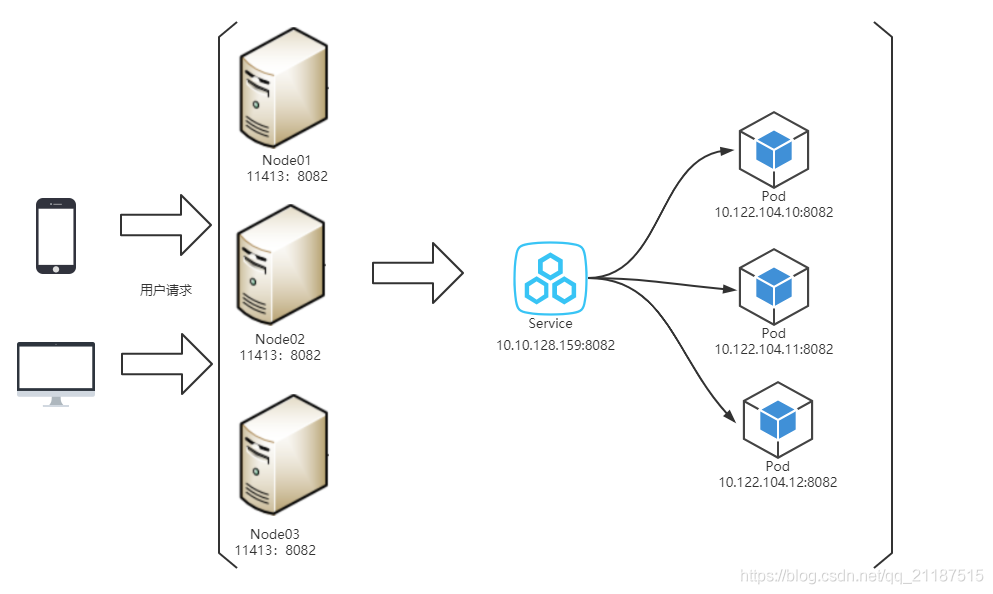
k8s暴露服务给外部访问有三种方式,NodePort、LoadBalane、Ingress三种暴露服务的方式,上图是用了NodePort的方式,缺点是服务一旦多起来,NodePort 在每个节点上开启的端口数量会极其庞大,难以维护
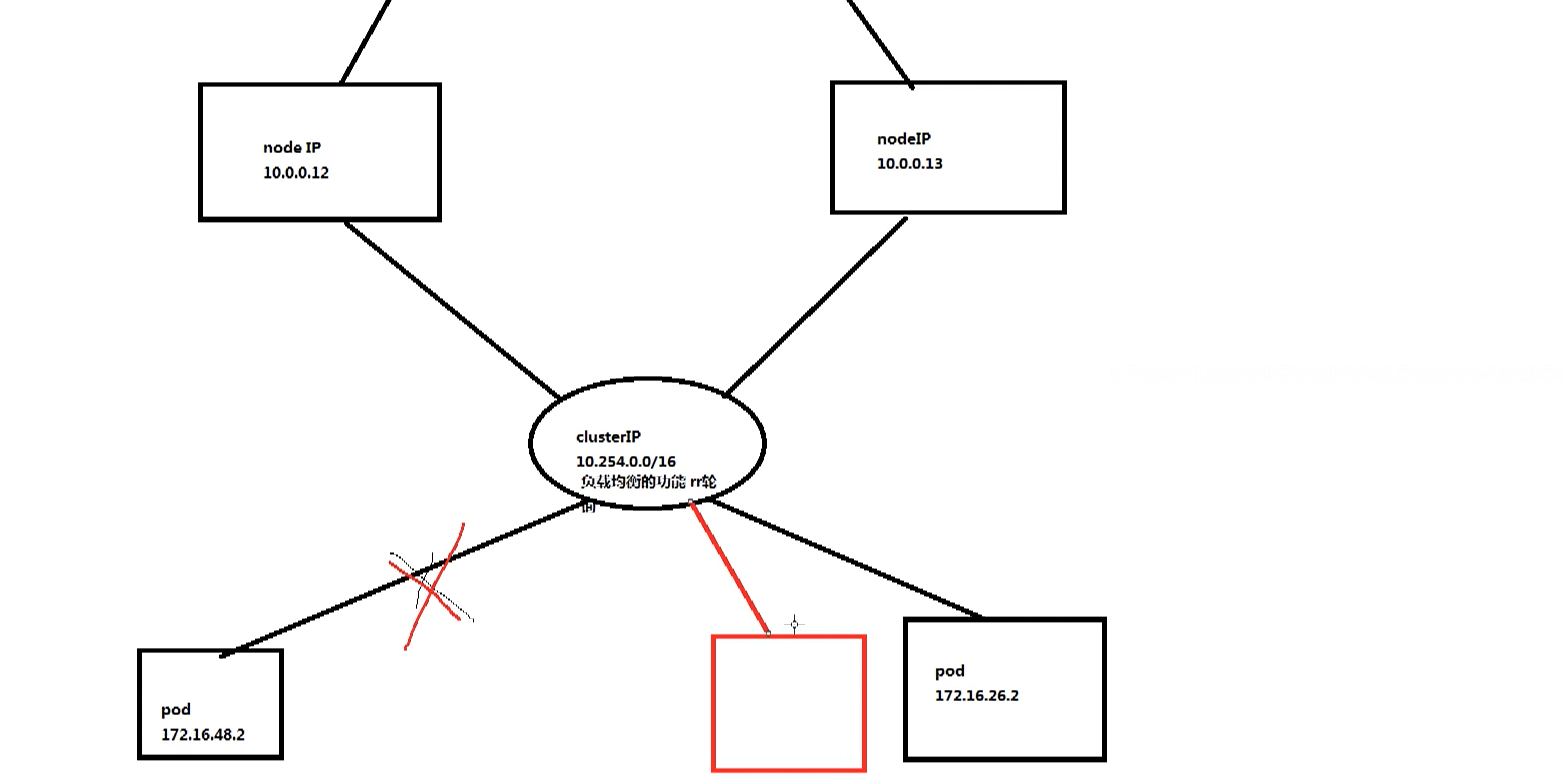
nodeIP端口会映射到cluser IP端口,访问node:端口就类似访问cluster的IP ,pod IP 的话我们创建一个pod,pod会自动关联到service上;cluster IP 是固定的,cluster提供了一个负载均衡
nodeip 宿主机IP kubectl describe node nodeA 在里面可以查IP,其实就是宿主机IP
clusterip 外部网络无法ping通,只有kubernetes集群内部访问使用;Service的IP地址,此为虚拟IP地址 专门的10网段
podip kubectl describe pod podA和容器共用一个IP,也是容器IP
创建一个service就会生成一个cluster IP
[root@k8s-master k8s]# kubectl get svc -o wide


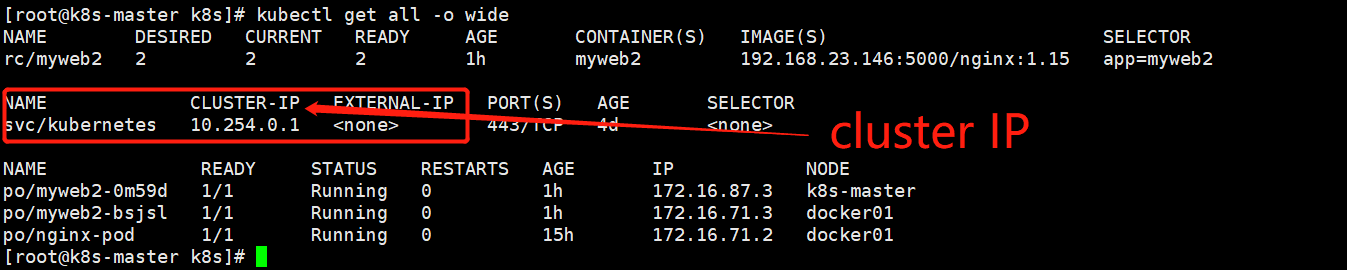
