
Redis 学习(二)
十一、Redis持久化配置
Redis的持久化有2种方式 1快照 2是日志
Rdb快照的配置选项
save 900 1 // 900秒内,有1条写入,则产生快照
save 300 1000 // 如果300秒内有1000次写入,则产生快照
save 60 10000 // 如果60秒内有10000次写入,则产生快照
(这3个选项都屏蔽,则rdb禁用)
stop-writes-on-bgsave-error yes // 后台备份进程出错时,主进程停不停止写入
rdbcompression yes // 导出的rdb文件是否压缩
Rdbchecksum yes // 导入rbd恢复时数据时,要不要检验rdb的完整性
dbfilename dump.rdb //导出来的rdb文件名
dir ./ //rdb的放置路径
Aof 的配置
appendonly no # 是否打开 aof日志功能
appendfsync always # 每1个命令,都立即同步到aof. 安全,速度慢
appendfsync everysec # 折衷方案,每秒写1次
appendfsync no # 写入工作交给操作系统,由操作系统判断缓冲区大小,统一写入到aof. 同步频率低,速度快,
no-appendfsync-on-rewrite yes: # 正在导出rdb快照的过程中,要不要停止同步aof
auto-aof-rewrite-percentage 100 #aof文件大小比起上次重写时的大小,增长率100%时,重写
auto-aof-rewrite-min-size 64mb #aof文件,至少超过64M时,重写
注: 在dump rdb过程中,aof如果停止同步,会不会丢失?
答: 不会,所有的操作缓存在内存的队列里, dump完成后,统一操作.
注: aof重写是指什么?
答: aof重写是指把内存中的数据,逆化成命令,写入到.aof日志里.以解决 aof日志过大的问题.
问: 如果rdb文件,和aof文件都存在,优先用谁来恢复数据?
答: aof
问: 2种是否可以同时用?
答: 可以,而且推荐这么做
问: 恢复时rdb和aof哪个恢复的快
答: rdb快,因为其是数据的内存映射,直接载入到内存,而aof是命令,需要逐条执行 redis 服务器端命令

redis 127.0.0.1:6380> time ,显示服务器时间 , 时间戳(秒), 微秒数
1) "1375270361" #秒数
2) "504511" #微妙数
redis 127.0.0.1:6380> dbsize // 当前数据库的key的数量
(integer) 2
redis 127.0.0.1:6380> select 2
OK
redis 127.0.0.1:6380[2]> dbsize
(integer) 0
redis 127.0.0.1:6380[2]>
BGREWRITEAOF #后台进程重写AOF
BGSAVE #后台保存rdb快照
SAVE #保存rdb快照
LASTSAVE #上次保存时间
Slaveof master-Host port , #把当前实例设为master的slave
Flushall #清空所有库所有键
Flushdb #清空当前库所有键
Showdown [save/nosave]
注: 如果不小心运行了flushall, 立即 shutdown nosave ,关闭服务器
然后 手工编辑aof文件, 去掉文件中的 “flushall ”相关行, 然后开启服务器,就可以导入回原来数据.
如果,flushall之后,系统恰好bgrewriteaof了,那么aof就清空了,数据丢失.
- 停止所有客户端
- 如果有至少一个保存点在等待,执行 SAVE 命令
- 如果 AOF 选项被打开,更新 AOF 文件
- 关闭 redis 服务器(server)
- nosave 不允许操作aof文件
Slowlog 显示慢查询
注:多慢才叫慢?
答: 由slowlog-log-slower-than 10000 ,来指定,(单位是微秒)
服务器储存多少条慢查询的记录?
答: 由 slowlog-max-len 128 ,来做限制
Info [Replication/CPU/Memory..] #查看redis服务器的信息
Config get 配置项
Config set 配置项 值 (特殊的选项,不允许用此命令设置,如slave-of, 需要用单独的slaveof命令来设置)
Redis运维时需要注意的参数
1: 内存
# Memory
used_memory:859192 #数据结构的空间
used_memory_rss:7634944 #实占空间 申请的空间
mem_fragmentation_ratio:8.89 #前2者的比例,1.N为佳,如果此值过大,说明redis的内存的碎片化严重,可以导出再导入一次.
2: 主从复制
# Replication
role:slave
master_host:192.168.1.128
master_port:6379
master_link_status:up

