

MySQL事务的隔离级别
令人惊讶的是,大部分数据库系统都没有提供真正的隔离性,最初或许是因为系统实现者并没有真正理解这些问题。如今这些问题已经弄清楚了,但是数据库实现者在正确性和性能之间做了妥协。ISO和ANIS SQL 标准指定了四种事务隔离级别的标准,但是很少有数据库厂商遵循这些标准。比如Oracle数据库就不支持READ UNCOMMITED 和REPEATABLE READ的事务隔离级别。
一、概念
以下几个概念是事务隔离级别要实际解决的问题,所以需要搞清楚都是什么意思。
1、脏读
脏读指的是读到了其他事务未提交的数据,未提交意味着这些数据可能会回滚,也就是可能最终不会存到数据库中,也就是不存在的数据。读到了并一定最终存在的数据,这就是脏读。
2、不可重复读
不可重复读指的是在同一事务内,不同的时刻读到的同一批数据可能是不一样的,可能会受到其他事务的影响,比如其他事务改了这批数据并提交了。通常针对数据更新(UPDATE)操作。
3、幻读(phantom)
MySQL官方文档给出的定义:
The so-called phantom problem occurs within a transaction when the same query produces different sets of rows at different times. For example, if a SELECT is executed twice, but returns a row the second time that was not returned the first time, the row is a “phantom” row.
翻译大概为:当同一个查询在不同的时间产生不同的行集时,所谓的虚幻问题就会在事务中发生。例如,如果执行了两次 SELECT,但第二次返回第一次未返回的行,则该行为“幻影”行。
注意:
1) 幻读是针对数据插入(INSERT)操作来说的。
2) 这里注意不要将不可重复读和幻读两者混淆了,不可重复读是指,同一事务内在不同时刻读到的同一批数据可能是不一样的,这是针对数据更新操作。而对于其他事务新插入的数据可以读到,这就引发了幻读问题。
二、MySQL 中执行事务
1、执行过程
事务的执行过程如下,以 begin 或者 start transaction 开始,然后执行一系列操作,最后要执行 commit 操作,事务才算结束。当然,如果进行回滚操作(rollback),事务也会结束。

需要注意的是,begin 命令并不代表事务的开始,事务开始于 begin 命令之后的第一条语句执行的时候。例如下面示例中,select * from xxx 才是事务的开始
begin; select * from xxx; commit; -- 或者 rollback;
2、 查看事务的隔离级别

1 # 查看事务隔离级别 5.7.20 之前 2 show variables like 'transaction_isolation'; 3 SELECT @@transaction_isolation 4 5 # 5.7.20 之后 6 SELECT @@tx_isolation 7 show variables like 'tx_isolation' 8 9 +---------------+-----------------+ 10 | Variable_name | Value | 11 +---------------+-----------------+ 12 | tx_isolation | REPEATABLE-READ | 13 +---------------+-----------------+
3、设置事务的隔离级别
set session/global transaction isolation level read uncommitted | read committed | repeatable read | serializable ;
mysql 5.7.20之后还可以使用:
1 SET @@gloabl.tx_isolation = 0; 2 SET @@gloabl.tx_isolation = 'READ-UNCOMMITTED'; 3 4 SET @@gloabl.tx_isolation = 1; 5 SET @@gloabl.tx_isolation = 'READ-COMMITTED'; 6 7 SET @@gloabl.tx_isolation = 2; 8 SET @@gloabl.tx_isolation = 'REPEATABLE-READ'; 9 10 SET @@gloabl.tx_isolation = 3; 11 SET @@gloabl.tx_isolation = 'SERIALIZABLE';
其中作用于可以是 session 或者global,global是全局的,而session只针对当前回话窗口。隔离级别是 {read uncommitted | read committed | repeatable read | serializable} 这四种,不区分大小写。
设置完成后,只对之后新起的 session 才起作用,对已经启动 session 无效。如果用 shell 客户端那就要重新连接 MySQL,如果用 Navicat 那就要创建新的查询窗口。
三、事务隔离级别
- 读未提交(READ UNCOMMITTED)
- 读提交 (READ COMMITTED)
- 可重复读 (REPEATABLE READ)
- 串行化 (SERIALIZABLE)
各隔离级别的特点如下:

下面来依次介绍各个隔离级别的特点
1、读未提交(READ UNCOMMITTED)
MySQL 事务隔离其实是依靠锁来实现的,加锁自然会带来性能的损失。而读未提交隔离级别是不加锁的,所以它的性能是最好的,没有加锁、解锁带来的性能开销。
说明:它连脏读的问题都没办法解决,更不要提不可重复读和幻读。

2、读提交(READ COMMITED)
既然读未提交没办法解决脏数据的问题,那么就有了读提交。读提交就是一个事务只能读到其他事务已经提交过的数据,也就是其他事务调用commit命令之后的数据,那脏数据问题就解决了。
说明:解决了脏读,但是无法做到可重复读,也没办法解决幻读。
解决了脏读,如下图:

无法做到可重复读,如下图:

