
每日一问之“为什么重写equals()之后也要重写hashCode()?”
Java为什么重写equals()之后也要重写hashCode()?
首先我们先搞明白这俩方法是做什么用的,talk is cheap,show me code,我们直接看源码。这两个方法都是Object类所带的方法:
方法的作用
hashCode()
源码如下:
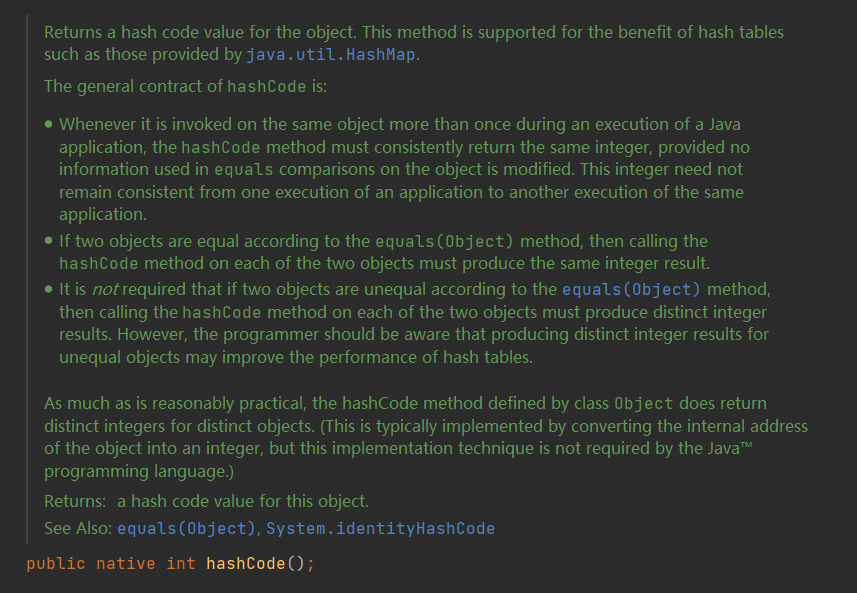
可以看到这是一个native方法,如果不知道native方法是什么的同学可以先简单理解为用其他语言(C/C++)实现的方法,之后我会用一篇文章谈一下native方法。
翻译一下就是说:
返回对象的哈希码值。 支持这种方法是为了散列表,如
HashMap提供的那样 。
hashCode的总契约(应该遵守的规定)是: (1)在Java应用程序执行期间,只要在同一对象上多次调用
hashCode方法,只要对象的等于比较中使用的信息未被修改,该方法就必须一致地返回相同的整数。从应用程序的一次执行到同一应用程序的另一次执行,这个整数无需保持一致。 (2)如果根据
equals(Object)方法两个对象相等,则在两个对象中的每个对象上调用hashCode方法必须产生相同的整数结果。 (3)不要求如果两个对象根据
equals(java.lang.Object)方法不相等,那么在两个对象中的每个对象上调用hashCode方法必须产生不同的整数结果。 但是,程序员应该意识到,为不等对象生成不同的整数结果可能会提高哈希表的性能。 尽可能多的合理实用,由类别Object定义的hashCode方法确实为不同对象返回不同的整数。 (这通常通过将对象的内部地址转换为整数来实现,但Java的编程语言不需要此实现技术。)
我再翻译一下就是,hashCode的三条规范中,第一条主要侧重于在同一个Java应用程序中同一个对象的多次hashCode()必须一致,第二条比较重要,如果说equals()相等的俩对象,hashCode()后得到的整数值也必须一致(为什么一定要这样呢?后面我会阐明),第三条表明,hashCode()契约不强制要求equals()不同的俩对象hashCode()也不一致(为什么不强制要求呢?)。
最后一段话表明,hashCode()是个native方法,该方法通常是由将对象的内部地址转换为整数来实现,这表示hashCode往往以内部地址作为一个输入源进行转换的。
equals()
先看源码:
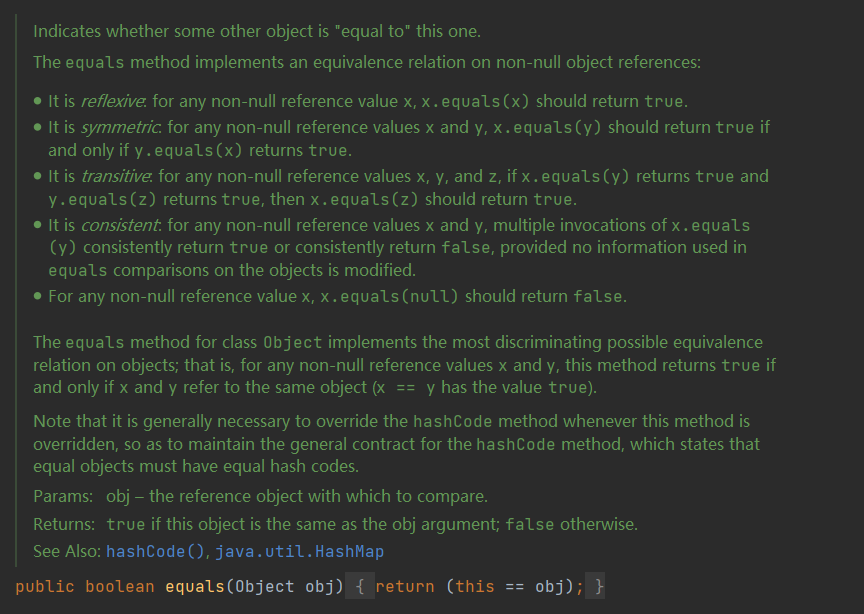
翻译一下:
指明其他对象是否“等于”此对象。
equals方法在非空对象引用上实现等价关系: (1)自反性 :对于任何非空的参考值
x,x.equals(x)应该返回true。 (2)它是对称的 :对于任何非空引用值
x和y,x.equals(y)应该返回true当且仅当y.equals(x)回报true。 (3)传递性 :对于任何非空引用值
x,y和z,如果x.equals(y)回报true个y.equals(z)回报true,然后x.equals(z)应该返回true。 (4)它是一致的:对于任何非空引用值x和y,多次调用x.equals(y)都会一致返回true或一致返回false,前提是在对象的等于比较中使用的信息没有被修改。
(5)对于任何非空的参考值
x,x.equals(null)应该返回false。
类Object的equals方法在对象上实现了最有区别的可能等价关系;也就是说,对于任何非空引用值x和y,当且仅当x和y引用同一对象(x==y的值为true)时,此方法才返回true。 请注意,无论何时覆盖该方法,通常需要覆盖
