

Django REST framework
Web应用模式
在开发Web应用中,有两种应用模式:
- 前后端不分离
- 前后端分

1 前后端不分离

在前后端不分离的应用模式中,前端页面看到的效果都是由后端控制,由后端渲染页面或重定向,也就是后端需要控制前端的展示,前端与后端的耦合度很高。
这种应用模式比较适合纯网页应用,但是当后端对接App时,App可能并不需要后端返回一个HTML网页,而仅仅是数据本身,所以后端原本返回网页的接口不再适用于前端App应用,为了对接App后端还需再开发一套接口。
2 前后端分离
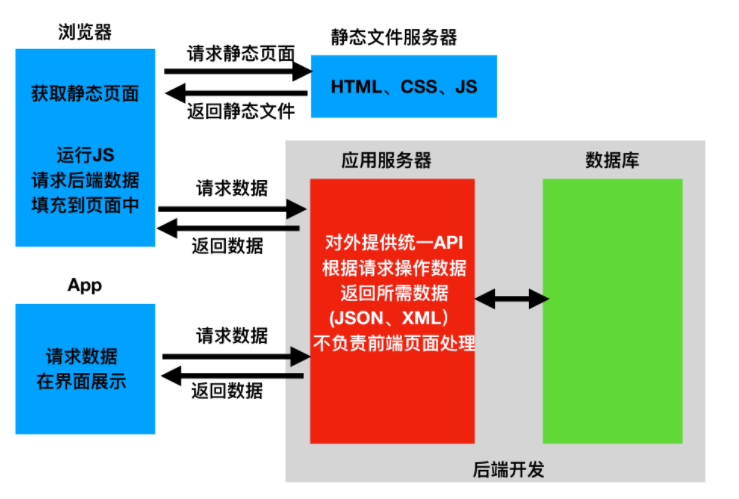
在前后端分离的应用模式中,后端仅返回前端所需的数据,不再渲染HTML页面,不再控制前端的效果。至于前端用户看到什么效果,从后端请求的数据如何加载到前端中,都由前端自己决定,网页有网页的处理方式,App有App的处理方式,但无论哪种前端,所需的数据基本相同,后端仅需开发一套逻辑对外提供数据即可。
在前后端分离的应用模式中 ,前端与后端的耦合度相对较低。
在前后端分离的应用模式中,我们通常将后端开发的每个视图都称为一个接口,或者API,前端通过访问接口来对数据进行增删改查。
RESTful设计方法
1. 域名
应该尽量将API部署在专用域名之下。
https://api.example.com
如果确定API很简单,不会有进一步扩展,可以考虑放在主域名下。
https://example.org/api/
2. 版本(Versioning)
应该将API的版本号放入URL。
http://www.example.com/app/1.0/foo http://www.example.com/app/1.1/foo http://www.example.com/app/2.0/foo
另一种做法是,将版本号放在HTTP头信息中,但不如放入URL方便和直观。Github采用这种做法。
因为不同的版本,可以理解成同一种资源的不同表现形式,所以应该采用同一个URL。版本号可以在HTTP请求头信息的Accept字段中进行区分(参见Versioning REST Services):
Accept: vnd.example-com.foo+json; version=1.0 Accept: vnd.example-com.foo+json; version=1.1 Accept: vnd.example-com.foo+json; version=2.0
3. 路径(Endpoint)
路径又称"终点"(endpoint),表示API的具体网址,每个网址代表一种资源(resource)
(1) 资源作为网址,只能有名词,不能有动词,而且所用的名词往往与数据库的表名对应。
举例来说,以下是不好的例子:
/getProducts /listOrders /retreiveClientByOrder?orderId=1
对于一个简洁结构,你应该始终用名词。 此外,利用的HTTP方法可以分离网址中的资源名称的操作。
GET /products :将返回所有产品清单 POST /products :将产品新建到集合 GET /products/4 :将获取产品 4 PATCH(或)PUT /products/4 :将更新产品 4
(2) API中的名词应该使用复数。无论子资源或者所有资源。
举例来说,获取产品的API可以这样定义
获取单个产品:http://127.0.0.1:8080/AppName/rest/products/1 获取所有产品: http://127.0.0.1:8080/AppName/rest/products
3. HTTP动词
对于资源的具体操作类型,由HTTP动词表示。
常用的HTTP动词有下面四个(括号里是对应的SQL命令)。
- GET(SELECT):从服务器取出资源(一项或多项)。
- POST(CREATE):在服务器新建一个资源。
- PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
- DELETE(DELETE):从服务器删除资源。
还有三个不常用的HTTP动词。
- PATCH(UPDATE):在服务器更新(更新)资源(客户端提供改变的属性)。
- HEAD:获取资源的元数据。
- OPTIONS:获取信息,关于资源的哪些属性是客户端可以改变的。
下面是一些例子。
GET /zoos:列出所有动物园 POST /zoos:新建一个动物园(上传文件) GET /zoos/ID:获取某个指定动物园的信息 PUT /zoos/ID:更新某个指定动物园的信息(提供该动物园的全部信息) PATCH /zoos/ID:更新某个指定动物园的信息(提供该动物园的部分信息) DELETE /zoos/ID:删除某个动物园 GET /zoos/ID/animals:列出某个指定动物园的所有动物 DELETE /zoos/ID/animals/ID:删除某个指定动物园的指定动物
4. 过滤信息(Filtering)
如果记录数量很多,服务器不可能都将它们返回给用户。API应该提供参数,过滤返回结果。
下面是一些常见的参数。
?limit=10:指定返回记录的数量 ?offset=10:指定返回记录的开始位置。 ?page=2&per_page=100:指定第几页,以及每页的记录数。 ?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序。 ?animal_type_id=1:指定筛选条件
参数的设计允许存在冗余,即允许API路径和URL参数偶尔有重复。比如,GET /zoos/ID/animals 与 GET /animals?zoo_id=ID 的含义是相同的。
6. 状态码(Status Codes)
服务器向用户返回的状态码和提示信息,常见的有以下一些(方括号中是该状态码对应的HTTP动词)。
- 200 OK - [GET]:服务器成功返回用户请求的数据
- 201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。
- 202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务)
- 204 NO CONTENT - [DELETE]:用户删除数据成功。
- 400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作
- 401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。
- 403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。
- 404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。