同样开启事务A和事务B两个事务,在事务A中使用 update 语句将 id=1 的记录行 name 字段改为 "小芳"。此时,在事务B中使用 select 语句进行查询,我们发现在事务A提交之前,事务B中查询到的记录 name 一直是"小明",直到事务A提交,此时在事务B中 select 查询,发现 name 的值已经是 "小芳"了。
这就出现了一个问题,在同一事务中(本例中的事务B),事务的不同时刻同样的查询条件,查询出来的记录内容是不一样的,事务A的提交影响了事务B的查询结果,这就是不可重复读,也就是读提交隔离级别。
说明:读提交事务隔离级别是大多数流行数据库的默认事务隔离级别,比如 Oracle,但其并不是 MySQL 的默认隔离级别。
3、可重复读(REPEATABLE READ)
可重复读是指,同一事务内不会读到其他事务对已有数据的修改,即使其他事务已提交,也就是说,事务开始时读到的已有数据是什么,在事务提交前的任意时刻,这些数据的值都是一样的。
1)MVCC
为了解决不可重复读,或者为了实现可重复读,MySQL 采用了 MVCC (多版本并发控制) 的方式。
2)可重复读和不可重复读的主要区别
这里面要提到一个重要的词:快照
可重复读是在事务开始的时候生成一个当前事务全局性的快照,而读提交则是每次执行语句的时候都重新生成一次快照。
对于一个快照来说,它能够读到那些版本数据,要遵循以下规则:
- 当前事务内的更新,可以读到
- 版本未提交,不能读到
- 版本已提交,但是却在快照创建后提交的,不能读到
- 版本已提交,且是在快照创建前提交的,可以读到
两者主要的区别就是在快照的创建上,可重复读仅在事务开始时创建一次,而读提交每次执行语句的时候都要重新创建一次。
3)解决幻读
MySQL 已经在可重复读隔离级别下解决了幻读的问题。下面我们来测试下。
如图一:
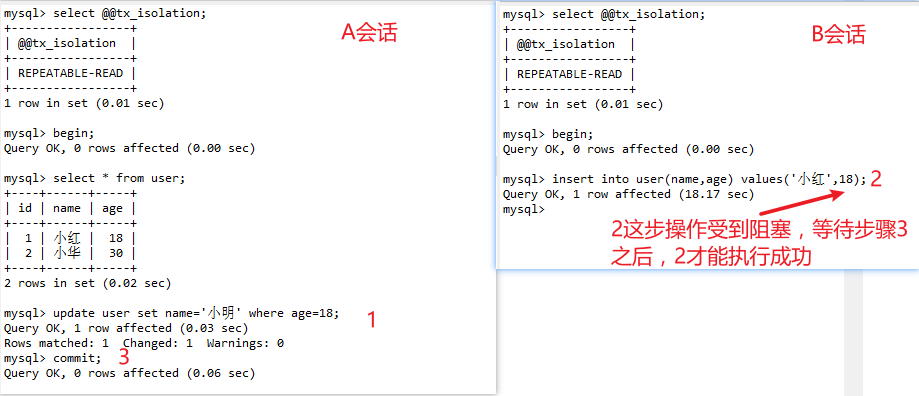
如图二:
4)但是,还是会出现一些问题
如下图:

产生上面问题的原因,我们从MySQL官方文档中找到下面一段解释
The snapshot of the database state applies to SELECT statements within a transaction, not necessarily to DML statements. If you insert or modify some rows and then commit that transaction, a DELETE or UPDATE statement issued from another concurrent REPEATABLE READ transaction could affect those just-committed rows, even though the session could not query them. If a transaction does update or delete rows committed by a different transaction, those changes do become visible to the current transaction.
翻译大概为: 数据库状态的快照适用于事务中的SELECT语句, 而不一定适用于所有DML语句。如果您插入或修改某些行, 然后提交该事务, 则从另一个并发REPEATABLE READ事务发出的DELETE或UPDATE语句就可能会影响那些刚刚提交的行, 即使该事务无法查询它们。 如果事务更新或删除由不同事务提交的行, 则这些更改对当前事务变得可见。
再进一步分析上面产生的问题:
跟MVCC并发控制中的读操作有关
MVCC并发控制中的读操作可以分成两类: 快照读 (snapshot read) 与 当前读 (current read)。
快照读
读取专门的快照 (对于RC,快照(ReadView)会在每个语句中创建。对于RR,快照是在事务启动时创建的)
简单的select操作(不需要加锁)
当前读
读取最新版本的记录, 没有快照。 在InnoDB中,当前读取根本不会创建任何快照。
select ... lock in share mode
select ... for update
针对如下操作, 会让如下操作阻塞:insert、update、delete
说明:在Repeatable Read级别下, 快照读是通过MVCC(多版本控制)和undo log来实现的, 当前读是通过手动加record lock(记录锁)和gap lock(间隙锁)来实现的。所以从上面的显示来看,如果需要实时显示数据,还是需要通过加锁来实现。这个时候会使用Next-key锁来实现。
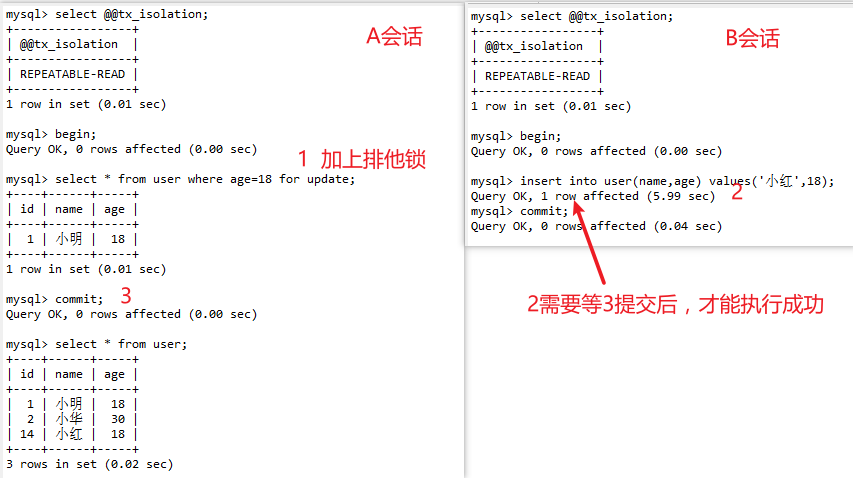
5) Next-Key锁
MySQL 把行锁和间隙锁合并在一起,解决了并发写和幻读的问题,这个锁叫做 Next-Key锁。
举个栗子:
假设现在表中有两条记录,并且 age 字段已经添加了索引,两条记录 age 的值分别为 10 和 30。
此时,在数据库中会为索引维护一套B+树,用来快速定位行记录。B+索引树是有序的,所以会把这张表的索引分割成几个区间。