创建一个service:
创建一个service简称SVC: 访问的流程:宿主机IP:端口---nodeIP:port---clusterIP:port---podIP:端口(容器IP:端口) vim nginx-svc.yaml apiVersion: v1 kind: Service #资源类型 metadata: name: myweb-svc #资源名字 spec: type: NodePort #service类型是端口映射的方式 ports: - port: 80 #clusterIP(VIP)的端口 nodePort: 30000 #宿主机的端口 targetPort: 80 #pod IP的端口(也是容器端口) selector: app: myweb #标签选择器,我要为哪个标签下的pod做负载均衡
[root@k8s-master k8s]# kubectl create -f nginx-svc.yaml
[root@k8s-master k8s]# kubectl describe svc myweb-svc 由于myweb*的2个pod也是在标签myweb下,service的管理标签也是myweb,后端就会自动加进去
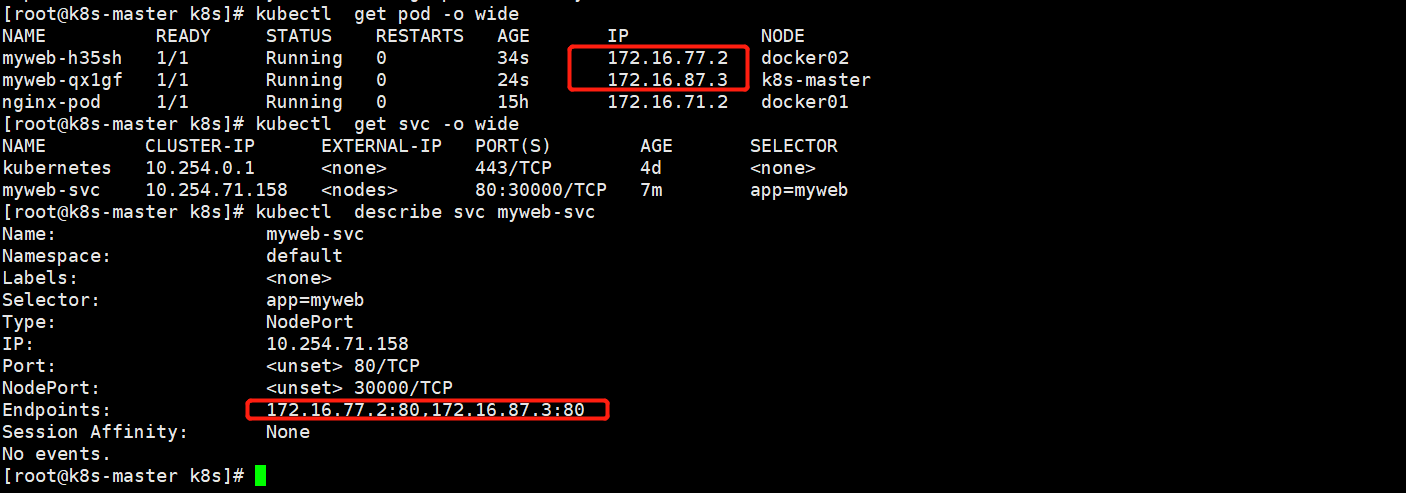