3:持久化
# Persistence
rdb_changes_since_last_save:0 #离上次rdb save 后共有多少更改
rdb_last_save_time:1375224063
4: fork耗时
#Stats
latest_fork_usec:936 #上次导出rdb快照,持久化花费 微秒
注意: 如果某实例有10G内容,导出需要2分钟,
每分钟写入10000次,导致不断的rdb导出,磁盘始处于高IO状态.
5: 慢日志
config get/set slowlog-log-slower-than # 获取/设置 慢日志 命令执行时间, 一个命令执行多久才算慢
CONFIG get/SET slowlog-max-len # 存的条数
slowlog get N #获取慢日志

十二、集群的作用:
- 主从复制,防止主机宕机
- 读写分离,分担master任务
- 任务分离,如从服务器分别分担备份和计算工作

通信原理

配置

- 主服务器6379 开启aof 关闭rdb
- 复制redis.conf配置文件,命名6380 6381
- 修改6380配置文件,port 6380; daemonize yes ; pidfile /var/run/reids6380.pid;
- 6380开启rdb,关闭aof appendonly no;
- slaveof masterip masterport #设置主从
- slave-read-only yes #只读 不允许写 主从数据一致
- 6381关闭rdb,关闭aof
- 主服务器可设置密码 requirepass 密码; 客户端连接时需要密码

- 从服务器需配置 masterauth master-password

注意:可直接复制主服务器的rdb给从服务器,前提是停止rdb的占用,防止占用相同的句柄



开启6379后 再开启6380从服务器

再开启6381从服务器
由文件时间可看出:6379会重新导出一份rdb给从服务器,同时就算从服务器关闭rdb也会生成对应的rdb文件


运行时更改master-slave
修改一台slave(设为A)为new master
- 命令该服务不做其他redis服务的slave
命令: slaveof no one

- 修改其slave-read-only为 no 若有密码设置 得加上密码
- config get slave-read-only
- config set slave-read-only no
- config get requirepass
- config set requirepass xxxx

3.其他的slave再指向new master A
命令: slaveof masterip port



- 命令该服务为new master A的slave
命令格式 slaveof IP port
监控工具 sentinel sentinel.conf


Sentinel不断与master通信,获取master的slave信息.
监听master与slave的状态
如果某slave失效,直接通知master去除该slave.
如果master失效,,是按照slave优先级(可配置), 选取1个slave做 new master
,把其他slave--> new master
疑问: sentinel与master通信,如果某次因为master IO操作频繁,导致超时,
此时,认为master失效,很武断.
解决: sentnel允许多个实例看守1个master, 当N台(N可设置)sentinel都认为master失效,才正式失效.
Sentinel选项配置
port 26379 # 端口
sentinel monitor mymaster 127.0.0.1 6379 2 ,
给主机起的名字(不重即可),
当2个sentinel实例都认为master失效时,正式失效
sentinel down-after-milliseconds mymaster 30000 #多少毫秒后连接不到master认为断开
sentinel can-failover mymaster yes #是否允许sentinel修改slave->master. 如为no,则只能监控,无权修改./ 当有多个哨兵时,只允许一个技能监控也能改
sentinel parallel-syncs mymaster 1 , # 一次性修改几个slave指向新的new master 防止master的IO剧增
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh , # 在重新配置new master,new slave过程,可以触发的脚本
查看哨兵状态:./src/redis-cli -h 192.168.3.231 -p 26379 info sentinel
关闭哨兵模式:./src/redis-cli -p 26379 shutdown
slave-priority 100 优先级(slave指定master) 越小越优先


