
requests-1快速学习
请直接转身官网http://docs.python-requests.org/zh_CN/latest/user/quickstart.html#url](http://docs.python-requests.org/zh_CN/latest/user/quickstart.html#url)
1.安装requests
pip install requests
2.发送请求
r = requests.get("https://api.github.com/events")
print('get:',r.url,r.status_code)
#data代表传入表单形式的数据
r = requests.post("http://httpbin.org/post",data = {'key':'vaule'})
print('post:',r.url,r.status_code)
r = requests.put("http://httpbin.org/put",data = {'key':'value'})
print('put:',r.url,r.status_code)
r = requests.delete('http://httpbin.org/delete')
print('delete:',r.url,r.status_code)
r = requests.head('http://httpbin.org/get')
print('head:',r.url,r.status_code)
r = requests.options('http://httpbin.org/get')
print('options',r.url,r.status_code)

3.传递URL参数
手工构建URL,将查询字符串组合到URL中。
对于带参数的URL,参数params是以dict的形式传入
import requests
r = requests.get("http://httpbin.org/get",params={'key1':'values1','key2':'value2'})
print("直接传递:", r.url, r.status_code)
search_word = {"wd":'廖雪峰'}
r = requests.get("https://www.baidu.com/s?",params=search_word)
print("间接传入:", r.url, r.status_code)
payload = {'key1':'value1', 'key2':['value2','value3']}
r = requests.get('http://www.httpbin.org/get', params=payload)