hashCode方法,以便维护hashCode方法的通用契约,该方法规定相等的对象必须具有相等的哈希码。
我提一下要注意的几个点,等价关系的5个性质我们可以很容易的推出,最要注意的就是倒数的两段话,它是这么说的 “类Object的equals方法在对象上实现了最有区别的可能等价关系” ,也就是说Object类实现的equals是粗粒度区分的,只有引用相等时(源码中用的是==判断地址相等)才认为相等,否则返回不相等。那么这个粗粒度的区分方式也是几个类(String,Integer等包装类)要重写equals的原因了。
举个例子,我们有理由认为String a = new String("abc")和String b = new String("abc"),这俩个字符串对象时相等的,但是如果我们直接使用等于号的话:
String a = new String("abc");
String b = new String("abc");
System.out.println(a == b);//false
可以看出是false,a == b就相当于没有重写Object的equals方法,那么String类内部是重写了equals()方法,源码如下:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
可以看出,重写的方法会一个一个判断俩个char数组是否相等,从而确定是否相等。这样就避免了实际上俩char数组都相等的String对象判断下来不相等的情况。
具体剖析
从hashCode()源码中可以看出,该函数主要是服务于各种散列表结构,比如HashMap,它通过将地址转换成一个整数值来进行哈希操作(具体细节并不是Java语言考虑的),对比equals()方法,该未重写的方法也是基于俩个引用对象的地址比较实现的。若俩方法都未被重写,散列表是可以很好的工作的,散列表最应该遵守的一个规矩就是,假如俩个对象是相等的(以equals()方法的结果为准),那么必须是散列到同一个桶上(就是hashCode()结果一致),因为这是由hashCode()契约决定的,哈希结果不一致的两个对象,肯定不是同一个对象。
那假如说我重写了equals()方法不重写hashCode()方法,会发生什么情况?我举个例子:
public class Student{
private String id;
private String name;
private Integer age;
public Student(String id, String name, Integer age) {
this.id = id;
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return Objects.equals(student.id, id) && Objects.equals(student.name, name);
}
}
我们重写equals()方法,我们认为只要id和name一致我们就认为俩对象相等,不关age的事情。下面我们用一个HashMap来存Student对象:
public static void main(String[] args) {
Student a = new Student("1","张三",20);
Student b = new Student("1","张三",16);
HashMap<Student,String> map = new HashMap<>();
map.put(a,"test");
map.put(b,"test2");