我们可以用192.168.23.145/144/146:30000去访问了,有多少个node节点,就可以用多少个IP来访问的,这是由于kube-proxy来实现的
service的服务自动发现
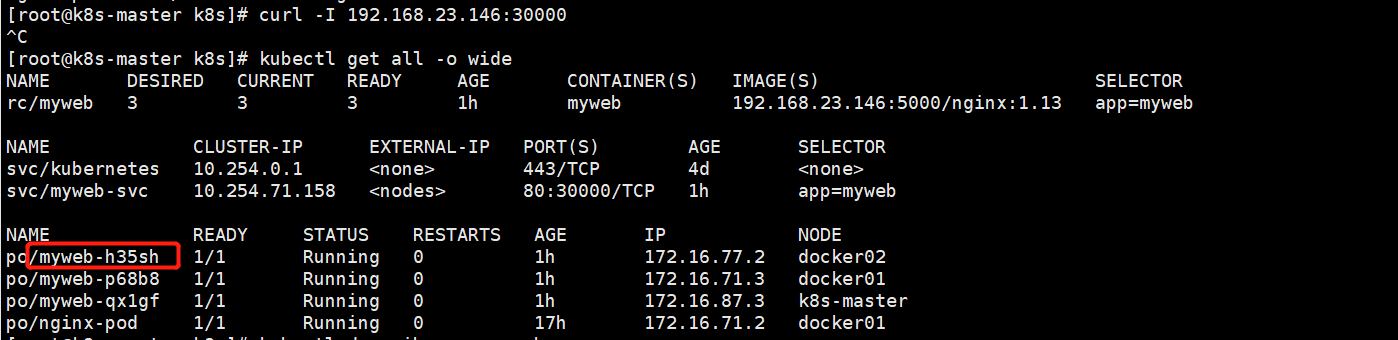
我们可以通过rc扩容个pod,发现service的终端IP也会多一个
[root@k8s-master k8s]# kubectl scale rc myweb --replicas=3

service的负载均衡会自动
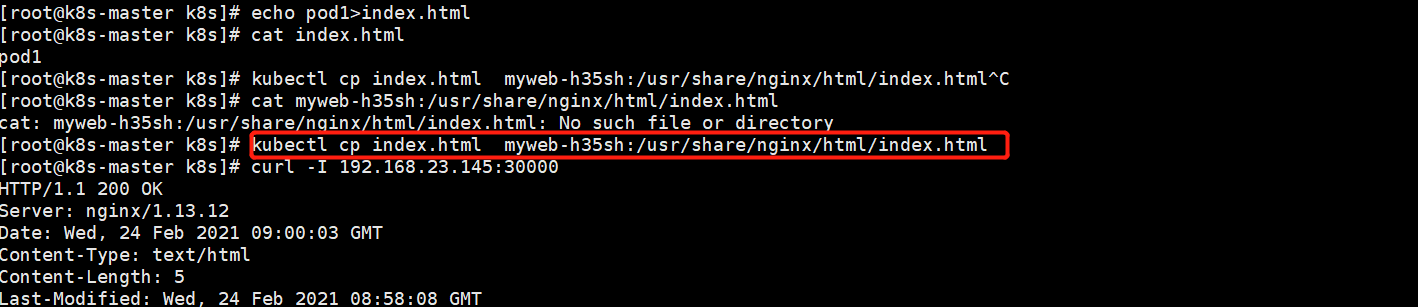
[root@k8s-master k8s]# kubectl cp index.html myweb-h35sh:/usr/share/nginx/html/index.html 把内容写到
[root@k8s-master k8s]# echo k8s-master>index.html
[root@k8s-master k8s]# kubectl cp index.html myweb-qx1gf:/usr/share/nginx/html/index.html

四deployment资源
这个也是保持pod的高可用和RC一样.deployment也是保证pod高可用的一种方式,明明已经有RC,为什么还要引入deployment呢?