print("间接传入一个列表:", r.url, r.status_code)

4.响应内容
requests会自动解码来自服务器的内容。大多数unicode字符集都能被无缝的解码。
请求发出后,request会基于http头部对响应的编码作出推测。
import requests
r = requests.get('https://api.github.com/events')
print(r.text)
print('使用的编码类型:', r.encoding)
#指定编码类型
r.encoding = 'ISO-8859-1'

5.二进制响应内容
返回的非文本内容,可以保存为文件
import requests
r = requests.get('http://img1.bitautoimg.com/bitauto/2018/12/17/5ac08f3f-34cb-4eca-91d8-3cf688ca2ce5_630_w0@2x.jpg')
with open('bitauto.jpg','wb') as f:
f.write(r.content)
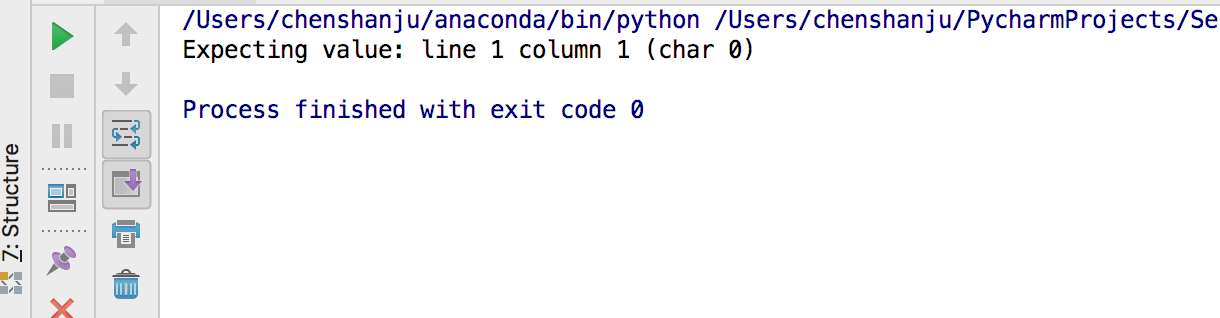
6.处理json数据
import requests
#json响应内容
r = requests.get('https://api.github.com/events')
print(r.json()[2])
 如果json转码失败,会抛出异常
```#python
import requests
#json响应内容
r = requests.get('http://img1.bitautoimg.com/bitauto/2018/12/17/5ac08f3f-34cb-4eca-91d8-3cf688ca2ce5_630_w0@2x.jpg')
try:
print(r.json())
except ValueError as e:
print(e)
```
如果json转码失败,会抛出异常
```#python
import requests
#json响应内容
r = requests.get('http://img1.bitautoimg.com/bitauto/2018/12/17/5ac08f3f-34cb-4eca-91d8-3cf688ca2ce5_630_w0@2x.jpg')
try:
print(r.json())
except ValueError as e:
print(e)
```
 需要注意的是,成功调用 r.json() 并**不**意味着响应的成功。有的服务器会在失败的响应中包含一个 JSON 对象(比如 HTTP 500 的错误细节)。这种 JSON 会被解码返回。要检查请求是否成功,请使用 r.raise_for_status() 或者检查 r.status_code 是否和你的期望相同。
