

5散列表
1 散列函数
散列函数将输入映射到输出。
- 1.散列函数总是将同样的输入映射到相同的索引。同一个输入,其结果是一致的。如输入apple,每次都得到4。
- 2.散列函数将不通话的的输入映射到不同的索引。
- 3.散列函数直到数组有多大,只返回有效的索引。
散列表也被称为散列映射、映射、字典和关联数组。
2.应用案例
2.1 将散列表用于查找
创建电话簿
phone_book = {}
#或者phone_book = dict()
phone_book["马云"]=18888888888
phone_book["马化腾"]=16868686868
#获取马云的练习方式
print(phone_book["马云"])
散列表还适用于DNS解析
无论访问哪个网站,其网址都必须转换为IP地址。如
baidu.com -> 183.232.231.174
sina.com -> 36.156.86.241
163.com -> 111.3.84.41
2.2 防止重复
假如负责管理投票站。每人只能投一票。有人来投票,需要先查询他的姓名,并在投票名单中进行查找,确保未投过票。
如果使用简单查找,当列表非常长时,耗时将很久。
使用散列表,则非常快。
voted={}
def check_voter(name):
if voted.get(name):
print("已经投过票了")
else:
voted[name]=True
print("让他投")
check_voter("tom") #让他投
check_voter("mike") #让他投
check_voter("mike") #已经投过票了
2.3 将散列表用作缓存
假设有人问你月球和地球之间的距离,你需要搜索,在告诉对方答案。缓存将答案存在本地,以后再问,直接回答。
缓存:
- 用户能够更快的看到网页,就像你记住了月球和地球之间的距离一样,再有人问起,可以立即回答
- 网站做的工作更少
cache={}
def get_page(url):
if cache.get(url):
return cache[url] #返回缓存的数据
else:
data = get_data_from_server(url)
cache[url]=data #保存到缓存中
return data
2.4 小结
散列表适合用于:
- 模拟映射关系
- 防止重复
- 缓存/记住数据,以免服务器再通过处理来生成它们。
3.冲突
散列表长度一定比如key为a-z 26个字母,元素大于散列表的长度。a已经存了apple-1.49,如果再存储avocado-3.99,会因为给两个元素分配相同的位置的而冲突。为了避免冲突:如果两个key映射到同一位置,就在这个位置存储一个链表。
如果你的商品全是以a开头的,所有元素都存到一个链表中,散列表的速度会很慢。
经验:
- 散列函数很重要。散列函数要将key均匀的映射到散列表的不同位置。
- 如果散列表存储的链表很长,散列表的速度将急剧下降。如果使用的散列函数很好,链表就不会很长。
4. 性能
平均情况下,散列表执行各种操作的时间为常量时间(O(1))。
常量时间:不过散列表多大,所需的时间都相同。
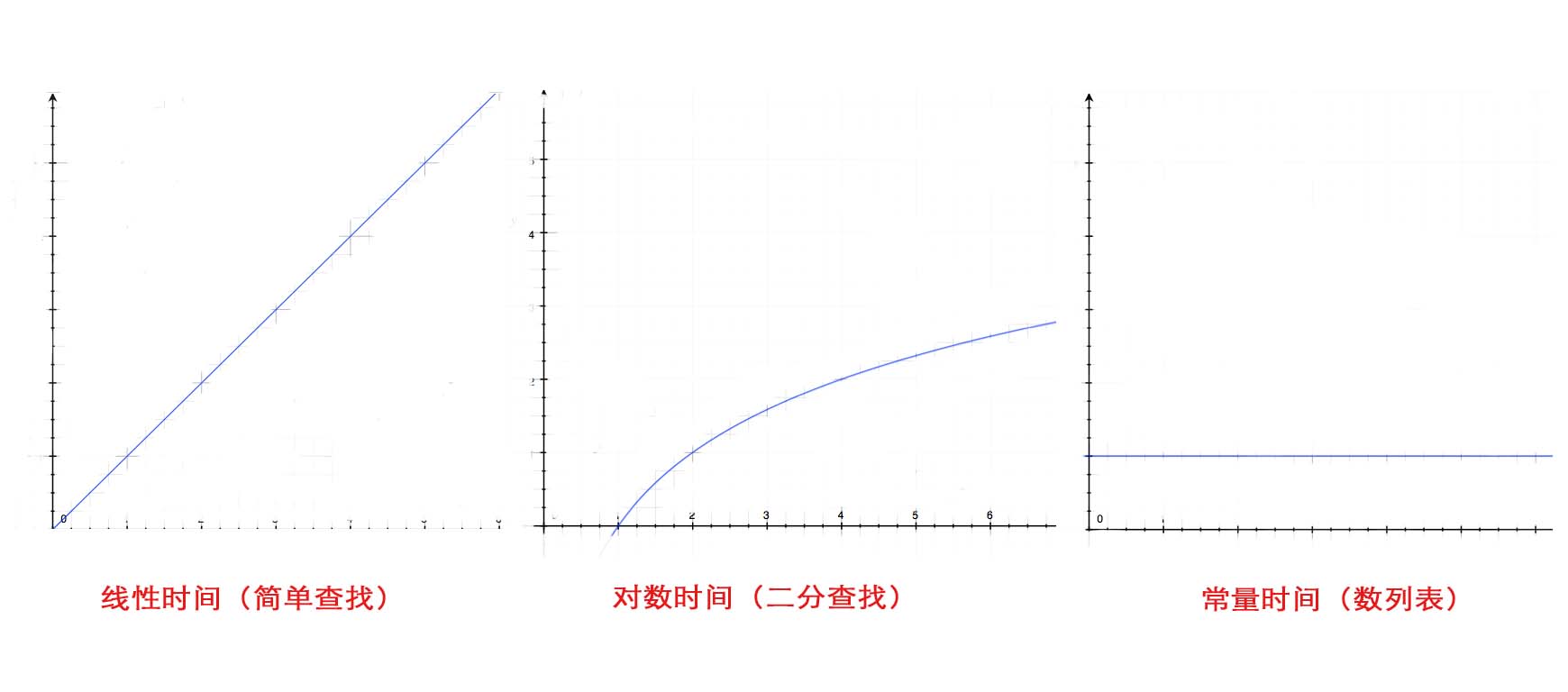
散列表的性能:
| 操作 | 平均情况 | 最糟情况 |
| 查找 | O(1) | O(n) |
| 插入 | O(1) | O(n) |
| 删除 | O(1) | O(n) |
4.1 填装因子
填装因子=散列表包含的元素数/位置总数
如列表长度为5,里面有2个元素,其填装因子为0.4.
填装因子度量的是散列表中还有多少位置是空的。
填装因子大于1意味着商品数量超过了数组的位置数。一旦填装因子开始增大,你就需要在散列表中添加位置,这被称为调整长度。调整长度通常将数组增长一倍。
填装因子越低,发生冲突的可能性越小,散列表的性能越高。经验:一旦填装因子大于0.7,就调整散列表的长度。
4.2 良好的散列函数
良好的散列函数让数组中的值呈均匀分布,避免让值扎堆,导致大量的冲突。
5 小结
- 冲突很糟糕,良好的散列函数可以减少冲突
- 散列表的查找、插入和删除速度都非常快
- 散列表适合与模拟映射关系
- 一旦填装因子超过0.7,就该调整散列表的长度。
- 散列表可用于缓存数据
- 散列表非常适合用于方式重复

 浙公网安备 33010602011771号
浙公网安备 33010602011771号