因为deployment解决了RC的一个痛点,就是在升级的时候,svc的endpoint会出现短时间不通
创建一个deployment:
vi nginx-deploy.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: nginx-deployment spec: replicas: 3 template: metadata: labels: app: nginx spec: containers: - name: nginx image: 192.168.23.146:5000/nginx:1.13 ports: - containerPort: 80
[root@k8s-master k8s]# kubectl create -f nginx-deploy.yaml
[root@k8s-master k8s]# kubectl get all -o wide #查看所有资源
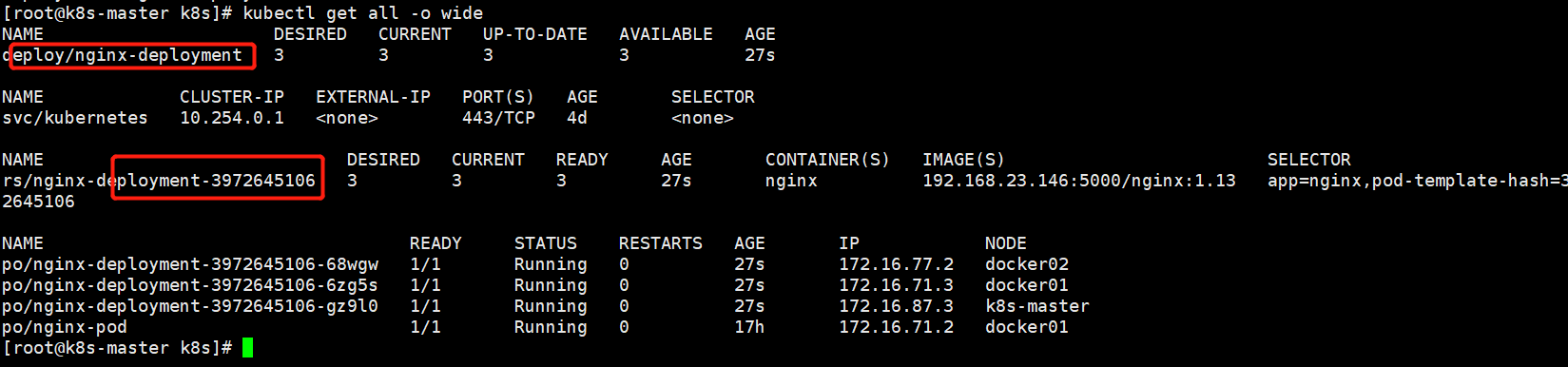