需要注意的是,成功调用 r.json() 并**不**意味着响应的成功。有的服务器会在失败的响应中包含一个 JSON 对象(比如 HTTP 500 的错误细节)。这种 JSON 会被解码返回。要检查请求是否成功,请使用 r.raise_for_status() 或者检查 r.status_code 是否和你的期望相同。
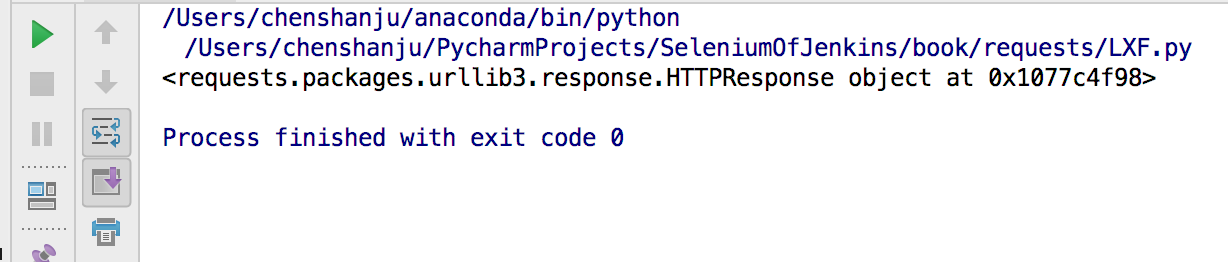
7.原始响应内容
import requests
#在罕见的情况下,你可能想获取来自服务器的原始套接字响应,那么你可以访问 r.raw。 如果你确实想这么干,那请你确保在初始请求中设置了 stream=True。具体你可以这么做
r = requests.get('https://api.github.com/events', stream=True)
print(r.raw)
#将文本流保存到文件
with open('text.html', 'wb') as f:
for i in r.iter_content(10):
f.write(i)
8.定制请求头
http://www.cnblogs.com/Joans/p/3956490.html
import requests
url = 'https://api.github.com/some/endpoint'
this_headers = {'user-agent': 'my-app/0.0.1'}
r = requests.get(url, headers=this_headers)
- 如果在 .netrc 中设置了用户认证信息,使用 headers= 设置的授权就不会生效。而如果设置了 auth= 参数,
.netrc的设置就无效了。 - 如果被重定向到别的主机,授权 header 就会被删除。
- 代理授权 header 会被 URL 中提供的代理身份覆盖掉。
- 在我们能判断内容长度的情况下,header 的 Content-Length 会被改写。
更进一步讲,Requests 不会基于定制 header 的具体情况改变自己的行为。只不过在最后的请求中,所有的 header 信息都会被传递进去。
注意: 所有的 header 值必须是 string、bytestring 或者 unicode。尽管传递 unicode header 也是允许的,但不建议这样做。
9.更加复杂的post请求
data参数:可以发送一些编码为表单形式的数据
import requests
#传入一个字典