实现流程:
在事务A提交之前,事务B的插入操作只能等待,这就是间隙锁起得作用。当事务A执行update user set name='小明' where age = 10; 的时候,由于条件 where age = 10 ,数据库不仅在 age =10的行上添加了行锁,而且在这条记录的两边,也就是(负无穷,10]、(10,30]这两个区间加了间隙锁,从而导致事务B插入操作无法完成,只能等待事务A提交。不仅插入 age = 10 的记录需要等待事务A提交,age<10、10<age<30 的记录页无法完成,而大于等于30的记录则不受影响,这足以解决幻读问题了。
这是有索引的情况,如果 age 不是索引列,那么数据库会为整个表加上间隙锁。所以,如果是没有索引的话,不管 age 是否大于等于30,都要等待事务A提交才可以成功插入。
说明:
1)InnoDB 存储引擎默认支持的隔离级别是REPEATABLE READ,但是与标准SQL不同的是,InnoDB 存储引擎在REPEATABLE READ事务隔离级别下,使用Next-Key Lock锁的算法,因此避免幻读的产生。
2)REPEATABLE READ级别作为 mysql 事务默认隔离级别,是事务安全与性能的折中,可能也符合二八定律(20%的事务存在幻读的可能,80%的事务没有幻读的风险),我们在正确认识幻读后,便可以根据场景灵活的防止幻读的发生。
3)MySQL的行锁是通过索引加载的,也就是说,行锁是加在索引响应的行上的,要是对应的SQL语句没有走索引,则会全表扫描,行锁则无法实现,取而代之的是表锁,此时其它事务无法对当前表进行更新或插入操作。
4、串行化 (SERIALIZABLE)
串行化是4种事务隔离级别中隔离效果最好的,解决了脏读、可重复读、幻读的问题,但是效果最差,它将事务的执行变为顺序执行,与其他三个隔离级别相比,它就相当于单线程,后一个事务的执行必须等待前一个事务结束。

补充一下:
InnoDB 行锁等待默认超时时间为50秒
查看超时设置时间命令:show variables like 'innodb_lock_wait_timeout';

超时后报错:Lock wait timeout exceeded; try restarting transaction
说明:SERIALIZABLE 级别则是悲观的认为幻读时刻都会发生,故会自动的隐式的对事务所需资源加排它锁,其他事务访问此资源会被阻塞等待,故事务是安全的,但需要认真考虑性能。
四、总结
1、读未提交和串行化基本上是不需要考虑的隔离级别,前者不加锁限制,后者相当于单线程执行,效率太差。
2、读提交解决了脏读问题,行锁解决了并发更新的问题。并且 MySQL 在可重复读级别解决了幻读问题,是通过行锁和间隙锁的组合 Next-Key 锁实现的。
3、隔离级别越低,事务请求的锁越少或保持锁的时间就越短。这也是为什么大多数数据库系统默认的事务隔离级别是READ COMMITED。
4、InnoDB 的行锁锁定的是索引,而不是记录本身,这一点也需要有清晰的认识,故某索引相同的记录都会被加锁,会造成索引竞争,这就需要我们严格设计业务 sql,尽可能的使用主键或唯一索引对记录加锁。索引映射的记录如果存在,加行锁,如果不存在,则会加 next-key lock / gap 锁 / 间隙锁,故 InnoDB 可以实现事务对某记录的预先占用,如果记录存在,它就是本事务的,如果记录不存在,那它也将是本是无的,只要本是无还在,其他事务就别想占有它。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号