deployment简称deploy;从上图可以看出deployment先起一个rs(rs拥有了99%的rc功能,甚至比rc功能还多),rs再起三个pod
rs/nginx-deployment-3972645106 类型是rs,名字叫nginx*
[root@k8s-master k8s]# kubectl get rs -o wide

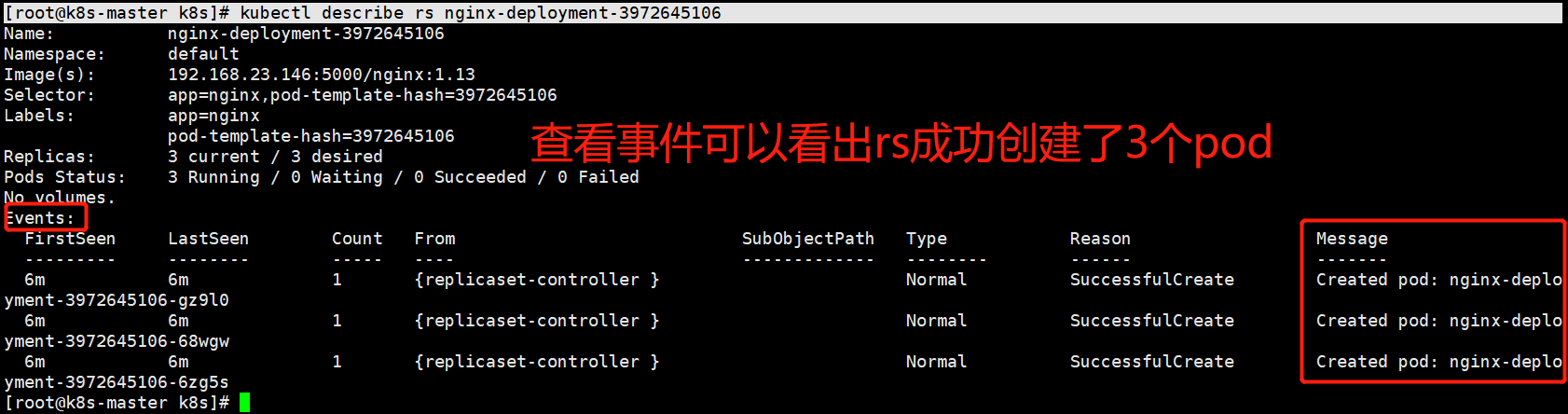
[root@k8s-master k8s]# kubectl describe rs nginx-deployment-3972645106
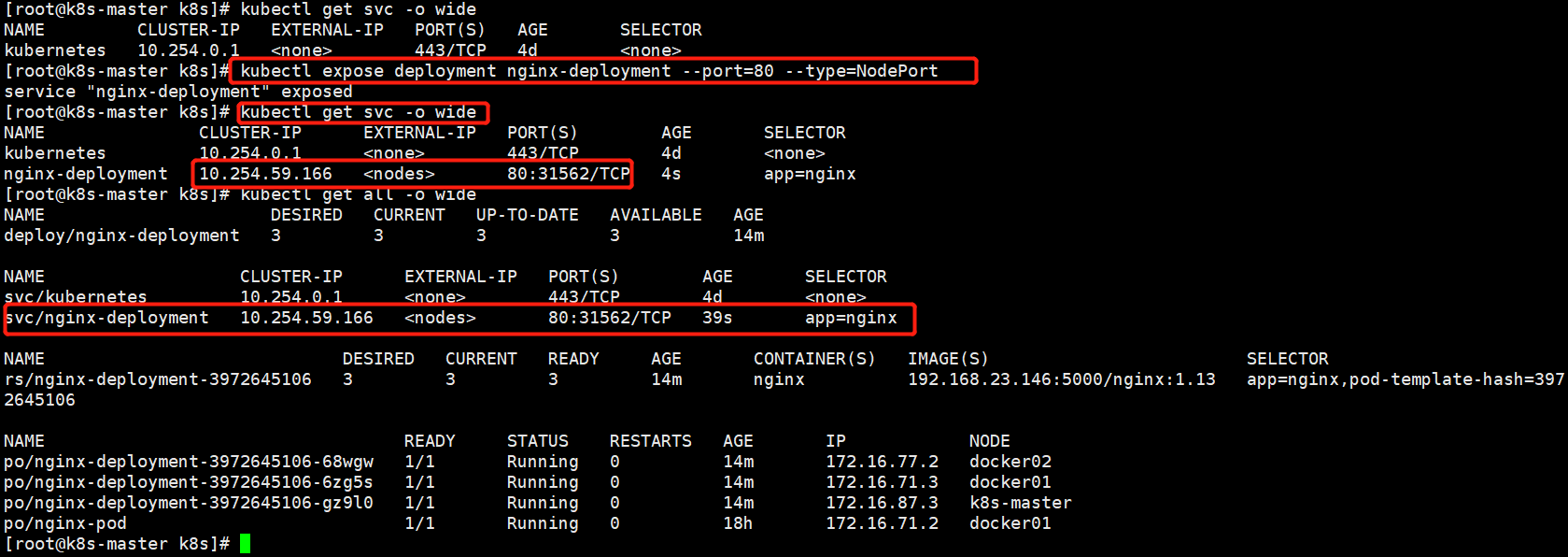
想要服务被外界访问就要关联service
[root@k8s-master k8s]# kubectl get svc -o wide

[root@k8s-master k8s]# kubectl expose deployment nginx-deployment --port=80 --type=NodePort 通过命令行创建service。或者yaml文件也行