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.post("http://httpbin.org/post", data=payload)
print(r.json()["form"])
#data传入一个元组列表,在表单中多个元素使用同一个key的时候适用
payload = (('key1', 'value1'), ('key1', 'value2'))
r = requests.post('http://httpbin.org/post', data=payload)
print(r.json()["form"])

非表单形式
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import requests,json
url = 'https://api.github.com/some/endpoint'
payload = {'some': 'data'}
#自行对dict进行编码
r = requests.post(url, data=json.dumps(payload))
print(r.text)
#使用json参数直接传递,会被自动编码
r = requests.post(url,data=payload)
print(r.text)

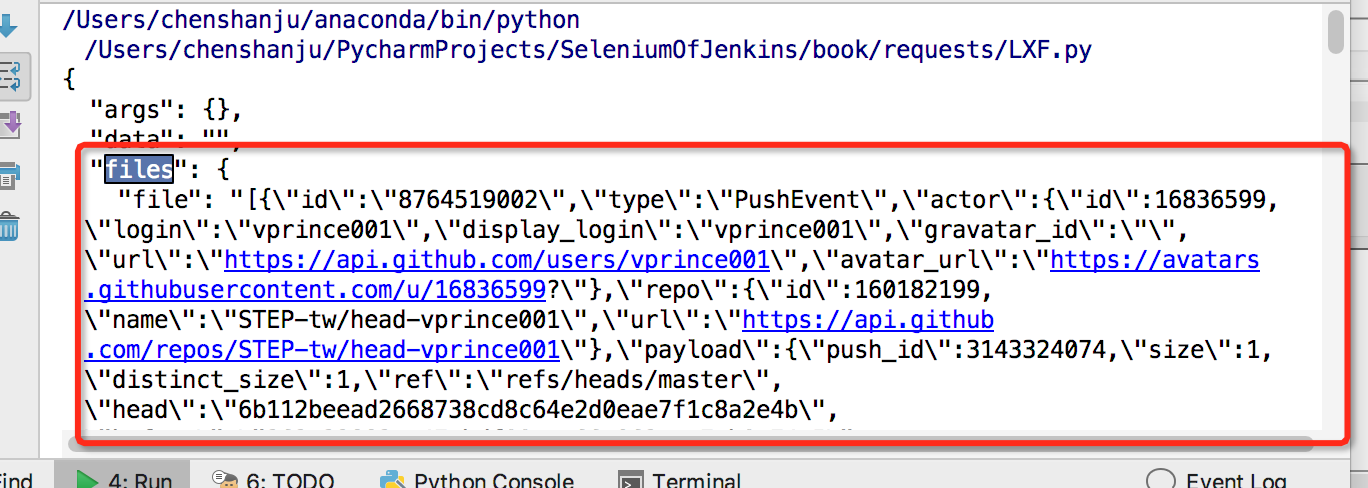
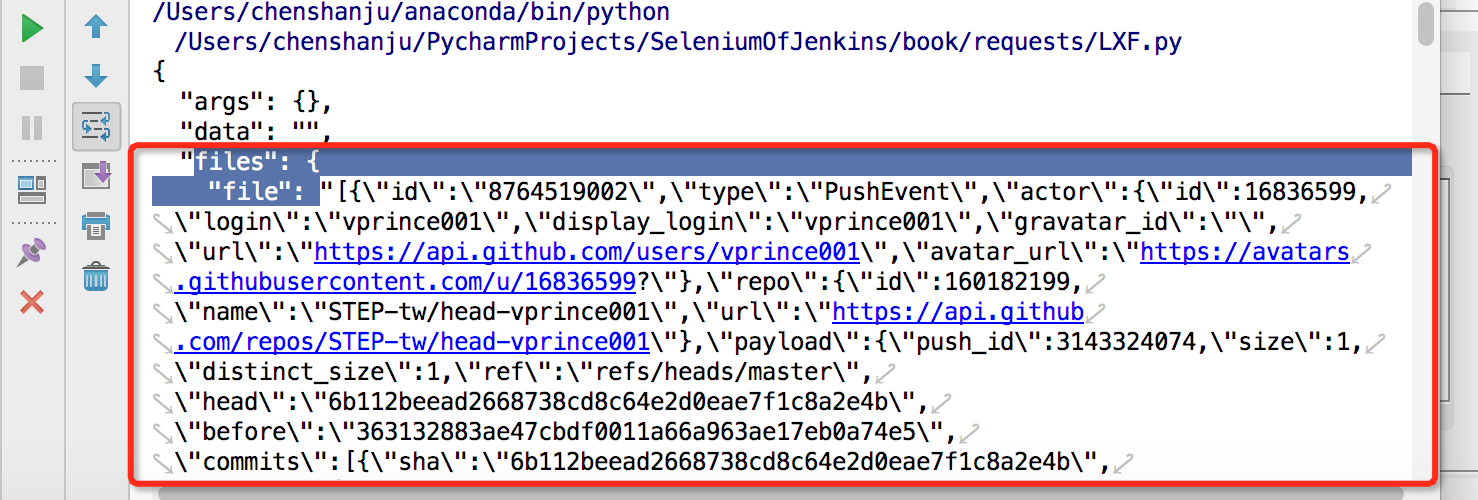
10.上传多部分编码文件
import requests
url = 'http://httpbin.org/post'
files = {'file': open('text.html','rb')}
r = requests.post(url,files=files)
print(r.text)
 显式的设置文件名、文件类型和请求头
```#python
import requests
url = 'http://httpbin.org/post'
files = {'file':('text.html', open('text.html','rb'),'application/html',{'Expires':'0'})}
r = requests.post(url,files=files)
print(r.text)
```
显式的设置文件名、文件类型和请求头
```#python
import requests
url = 'http://httpbin.org/post'
files = {'file':('text.html', open('text.html','rb'),'application/html',{'Expires':'0'})}
r = requests.post(url,files=files)
