
伪共享 FalseSharing (CacheLine,MESI) 浅析以及解决方案
起因
在阅读百度的发号器 uid-generator 源码的过程中,发现了一段很奇怪的代码:
/** * Represents a padded {@link AtomicLong} to prevent the FalseSharing problem<p> * * The CPU cache line commonly be 64 bytes, here is a sample of cache line after padding:<br> * 64 bytes = 8 bytes (object reference) + 6 * 8 bytes (padded long) + 8 bytes (a long value) * * @author yutianbao */ public class PaddedAtomicLong extends AtomicLong { private static final long serialVersionUID = -3415778863941386253L; /** Padded 6 long (48 bytes) */ public volatile long p1, p2, p3, p4, p5, p6 = 7L; /** * Constructors from {@link AtomicLong} */ public PaddedAtomicLong() { super(); } public PaddedAtomicLong(long initialValue) { super(initialValue); } }
这里面有6个看上去毫无作用的volatile long变量(标红)。如果这是我自己写的代码,我肯定会认为是我自己手抖写多了。
但是作为百度的发号器,开源了这么久,如果是手抖早被fix了。肯定还是有深意的。于是阅读了一些类注释,看到了这句话:
to prevent the FalseSharing problem
果然,这几个变量不是毫无作用的,是为了解决FalseSharing问题。
但是转念一想,我好像不知道什么是FalseSharing?解决了一个问题,又陷入了另一个更大的问题。
于是就上网查了很多资料,阅读了很多博客,算是对FalseSharing有了一个初步的了解。在这里写出来也为了希望能帮到有同样困惑的人。
背景知识
要说清楚FalseSharing,不是一两句话能做到的事,有一些必须了解的背景知识需要补充一下。
计算机存储架构
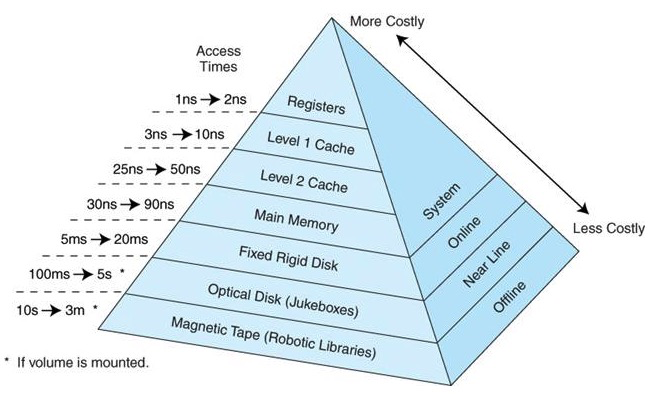
上图展示的是不同层级的硬件和cpu之间的交互延迟。越靠近CPU,速度越快。
计算机运行时,CPU是执行指令的地方,而指令会需要一些数据的读写。程序的运行时数据都是存放在主存的,而主存又特别慢(相对),所以为了解决CPU和主存之间的速度差异,现代计算机都引入了高速缓存(L1L2L3)。
现代计算机对缓存/内存的设计一般如下:
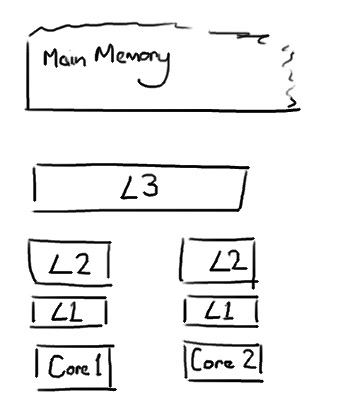
L1和L2由CPU的每个核心独享,而L3则被整个CPU里所有核心共享(仅指单CPU架构)。
CPU访问数据时,按照先去L1,查不到去L2,再L3->主存的顺序来查找。
Cache Line
在上述CPU和缓存的数据交换过程中,并不是以字节为单位的。而是每次都会以Cache Line为单位来进行存取。
Cache Line其实就是一段固定大小的内存空间,一般为64字节。
MESI
这个东西研究过 volatile的同学可能会比较熟悉,这个就是各个告诉缓存之间的一个一致性协议。
因为L1 L2是每个核心自己使用,而不同核心又可能涉及共享变量问题,所以各个高速缓存间势必会有一致性的问题。MESI就是解决这些问题的一种方式。
MESI大致原理如下图:

我这里就摘抄一下网上搜到的解释:
在MESI协议中,每个Cache line有4个状态,可用2个bit表示,它们分别是:
M(Modified):这行数据有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中;
E(Exclusive):这行数据有效,数据和内存中的数据一致,数据只存在于本Cache中;
S(Shared):这行数据有效,数据和内存中的数据一致,数据存在于很多Cache中;
I(Invalid):这行数据无效。