十三、redis 与关系型数据库的适合场景
书签系统
create table book (
bookid int,
title char(20)
)engine myisam charset utf8;
insert into book values
(5 , 'PHP圣经'),
(6 , 'ruby实战'),
(7 , 'mysql运维')
(8, 'ruby服务端编程');
create table tags (
tid int,
bookid int,
content char(20)
)engine myisam charset utf8;
insert into tags values
(10 , 5 , 'PHP'),
(11 , 5 , 'WEB'),
(12 , 6 , 'WEB'),
(13 , 6 , 'ruby'),
(14 , 7 , 'database'),
(15 , 8 , 'ruby'),
(16 , 8 , 'server');
# 既有web标签,又有PHP,同时还标签的书,要用连接查询
select * from tags inner join tags as t on tags.bookid=t.bookid
where tags.content='PHP' and t.content='WEB';
换成key-value存储
用kv 来存储
set book:5:title 'PHP圣经'
set book:6:title 'ruby实战'
set book:7:title 'mysql运难'
set book:8:title ‘ruby server’
sadd tag:PHP 5
sadd tag:WEB 5 6
sadd tag:database 7
sadd tag:ruby 6 8
sadd tag:SERVER 8
查: 既有PHP,又有WEB的书
Sinter tag:PHP tag:WEB #查集合的交集
查: 有PHP或有WEB标签的书
Sunin tag:PHP tag:WEB
查:含有ruby,不含WEB标签的书
Sdiff tag:ruby tag:WEB #求差集
十四、Redis key 设计技巧
1: 把表名转换为key前缀 如, tag:
2: 第2段放置用于区分区key的字段--对应mysql中的主键的列名,如userid
3: 第3段放置主键值,如2,3,4...., a , b ,c
4: 第4段,写要存储的列名
set user:userid:9:username lisi
set user:userid:9:password 111111
set user:userid:9:email lisi@163.com
keys user:userid:9*
2 注意:
在关系型数据中,除主键外,还有可能其他列也步骤查询,
如上表中, username 也是极频繁查询的,往往这种列也是加了索引的.
转换到k-v数据中,则也要相应的生成一条按照该列为主的key-value
Set user:username:lisi:uid 9
这样,我们可以根据username:lisi:uid ,查出userid=9,
再查user:9:password/email ...
即username指向uid 再由uid 获取信息