print(r.text)
```
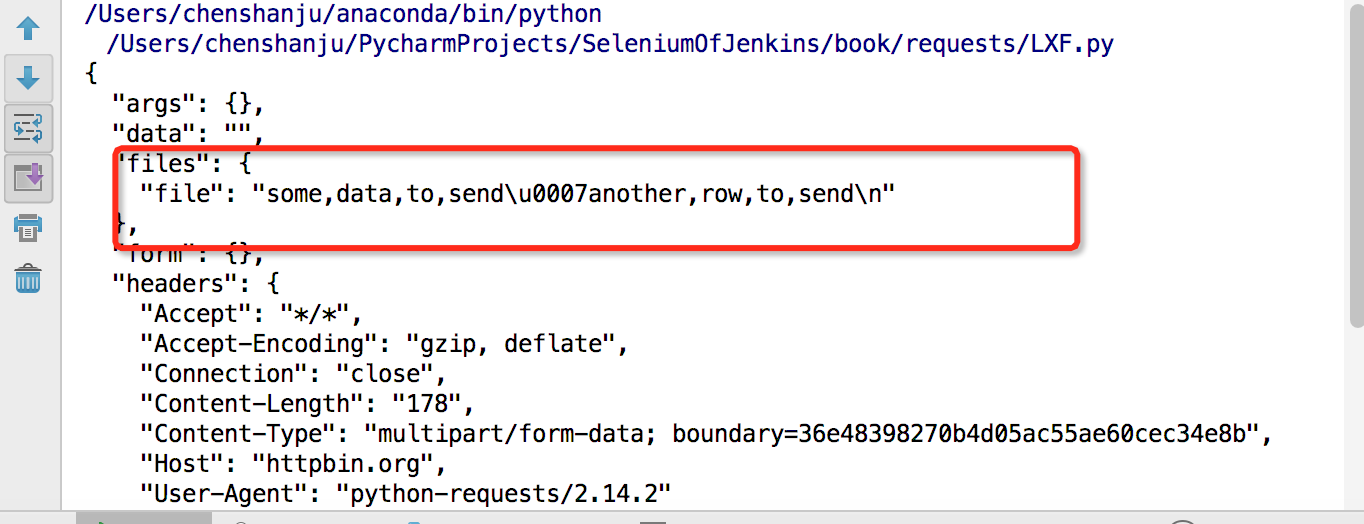
 传递一个字符串
```#python
import requests
url = 'http://httpbin.org/post'
files = {'file':'some,data,to,send\aanother,row,to,send\n'}
r = requests.post(url,files=files)
print(r.text)
```
传递一个字符串
```#python
import requests
url = 'http://httpbin.org/post'
files = {'file':'some,data,to,send\aanother,row,to,send\n'}
r = requests.post(url,files=files)
print(r.text)
```
警告
我们强烈建议你用二进制模式(binary mode)打开文件。这是因为 Requests 可能会试图为你提供 Content-Length header,在它这样做的时候,这个值会被设为文件的字节数(bytes)。如果用文本模式(text mode)打开文件,就可能会发生错误。
11.响应状态码
- 返回状态码 r.status_code
- 发送了错误请求4XX或者服务器响应错误5XX,使用r.raise_for_status抛出异常,没有异常,返回none
- 内置状态码查询对象r.status_code == requests.codes.ok
响应码为200的接口
import requests
r = requests.get('http://httpbin.org/get')
print('r.status_code:', r.status_code)
print('r.status_code == requests.codes.ok:',r.status_code == requests.codes.ok)
print(r.raise_for_status())
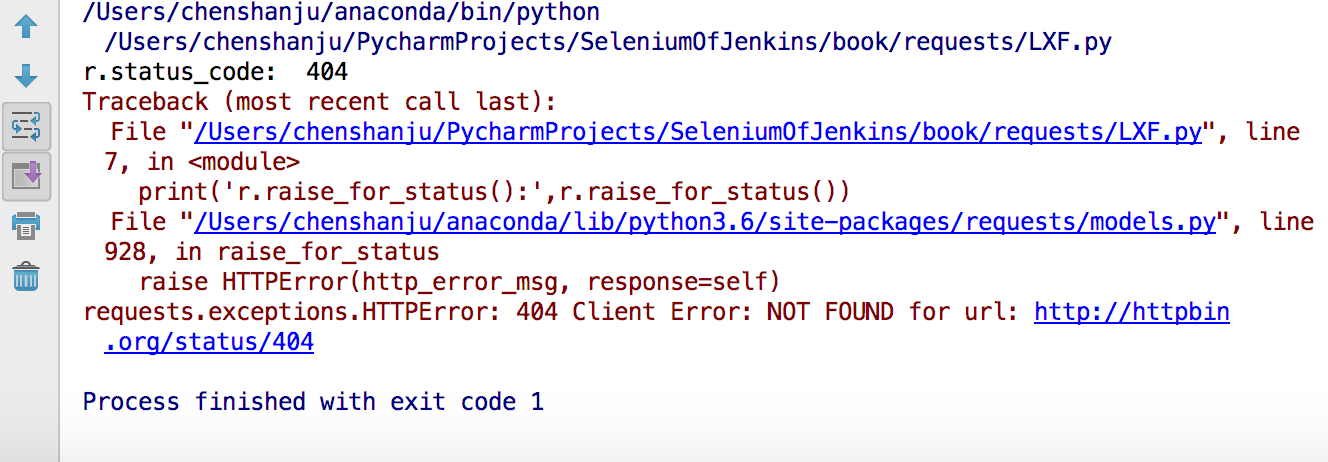
 响应码为404的接口
```#python
import requests
r = requests.get('http://httpbin.org/status/404')
print("r.status_code: ",r.status_code)
print('r.raise_for_status():',r.raise_for_status())
```
响应码为404的接口
```#python
import requests