- 406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。
- 410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。
- 422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。
- 500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功。
7. 错误处理(Error handling)
如果状态码是4xx,服务器就应该向用户返回出错信息。一般来说,返回的信息中将error作为键名,出错信息作为键值即可。
{ error: "Invalid API key" }
8. 返回结果
针对不同操作,服务器向用户返回的结果应该符合以下规范。
9. 其他
GET /collection:返回资源对象的列表(数组) GET /collection/resource:返回单个资源对象 POST /collection:返回新生成的资源对象 PUT /collection/resource:返回完整的资源对象 PATCH /collection/resource:返回完整的资源对象 DELETE /collection/resource:返回一个空文档
服务器返回的数据格式,应该尽量使用JSON,避免使用XML。
使用Django开发REST 接口
我们以在Django框架中使用的图书英雄案例来写一套支持图书数据增删改查的REST API接口,来理解REST API的开发。
在此案例中,前后端均发送JSON格式数据。
测试
# views.py from datetime import datetime class BooksAPIVIew(View): """ 查询所有图书、增加图书 """ def get(self, request): """ 查询所有图书 路由:GET /books/ """ queryset = BookInfo.objects.all() book_list = [] for book in queryset: book_list.append({ 'id': book.id, 'btitle': book.btitle, 'bpub_date': book.bpub_date, 'bread': book.bread, 'bcomment': book.bcomment, 'image': book.image.url if book.image else '' }) return JsonResponse(book_list, safe=False) def post(self, request): """ 新增图书 路由:POST /books/ """ json_bytes = request.body json_str = json_bytes.decode() book_dict = json.loads(json_str) # 此处详细的校验参数省略 book = BookInfo.objects.create( btitle=book_dict.get('btitle'), bpub_date=datetime.strptime(book_dict.get('bpub_date'), '%Y-%m-%d').date() ) return JsonResponse({ 'id': book.id, 'btitle': book.btitle, 'bpub_date': book.bpub_date, 'bread': book.bread, 'bcomment': book.bcomment, 'image': book.image.url if book.image else '' }, status=201) class BookAPIView(View): def get(self, request, pk): """ 获取单个图书信息 路由: GET /books/<pk>/ """ try: book = BookInfo.objects.get(pk=pk) except BookInfo.DoesNotExist: return HttpResponse(status=404) return JsonResponse({ 'id': book.id, 'btitle': book.btitle, 'bpub_date': book.bpub_date, 'bread': book.bread, 'bcomment': book.bcomment, 'image': book.image.url if book.image else '' }) def put(self, request, pk): """ 修改图书信息 路由: PUT /books/<pk> """ try: book = BookInfo.objects.get(pk=pk) except BookInfo.DoesNotExist: return HttpResponse(status=404) json_bytes = request.body json_str = json_bytes.decode() book_dict = json.loads(json_str) # 此处详细的校验参数省略 book.btitle = book_dict.get('btitle') book.bpub_date = datetime.strptime(book_dict.get('bpub_date'), '%Y-%m-%d').date() book.save() return JsonResponse({ 'id': book.id, 'btitle': book.btitle, 'bpub_date': book.bpub_date, 'bread': book.bread, 'bcomment': book.bcomment, 'image': book.image.url if book.image else '' }) def delete(self, request, pk): """ 删除图书 路由: DELETE /books/<pk>/ """ try: book = BookInfo.objects.get(pk=pk) except BookInfo.DoesNotExist: return HttpResponse(status=404) book.delete() return HttpResponse(status=204) # urls.py urlpatterns = [ url(r'^books/$', views.BooksAPIVIew.as_view()), url(r'^books/(?P<pk>\d+)/$', views.BookAPIView.as_view()) ]
使用Postman测试上述接口
1) 获取所有图书数据