完成了根据用户名来查询用户信息 php-redis扩展编译
1: 到pecl.php.net搜索redis
2: 下载stable版(稳定版)扩展
3: 解压,
4: 执行/php/path/bin/phpize (作用是检测PHP的内核版本,并为扩展生成相应的编译配置)
5: configure --with-php-config=/php/path/bin/php-config
6: make && make install
引入编译出的redis.so插件
1: 编辑php.ini
2: 添加
redis插件的使用
// get instance
$redis = new Redis();
// connect to redis server
$redis->open('localhost',6380);
$redis->set('user:userid:9:username','wangwu');
var_dump($redis->get('user:userid:9:username'));
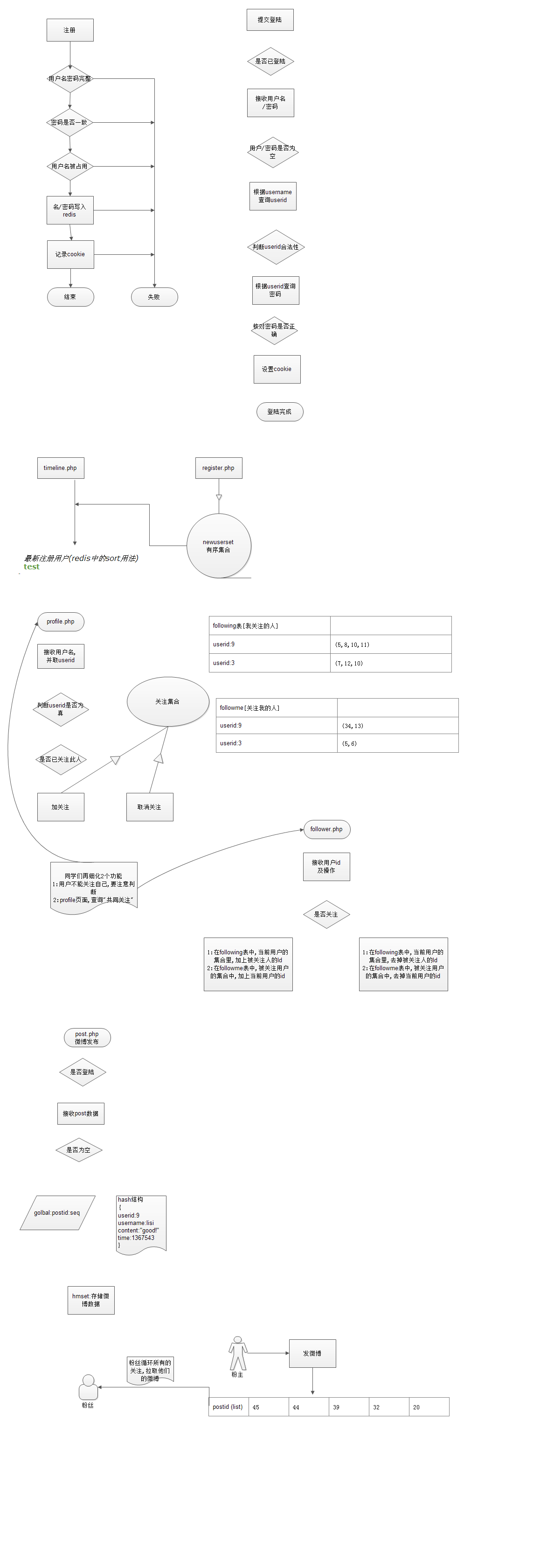
微博项目的key设计
全局相关的key:
| 表名 | global | |
| 列名 | 操作 | 备注 |
| Global:userid | incr | 产生全局的userid |
| Global:postid | Incr | 产生全局的postid |
用户相关的key(表)
| 表名 | user | ||
| Userid | Username | Password | Authsecret |
| 3 | Test3 | 1111111 | #U*Q(%_ |
在redis中,变成以下几个key
| Key前缀 | user | ||
| User:Userid:* | User:userid:*Username | User:userid:*Password | User:userid:*:Authsecret |
| User:userid:3 | User:userid:3:Test3 | User:userid:3:1111111 | User:userid:3:#U*Q(%_ |
微博相关的表设计
| 表名 | post | |||
| Postid | Userid | Username | Time | Content |
| 4 | 2 | Lisi | 1370987654f | 测试内容 |
微博在redis中,与表设计对应的key设计 hash
| Key前缀 | post | |||
| Post:Postid:* | Post:postid:*Userid | Post:postid:*:Username | Post:postid:*:Time | Post:postid:*:Content |
| 4 | 2 | Lisi | 1370987654f | 测试内容 |
set
关注表: following
Following:$userid -->
set
粉丝表
Follower:$userid --->
推送表:revicepost
Recivepost:$userid
| postid 3 | 4 | 7 |
=================拉模型,改进=====================
拉取表
Pull:$userid:
| posiid 3 | 4 | 7 |
问: 上次我拉取了 A->5,6,7,三条微博, 下次刷新home.php, 从>7的微博开始拉取
解决: 拉取时,设定一个lastpull时间点, 下次拉取时,取>lastpull的微博
问: 有很多关注人,如何取?
解决: 循环自己的关注列表,逐个取他们的新微博
问: 取出来之后放在哪儿?
答: pull:$userid的链接里
问: 如果个人中心,只有前1000条
答: ltrim,只取前1000条
问: 如果我关注 A,B两人, 从2人中,各取3条最新信息
,这3+3条信息, 从时间上,是交错的, 如何按时间排序?
答: 我们发布时, 是发布的hash结构, 不能按时间来排序.
解决: 同步时,取微博后,记录本次取的微博的最大id,
下次同步时,只取比最大id更大的微博
十五、AB测试
Time taken for tests: 32.690 seconds
Complete requests: 20000
Failed requests: 0
Write errors: 0
Non-2xx responses: 20000
Total transferred: 13520000 bytes
Total POSTed: 5340000
HTML transferred: 9300000 bytes
Requests per second: 611.80 [#/sec] (mean)
Time per request: 81.726 [ms] (mean)
Time per request: 1.635 [ms] (mean, across all concurrent requests)
Transfer rate: 403.88 [Kbytes/sec] received
159.52 kb/s sent
563.41 kb/s total
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.9 0 19
Processing: 14 82 8.4 81 153
Waiting: 4 82 8.4 80 153
Total: 20 82 8.2 81 153
Percentage of the requests served within a certain time (ms)
50% 81
66% 84
75% 86
80% 88
90% 93
95% 96
98% 100
99% 103
100% 153 (longest request)
测试结果:
50个并发, 20000次请求, 虚拟下,未做特殊优化
每次请求redis写操作6次.
30+秒左右完成.
平均每秒发布700条微博, 4000次redis写入.
后台定时任务,回归冷数据入mysql
Redis配置文件
daemonize yes # redis是否以后台进程运行
Requirepass 密码 # 配置redis连接的密码
注:配置密码后,客户端连上服务器,需要先执行授权命令
# auth 密码
分情破爱始乱弃,流落天涯思别离。
如花似玉负情意,影如白昼暗自迷。
随风浮沉千叶落,行色匆匆鬓已稀。