--port=80 #cluster-IP的端口,vip就是cluster-ip
--type=NodePort #类型是nodeport,端口转发模式
deployment nginx-deployment #代表给deploy的nginx-deployment关联
pod的标签要和svc的标签一样,否则容易造成不通
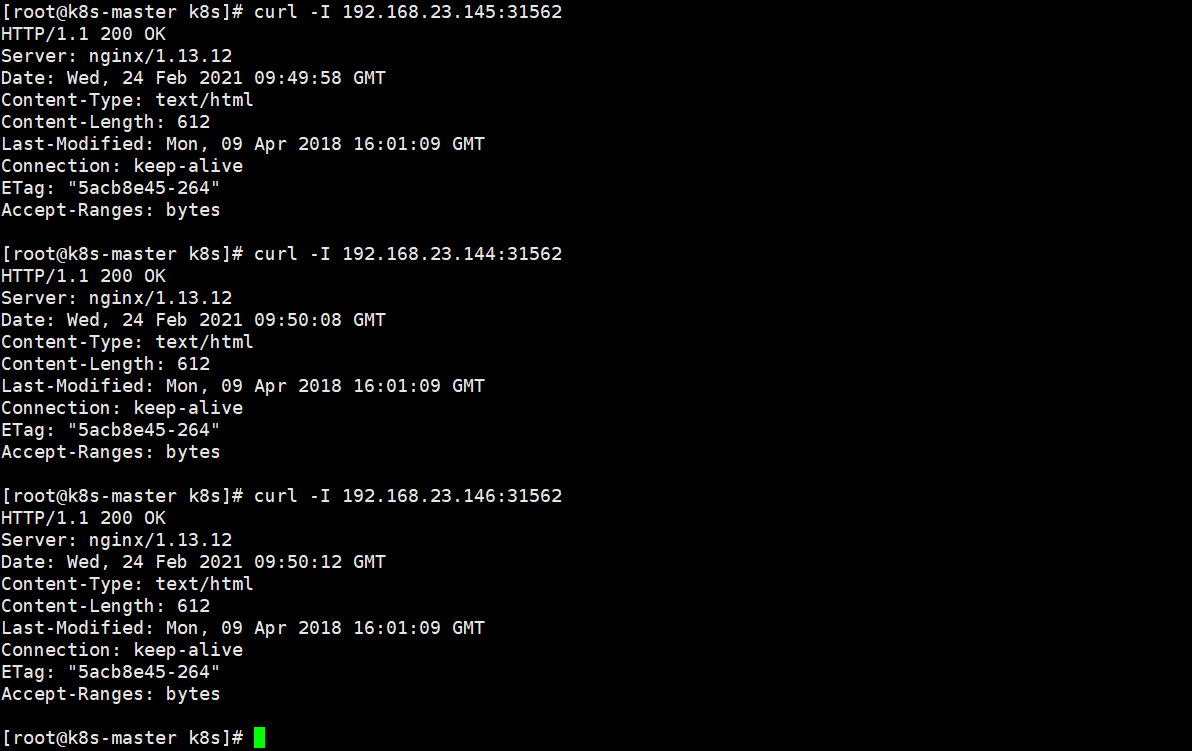
测试:curl -I 任意一个node:31562
deployment升级
[root@k8s-master ~]# kubectl edit deploy nginx-deployment 直接更改配置文件,将原来的nginx1.13改成nginx1.15

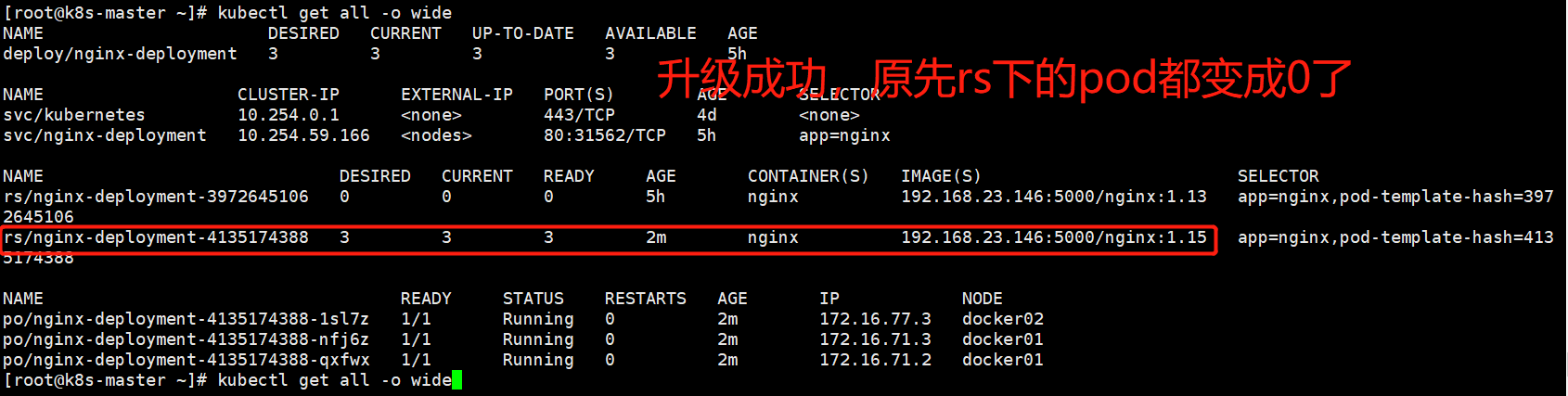

deployment回滚
[root@k8s-master ~]# kubectl rollout undo deployment nginx-deployment(deploy名称)