r = requests.get('http://httpbin.org/status/404')
print("r.status_code: ",r.status_code)
print('r.raise_for_status():',r.raise_for_status())
```
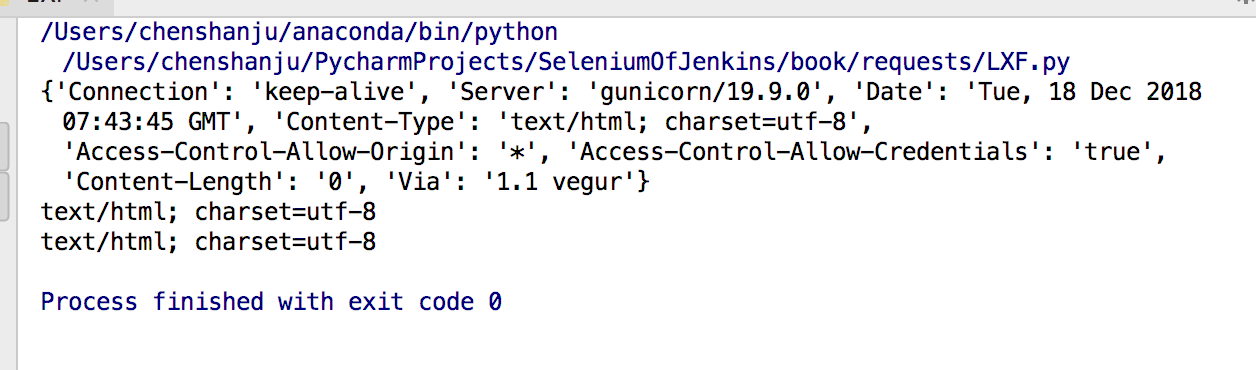
12.响应头
http响应头对大小写不敏感
import requests
r = requests.get('http://httpbin.org/status/404')
print(r.headers)
print(r.headers['content-type'])
print(r.headers.get('Content-Type'))
13.Cookie
如果某个响应中包含一些cookie,可以快速访问它们
import requests
url = 'http://example.com/some/cookie/setting/url'
r = requests.get(url)
print(r.cookies)
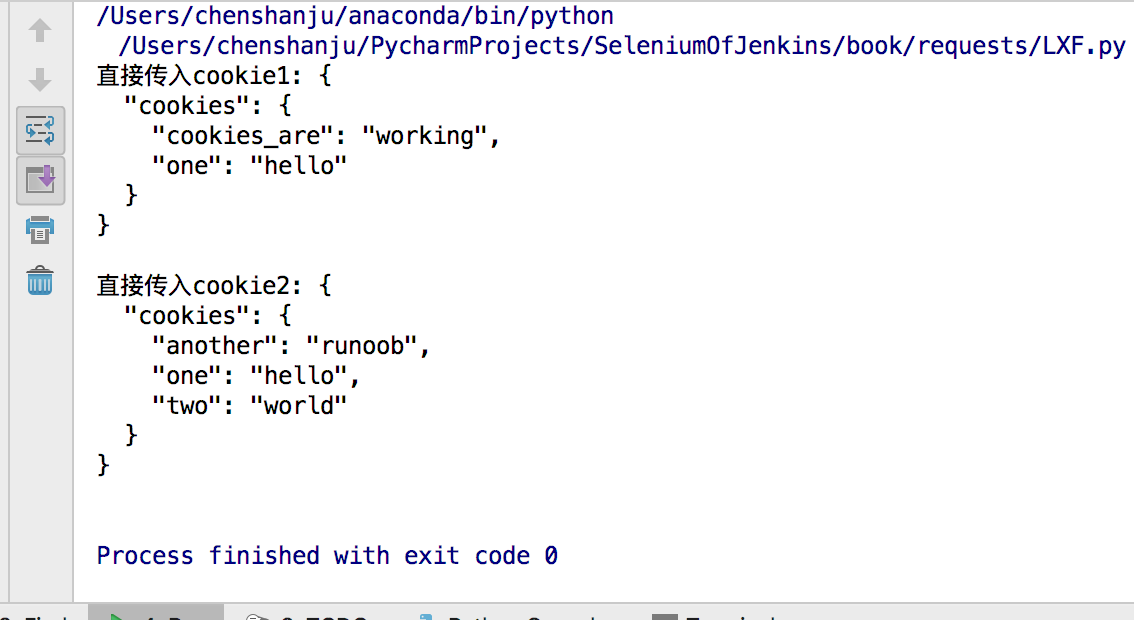
 发送cookies到服务器
```#python
import requests
url = 'http://httpbin.org/cookies'
#传入cookies_param
cookies_param = dict(cookies_are='working')
cookies_param['one']='hello'
r = requests.get(url, cookies=cookies_param)
print('直接传入cookie1:',r.text)
#传入cookie_param
cookies_param = {'one':'hello','two': 'world','another':'runoob'}
r = requests.get(url,cookies=cookies_param)
print('直接传入cookie2:',r.text)
```
发送cookies到服务器
```#python
import requests
url = 'http://httpbin.org/cookies'
#传入cookies_param
cookies_param = dict(cookies_are='working')
cookies_param['one']='hello'
r = requests.get(url, cookies=cookies_param)
print('直接传入cookie1:',r.text)
#传入cookie_param
