

Lucene入门学习
技术原理:
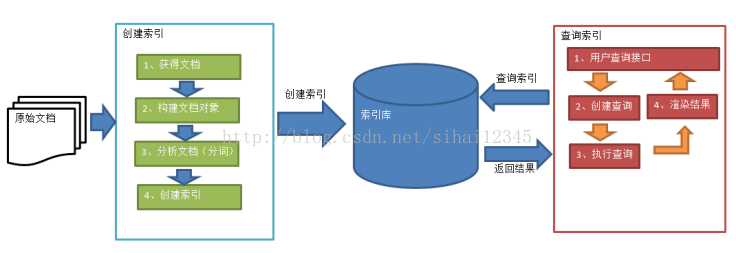
开发环境:
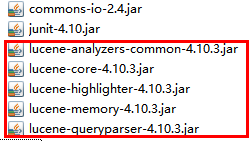
lucene包:分词包,核心包,高亮显示(highlight和memory),查询包。(下载请到官网去查看,如若下载其他版本,请看我的上篇文档,在luke里面)
原文文档:
入门程序:
1 package com.itheima.lucene; 2 3 import java.io.File; 4 import java.io.FileReader; 5 6 import org.apache.lucene.analysis.Analyzer; 7 import org.apache.lucene.analysis.standard.StandardAnalyzer; 8 import org.apache.lucene.document.Document; 9 import org.apache.lucene.document.Field; 10 import org.apache.lucene.document.TextField; 11 import org.apache.lucene.index.DirectoryReader; 12 import org.apache.lucene.index.IndexWriter; 13 import org.apache.lucene.index.IndexWriterConfig; 14 import org.apache.lucene.queryparser.classic.QueryParser; 15 import org.apache.lucene.search.IndexSearcher; 16 import org.apache.lucene.search.Query; 17 import org.apache.lucene.search.ScoreDoc; 18 import org.apache.lucene.search.TopDocs; 19 import org.apache.lucene.store.Directory; 20 import org.apache.lucene.store.FSDirectory; 21 import org.apache.lucene.util.Version; 22 23 /** 24 * 25 * @author 26 * 27 */ 28 public class Test1 { 29 30 //创建索引 31 public static void index() { 32 IndexWriter indexWriter = null; 33 34 try { 35 // 1、创建Directory 36 //JDK 1.7以后 open只能接收Path 37 Directory directory = FSDirectory.open(new File("E:\\spider\\index")); 38 // 2、创建IndexWriter 39 Analyzer analyzer = new StandardAnalyzer(); 40 IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer); 41 indexWriter = new IndexWriter(directory, config); 42 indexWriter.deleteAll();//清除以前的index 43 //要搜索的File路径 44 File dFile = new File("E:\\spider\\2018-12-26"); 45 File[] files = dFile.listFiles(); 46 for (File file : files) { 47 // 3、创建Document对象 48 Document document = new Document(); 49 // 4、为Document添加Field 50 // 第三个参数是FieldType 但是定义在TextField中作为静态变量,看API也不好知道怎么写 51 document.add(new Field("content", new FileReader(file), TextField.TYPE_NOT_STORED)); 52 document.add(new Field("filename", file.getName(), TextField.TYPE_STORED)); 53 document.add(new Field("filepath", file.getAbsolutePath(), TextField.TYPE_STORED)); 54 55 // 5、通过IndexWriter添加文档到索引中 56 indexWriter.addDocument(document); 57 } 58 59 } catch (Exception e) { 60 e.printStackTrace(); 61 } finally { 62 try { 63 if (indexWriter != null) { 64 indexWriter.close(); 65 } 66 } catch (Exception e) { 67 e.printStackTrace(); 68 } 69 } 70 } 71 72
73 //搜索 74 75 public static void search(String keyWord) { 76 DirectoryReader directoryReader = null; 77 try { 78 // 1、创建Directory 79 Directory directory = FSDirectory.open(new File("E:\\spider\\index")); 80 // 2、创建IndexReader 81 directoryReader = DirectoryReader.open(directory); 82 // 3、根据IndexReader创建IndexSearch 83 IndexSearcher indexSearcher = new IndexSearcher(directoryReader); 84 85 // 4、创建搜索的Query 86 Analyzer analyzer = new StandardAnalyzer(); 87 // 创建parser来确定要搜索文件的内容,第一个参数为搜索的域 88 QueryParser queryParser = new QueryParser("content", analyzer); 89 // 创建Query表示搜索域为content包含UIMA的文档 90 Query query = queryParser.parse(keyWord); 91 92 // 5、根据searcher搜索并且返回TopDocs 93 TopDocs topDocs = indexSearcher.search(query, 10); 94 System.out.println("查找到的文档总共有:"+topDocs.totalHits); 95 96 // 6、根据TopDocs获取ScoreDoc对象 97 ScoreDoc[] scoreDocs = topDocs.scoreDocs; 98 for (ScoreDoc scoreDoc : scoreDocs) { 99 100 // 7、根据searcher和ScoreDoc对象获取具体的Document对象 101 Document document = indexSearcher.doc(scoreDoc.doc); 102 103 // 8、根据Document对象获取需要的值 104 System.out.println("文件名:"+document.get("filename") + " " +"文件路径:"+ document.get("filepath")); 105 System.out.println("-----------------------------------------"); 106 } 107 108 } catch (Exception e) { 109 e.printStackTrace(); 110 } finally { 111 try { 112 if (directoryReader != null) { 113 directoryReader.close(); 114 } 115 } catch (Exception e) { 116 e.printStackTrace(); 117 } 118 } 119 } 120 121
122 //主方法 123 public static void main(String args[]) { 124 index(); 125 126 search("java");//搜索带 java语汇单元的信息。(单词) 127 } 128 }
结果显示:

(学习路径还很长,不要捉急慢慢来)。
本文来自博客园,作者:土木转行的人才,转载请注明原文链接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号