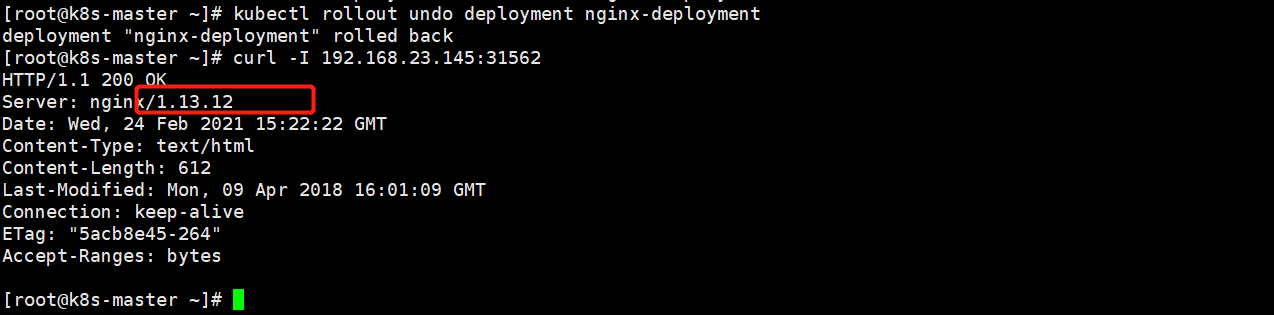

[root@k8s-master ~]# kubectl rollout history deployment nginx-deployment #查看历史回滚版本 通过yaml文件发布的,查看回滚历史版本下面没有内容.通过命令行看就有了

deployment版本发布,通过命令行.上面我们是通过yaml文件操作的,这一次我们通过命令行
[root@k8s-master ~]# kubectl delete deployment nginx-deployment #先删除原先的deploy版本
[root@k8s-master ~]# kubectl run nginx --image=192.168.23.146:5000/nginx:1.13 --replicas=3 --record发布deploy版本
nginx--这是deploy的名字
[root@k8s-master ~]# kubectl rollout history deployment nginx