cookies_param = {'one':'hello','two': 'world','another':'runoob'}
r = requests.get(url,cookies=cookies_param)
print('直接传入cookie2:',r.text)
```
 Cookie 的返回对象为 RequestsCookieJar,它的行为和字典类似,但接口更为完整,适合跨域名跨路径使用。你还可以把 Cookie Jar 传到 Requests 中:
```#python
import requests
jar = requests.cookies.RequestsCookieJar()
jar.set('tasty_cookie', 'yum', domain='httpbin.org', path='/cookies')
url = 'http://httpbin.org/cookies'
r = requests.get(url, cookies=jar)
print(r.text)
```
Cookie 的返回对象为 RequestsCookieJar,它的行为和字典类似,但接口更为完整,适合跨域名跨路径使用。你还可以把 Cookie Jar 传到 Requests 中:
```#python
import requests
jar = requests.cookies.RequestsCookieJar()
jar.set('tasty_cookie', 'yum', domain='httpbin.org', path='/cookies')
url = 'http://httpbin.org/cookies'
r = requests.get(url, cookies=jar)
print(r.text)
```

14.重定向与请求历史
默认情况下,除了 HEAD, Requests 会自动处理所有重定向。
GET、OPTIONS、POST、PUT、PATCH 或者 DELETE,自动允许重定向处理;HEAD,自动禁止重定向:
使用allow_redirects参数可以启动或禁止重定向。
Response.history 是一个 Response 对象的列表,为了完成请求而创建了这些对象。这个对象列表按照从最老到最近的请求进行排序。
import requests
#GitHub将所有的http请求重定向到https
r = requests.get("http://github.com")
print(r.url)
print(r.status_code)
print(r.history)
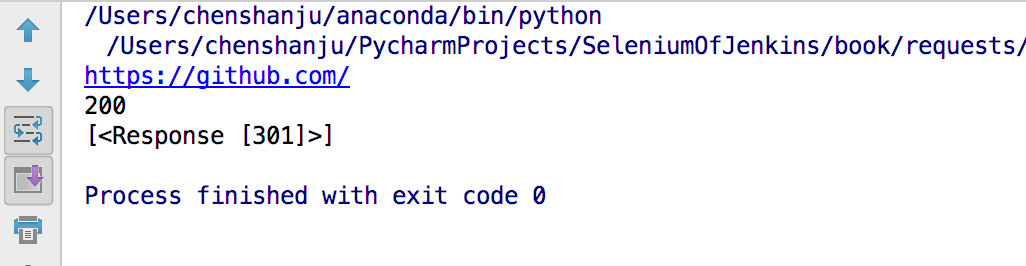
import requests
#GitHub将所有的http请求重定向到https