GET 方式访问 http://127.0.0.1:8000/books/, 返回状态码200,数据如下
[ { "id": 1, "btitle": "射雕英雄传", "bpub_date": "1980-05-01", "bread": 12, "bcomment": 34, "image": "" }, { "id": 2, "btitle": "天龙八部", "bpub_date": "1986-07-24", "bread": 36, "bcomment": 40, "image": "" }, { "id": 3, "btitle": "笑傲江湖", "bpub_date": "1995-12-24", "bread": 20, "bcomment": 80, "image": "" }, { "id": 4, "btitle": "雪山飞狐", "bpub_date": "1987-11-11", "bread": 58, "bcomment": 24, "image": "" }, { "id": 5, "btitle": "西游记", "bpub_date": "1988-01-01", "bread": 10, "bcomment": 10, "image": "booktest/xiyouji.png" }, { "id": 6, "btitle": "水浒传", "bpub_date": "1992-01-01", "bread": 10, "bcomment": 11, "image": "" }, { "id": 7, "btitle": "红楼梦", "bpub_date": "1990-01-01", "bread": 0, "bcomment": 0, "image": "" } ]
2)获取单一图书数据
GET 访问 http://127.0.0.1:8000/books/5/ ,返回状态码200, 数据如下
{ "id": 5, "btitle": "西游记", "bpub_date": "1988-01-01", "bread": 10, "bcomment": 10, "image": "booktest/xiyouji.png" }
GET 访问http://127.0.0.1:8000/books/100/,返回状态码404
3)新增图书数据
POST 访问http://127.0.0.1:8000/books/,发送JSON数据:
{ "btitle": "三国演义", "bpub_date": "1990-02-03" }
返回状态码201,数据如下
{ "id": 8, "btitle": "三国演义", "bpub_date": "1990-02-03", "bread": 0, "bcomment": 0, "image": "" }
4)修改图书数据
PUT 访问http://127.0.0.1:8000/books/8/,发送JSON数据:
{ "btitle": "三国演义(第二版)", "bpub_date": "1990-02-03" }
返回状态码200,数据如下
{ "id": 8, "btitle": "三国演义(第二版)", "bpub_date": "1990-02-03", "bread": 0, "bcomment": 0, "image": "" }
5)删除图书数据
DELETE 访问http://127.0.0.1:8000/books/8/,返回204状态码
明确REST接口开发的核心任务
分析一下上节的案例,可以发现,在开发REST API接口时,视图中做的最主要有三件事:
- 将请求的数据(如JSON格式)转换为模型类对象
- 操作数据库
- 将模型类对象转换为响应的数据(如JSON格式)
序列化Serialization
维基百科中对于序列化的定义:
序列化(serialization)在计算机科学的资料处理中,是指将数据结构或物件状态转换成可取用格式(例如存成档案,存于缓冲,或经由网络中传送),以留待后续在相同或另一台计算机环境中,能恢复原先状态的过程。依照序列化格式重新获取字节的结果时,可以利用它来产生与原始物件相同语义的副本。对于许多物件,像是使用大量参照的复杂物件,这种序列化重建的过程并不容易。面向对象中的物件序列化,并不概括之前原始物件所关联的函式。这种过程也称为物件编组(marshalling)。从一系列字节提取数据结构的反向操作,是反序列化(也称为解编组, deserialization, unmarshalling)。
序列化在计算机科学中通常有以下定义:
在数据储存与传送的部分是指将一个对象)存储至一个储存媒介,例如档案或是记亿体缓冲等,或者透过网络传送资料时进行编码的过程,可以是字节或是XML等格式。而字节的或XML编码格式可以还原完全相等的对象)。这程序被应用在不同应用程序之间传送对象),以及服务器将对象)储存到档案或数据库。相反的过程又称为反序列化。
简而言之,我们可以将序列化理解为:
将程序中的一个数据结构类型转换为其他格式(字典、JSON、XML等),例如将Django中的模型类对象装换为JSON字符串,这个转换过程我们称为序列化。
如:
queryset = BookInfo.objects.all() book_list = [] # 序列化 for book in queryset: book_list.append({ 'id': book.id, 'btitle': book.btitle, 'bpub_date': book.bpub_date, 'bread': book.bread, 'bcomment': book.bcomment, 'image': book.image.url if book.image else '' }) return JsonResponse(book_list, safe=False)
反之,将其他格式(字典、JSON、XML等)转换为程序中的数据,例如将JSON字符串转换为Django中的模型类对象,这个过程我们称为反序列化。
如:
json_bytes = request.body json_str = json_bytes.decode() # 反序列化 book_dict = json.loads(json_str) book = BookInfo.objects.create( btitle=book_dict.get('btitle'), bpub_date=datetime.strptime(book_dict.get('bpub_date'), '%Y-%m-%d').date() )
我们可以看到,在开发REST API时,视图中要频繁的进行序列化与反序列化的编写。
总结
在开发REST API接口时,我们在视图中需要做的最核心的事是:
-
将数据库数据序列化为前端所需要的格式,并返回;
-
将前端发送的数据反序列化为模型类对象,并保存到数据库中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号