通俗一点说,就是如果Core0和Core1都在使用一个共享变量变量A,则0,1都会在自己的Cache里有一份A的副本,分布在不同的CacheLine。
如果大家都没有修改A,则Core0和Core1里变量A所在的Cache Line的状态都是S。
如果Core0修改了A的值,则此时Core0的Cache Line变为M,Core1 的Cache Line变为I。
这样CPU就可以通过CacheLine的状态,来决定是删除缓存,还是直接读取什么的。
伪共享
背景知识介绍完毕了,这样再说伪共享就不会显得太难以理解了。
先说一个场景:
你的代码里需要使用一个volatile的Bool变量,当做多线程行为的一个开关:
static volatile boolean flag = true; public static void main(String[] args) { for (int i = 0; i < 10; i++) { new Thread(() -> { Integer count = 0; while (flag) { ++count; System.out.println(Thread.currentThread().getName() + ":" + count); try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } } }).start(); } new Thread(() -> { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } flag = false; }).start(); }
这段代码会声明一个flag为true,然后有10个工作线程会在flag为true时没100ms对count做个自增操作,然后输出。当flag为false时,就会结束线程。
还有一个线程A,会在1000ms后将flag置为false。
这里就是volatile的一个经典用法,可以保证多个线程对flag的可见性,不会因为线程A修改了flag的值,但是工作线程读取到的不是最新值而额外执行一些工作。
这段代码看起来是没有任何问题的,实际上跑起来也没有问题。
但是结合之前的背景知识,考虑一下flag所在的cache line,肯定还会有其他的变量(cache line 64字节,bool无法完整填充一个CacheLine)。
如果flag所在的CacheLine里还有一个频繁修改的共享变量,这时会发生什么?
很简单,就是flag所在的CacheLine被频繁置为不可用,需要清除缓存重新读取。flag在工作状态并没有被修改,但是仍然会被其他频繁修改的共享变量所影响。
这样就会带来一个问题,即使flag并没有被修改,但我们的工作线程很多时间都等于是在主存中读取flag的值,这样在高并发时会带来很大的效率问题。
以上就是所谓的 “FalseSharing” 问题。
解决办法
FalseSharing对于普通业务应用,基本没什么实际影响。但是对于很多超高并发的中间件(例如发号器),可能就会带来一定的性能瓶颈。所以这类项目都是需要关注这个问题的。
出现原因已经说清楚了,那么该如何解决呢?
其实答案就在文章的开头,那6个看上去没有任何含义的volatile long变量,就是用来解决这个问题的。
The CPU cache line commonly be 64 bytes, here is a sample of cache line after padding:64 bytes = 8 bytes (object reference) + 6 * 8 bytes (padded long) + 8 bytes (a long value)
这行注释就说明了这6个变量是如何解决FalseSharing问题的:
CacheLine一般是64字节,64 = 8(对象本身的属性信息)+ 6*8(long占用8个字节) + 8 (AtomicLong本身带有一个long) 。
写了这6个看着无效的变量后,PaddedAtomicLong就会占用64个字节,正好填满一个CacheLine,这样就会被独自分配到一个CacheLine,这样就不存在FalseSharing问题了。
需要注意的是本来AtomicLong仅占用不到20字节,但是为了解决FalseSharing做了填充之后就占用64字节了,这样就会导致空间会膨胀很多。所以即使用的时候也要做好取舍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号