r = requests.get("http://github.com", allow_redirects=False)
print(r.url)
print(r.status_code)
print(r.history)
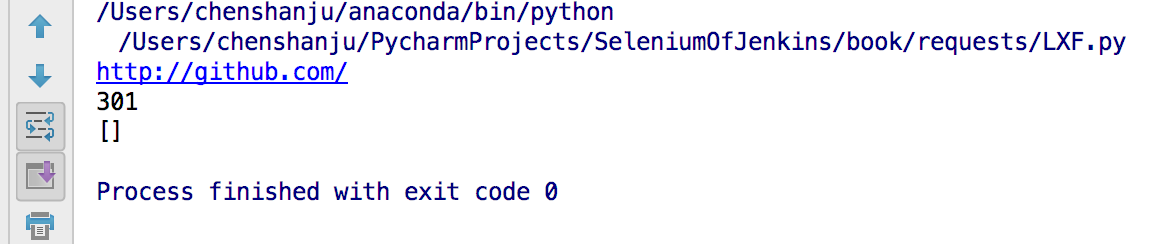 ```#python
import requests
#GitHub将所有的http请求重定向到https
r = requests.head("http://github.com", allow_redirects=True)
print(r.url)
print(r.status_code)
print(r.history)
```
```#python
import requests
#GitHub将所有的http请求重定向到https
r = requests.head("http://github.com", allow_redirects=True)
print(r.url)
print(r.status_code)
print(r.history)
```
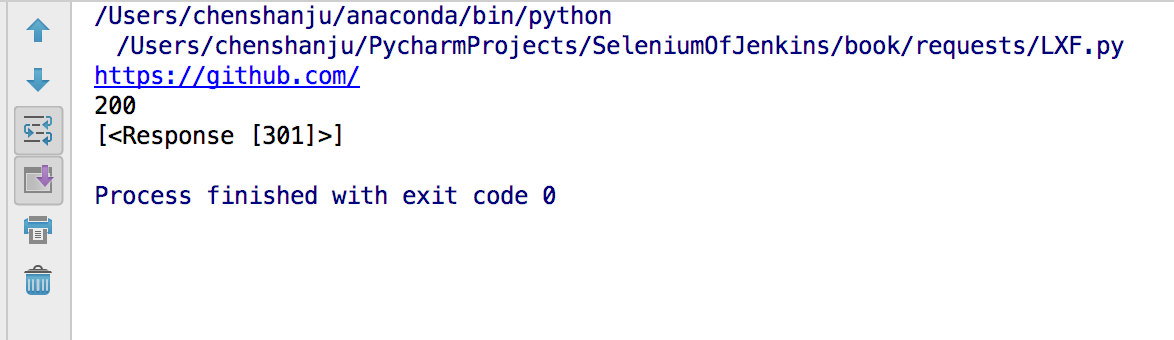
15.超时
requests 在经过以 timeout 参数设定的秒数时间之后停止等待响应。基本上所有的生产代码都应该使用这一参数。如果不使用,你的程序可能会永远失去响应:
timeout 仅对连接过程有效,与响应体的下载无关。 timeout 并不是整个下载响应的时间限制,而是如果服务器在 timeout 秒内没有应答,将会引发一个异常(更精确地说,是在 timeout 秒内没有从基础套接字上接收到任何字节的数据时
import requests
r = requests.get("http://github.com", timeout=0.001)
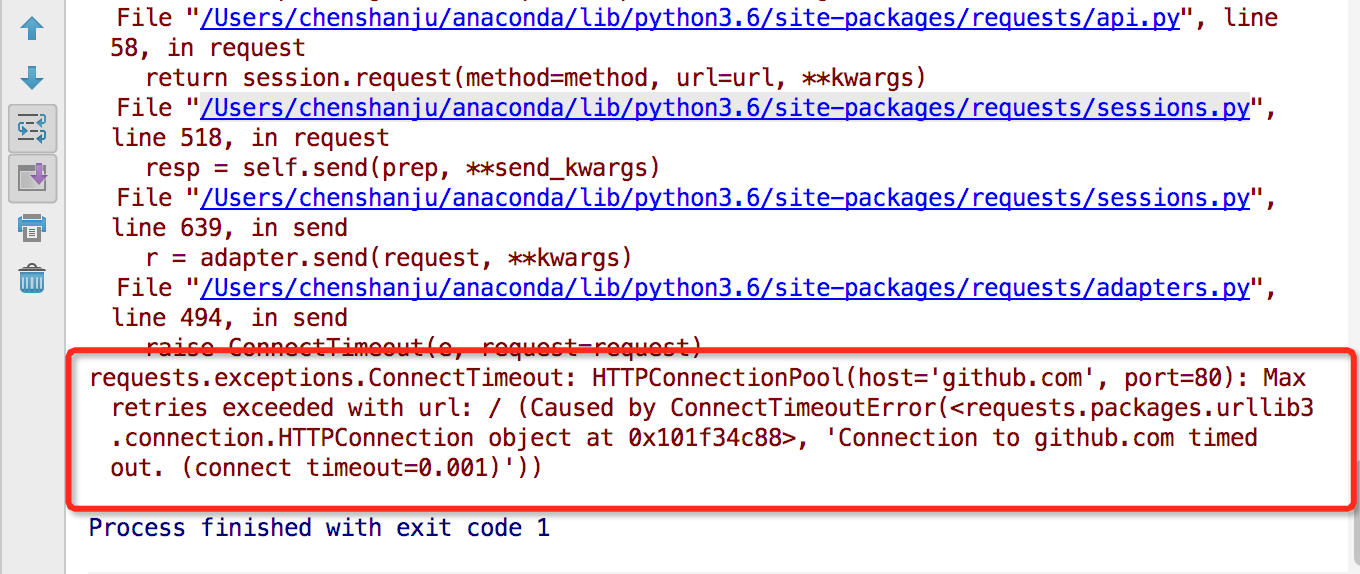
16.错误与异常
-
遇到网络问题(如:DNS 查询失败、拒绝连接等)时,Requests 会抛出一个 ConnectionError 异常。
-
如果 HTTP 请求返回了不成功的状态码, Response.raise_for_status() 会抛出一个 HTTPError 异常。
-
若请求超时,则抛出一个 Timeout 异常。
-
若请求超过了设定的最大重定向次数,则会抛出一个 TooManyRedirects 异常。
-
所有Requests显式抛出的异常都继承自 requests.exceptions.RequestException 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号