[root@k8s-master ~]# kubectl get all -o wide
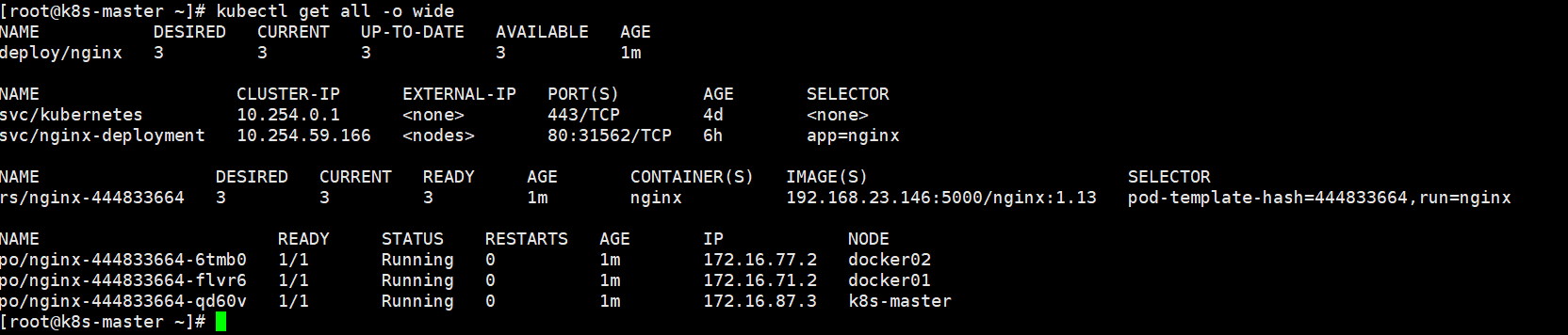
版本升级
kubectl set image deploy nginx(deploy的名字) nginx=192.168.23.146:5000/nginx:1.15(镜像名称和版本)
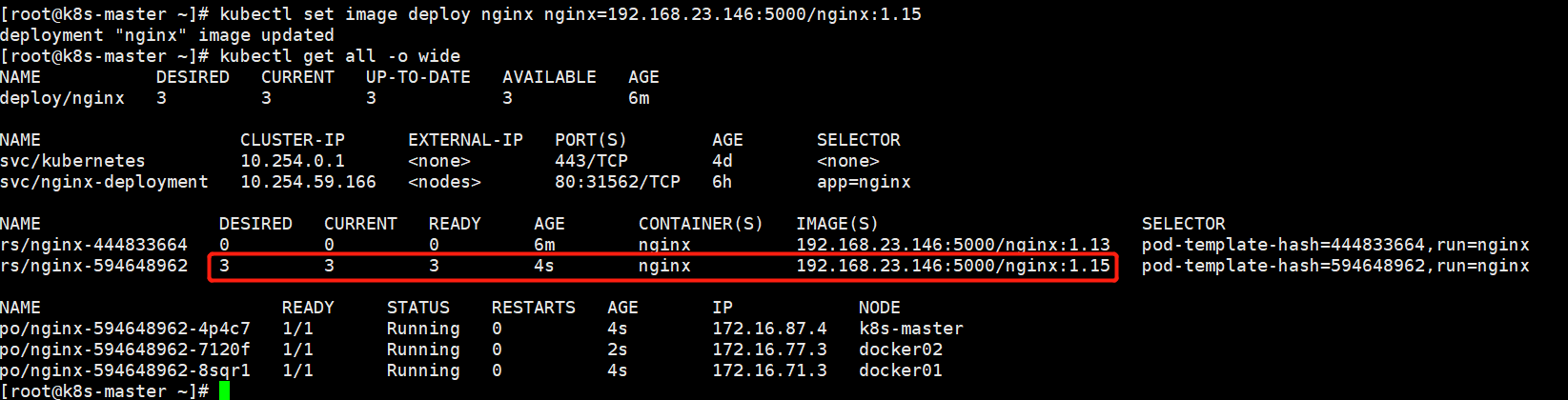
[root@k8s-master ~]# kubectl rollout history deployment nginx 查看历史版本
[root@k8s-master ~]# kubectl rollout undo deployment nginx --to-revision=1 回滚版本到第一个
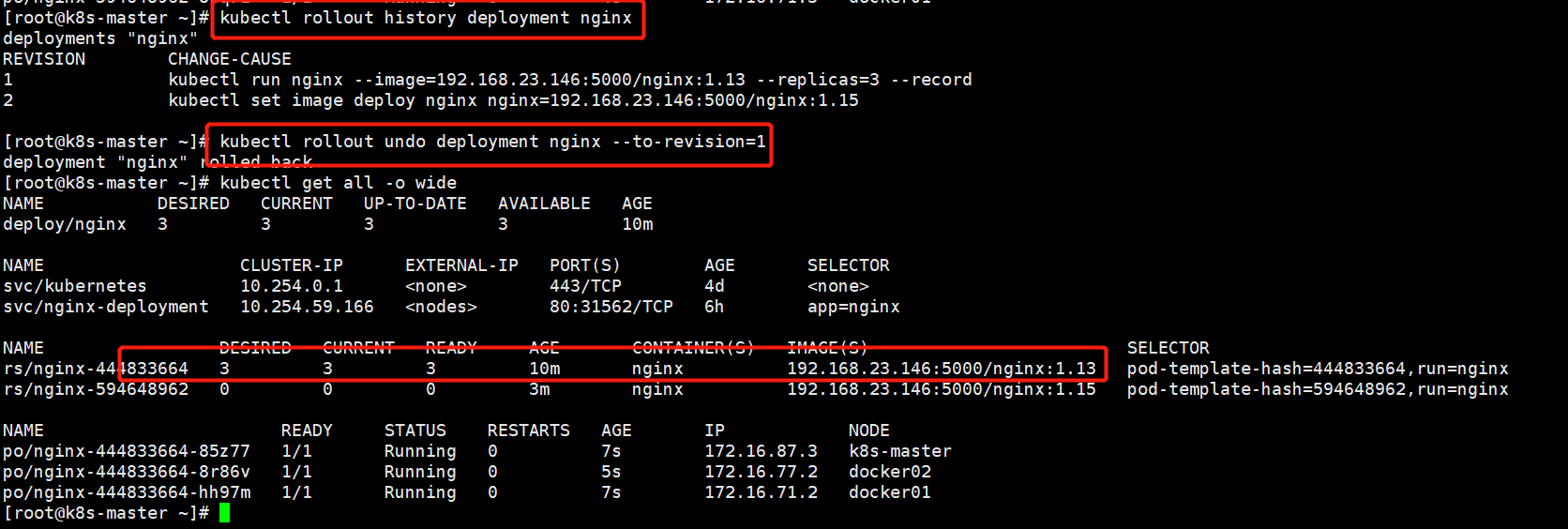
deploy比rc好用,也不依赖配置文件,rc依赖配置文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号