for (Map.Entry<Student, String> entry : map.entrySet()) {
System.out.println(entry.getKey()+" "+entry.getValue());
}
}
结果如下所示:
test.Student@7ea987ac test2
test.Student@4b67cf4d test
可以看到,理论上来说,只能有一个key,并且其键值会被我们修改成test2,但是却本应该相等的两个对象作为键存在于同一个散列表中的不同位置,这违反了散列表的规则。那么我们如何改才能实现要求呢?它山之石可以攻玉,我们不妨看看jdk里面重写了equals()方法的String类是如何重写hashCode()方法的:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
可以看到,他从String对象的内部的char数组入手,因为地址是否相同并不能作为俩String是否相等的唯一标准,所以它参考了自己的equals()重写策略,从char数组入手进行哈希值的构建,它把每个char都提出来之后加上31*h,这样可以确保char数组相等的String对象,它们哈希获得的哈希值也必然相等。
借助它的思路,如果说我们想让id和name相等Student对象的哈希值相等的话我们可以这么设计:
@Override
public int hashCode() {
return Objects.hash(id, name);
}
这个是idea自带的hashCode()重写模板,选择需要将哪些字段作为哈希参考对象,之后调用Objects.hash(...args)即可,该方法具体如下:
public static int hash(Object... values) {
return Arrays.hashCode(values);
}
接着Arrays.hashCode(values)方法如下:
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}
可以看到,和String类的hashCode()重写有相似之处,都是用31*result之后再加上对象的hashCode()值。现在我们再来测试一下刚刚的操作(我重写了一下toString()方法):
Student{id='1', name='张三', age=20} test2
可以看到由于哈希得到的值一致,并且equals也是相等的,age为16的Student对象就压根没加到map中去。但是更新了键值为test2,这是符合我们的逻辑的。
总结下来就是,重写equals()方法之后为了不违反hashCode()函数的契约,即equals结果相等的俩对象的哈希值必须是一致的,所以要重写hashCode(),使得equals相等的俩对象哈希值也必须相等!
思考一下
重写hashCode()方法的话需要重写equals()方法吗?
不妨思考一下哈希值的作用,作用就是在散列表结构中,更快地区分出对象是否一致,假如哈希值所对应的桶不存在对象,那么就可以铁定的判断散列表中没有这个对象,假如对应的桶内存在有对象,考虑到有哈希冲突的存在,所以需要用equals一个一个比较判断是否存在这个对象。所以假设hashCode()都散列到一个位置了,其实也没有关系,因为有equals()方法来帮我们兜底。
所以综上,重写hashCode()方法的话不一定需要重写equals()方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号