Redis多种数据类型以及使用场景
小结
-
字符串内部编码:int embstr raw,用途:缓存。
-
哈希内部编码:压缩ziplist hashtable
-
列表内部编码:压缩ziplist linkedlist,用途:消息队列。
-
集合内部编码:intset hashtable,用途:标签,计算用户共同感兴趣的标签。sinter user:1:tags user:2:tags
-
有序集合内部编码:压缩ziplist 跳跃表zskiplist,用途:热评的排行榜。zrevrangebyrank user:ranking:2016_0315 0 9
-
Bitmaps用途:通过极小空间进行位运算实现对状态的判断,例如可以做一个答题瓜分奖励的活动,每个用户答题答对可以设置
setbit user 1 1,然后后用bitcount统计有多少个1,看用户答对了多少题。
跳跃表
跳跃表支持平均OlogN、最坏ON复杂度的节点查找。
在大部分情况下,跳跃表的效率可以和平衡树相媲美,Redis使用跳跃表作为有序集合的底层实现之一。
实现
由redis.h/zskiplistNode和redis.h/zskiplist两个结构定义,zskiplistNode表示跳跃表节点,而zskiplist保存跳跃表
节点的相关信息,比如节点数量,以及表头节点和表尾结点的指针。
zskiplist结构:头结点header,尾结点tail,层数level,长度length。
zskiplistNode结构:层level(层中有前进指针和跨度),后退指针backwrad,分值score,成员对象obj。
SDS简单动态字符串
struct sdshdr {
// 记录buf数组中已使用字节的数量
// 等于SDS所保存字符串的长度
int len;
// 记录buf数组中未使用字节的数量
int free;
// 字节数组,用于保存字符串
char buf[];
}
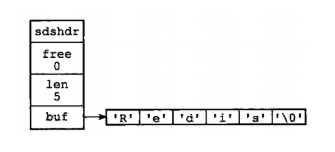
-
free表示这个SDS没有分配 未使用空间。
-
len表示SDS保存了无字节长的字符串。
-
buf是一个char数组。
SDS与C字符串区别
-
O(1)复杂度获取字符串长度。
-
防止缓冲区溢出。
-
减少修改字符串时带来的内存重分配次数。
字符串
命令
set key value [ex seconds] [px milliseconds] [nx|xx]
内部编码
字符串类型的内部编码有3种:
-
int:8个字节长整型。
-
embstr:小于等于39个字节的字符串。
-
raw:大于39个字节的字符串。
Redis会根据当前值的类型和长度决定使用哪种内部编码实现。
整数:
set key 8653
ok
object encoding key
"int"
短字符:
set key "hello"
ok
object encoding key
"embstr"
长字符:
set key "40 bytes"
ok
object encoding key
"raw"
使用场景
-
缓存
-
计数
-
Session集中管理
-
限速
哈希
命令
hset key field value
hset uset:1 name tom
hget key field
hget uset:1 name
"tom"
内部编码
- ziplist(压缩列表):哈希类型元素个数小于hash-max-ziplist-entries默认512个、同时所有值都小于hash-max-
ziplist-value配置时,Redis会使用ziplist实现,节省内存方面比hashtable优秀。
- hashtable:哈希类型无法满足ziplist条件时,会用这个,hashtable的读写时间复杂度都是O(1)。
hset hashkey f3 "bigger than 64 bytes"
object encoding hashkey
"hashtable"
hmset hashkey f1 v1 f2 v2 f3 v3 ...... f513 v513
object encoding hashkey
"hashtable"
列表
从右边插入元素:rpush key value
lrange listkey 0 -1
从左边插入元素:lpush key value
linsert key before | after pivot value
查找:lrange key start end
删除:lpop key
内部编码
-
ziplist:元素个数小于list-max-ziplist-entries,同时每个值都小于list-max-ziplist-value,Redis选用压缩列表减少内存。
-
linkedlist:无法满足ziplist就会用链表来实现。
使用场景
-
消息队列
-
文章列表
集合
用来保存多个的字符串元素,不允许重复元素,无序。
sadd key a b c 添加key
3
srem key a b 删除key
2
scard key 计算key
1
smembers key 获取所有元素
sinter key 求交集
suinon key 求并集
sdiff key 求差集
内部编码
-
intset(整数集合)
-
hashtable
使用场景
标签(tag)
给用户添加标签
sadd user:1:tags tag1 tag2 tag3
sadd uset:1:tags tag1 tag2 tag3
给标签添加用户
sadd tag1:users user:1 user:3
sadd tag2:users user:1 user:2
计算用户共同感兴趣的标签
sinter user:1:tag2 user:2:tag
有序集合
不能重复,可以排序的set,给每个元素设置了一个score作为排序的依据。
列表、集合和有序集合三者异同点

命令
zadd key score member 添加成员
zadd user:ranking 251 tom
有序集合提供排序字段,产生代价,zadd复杂度为Ologn,sadd为O1。
zcard user:ranking 计算成员数
zscore key member 返回某个成员分数
zrank key member 计算成员的排名
zrem key member 删除成员
zrange ...
集合间的操作
(1)交集
(2)并集
内部编码
-
压缩列表
-
跳跃表
使用场景
添加用户赞数:
zadd user:ranking:2016_03_15 mike 3
获得赞后:
zincrby user:ranking:2016_03_15 mike 1
取消赞:
zrem
获取赞数最多的十个用户:
zrevrangebyrank user:ranking:2016_0315 0 9
展示用户信息以及用户分数:
此功能将用户名作为键后缀,将用户信息保存在哈希类型中,至于用户的分数和排名可以使用zscore和zrank
hgetall user:info:tom
zscore user:ranking:2016_03_15 mike
zrank user:ranking:2016_03_15 mike
Bitmaps
Bitmap通常被用来在极小空间消耗下通过位的运算(AND/OR/XOR/NOT)实现对状态的判断,常见的使用场景例如:“答对12道题的同学有机会瓜分奖池”,这种如果使用bitmap来实现,就非常容易判断出用户是否全部答对。
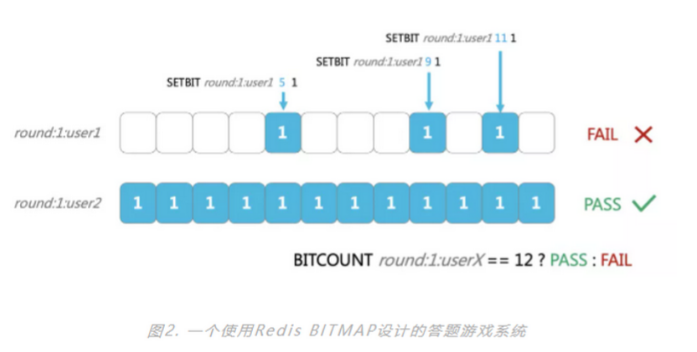
答题系统设计如下:
- 每个用户每轮答题,设置一个key,比如user1在第一轮答题的key是 round:1:user1。
- 每答对一道题,设置相关的bit为1,比如user1答对了第5题,那么就设置第5个bit为1就可以了,如:SETBIT round:1:user1 5 1 ;如果用户1在第一轮答对了第9题,那么就把第9个bit设置为1,SETBIT round:1:user1 9 1;值得注意的是,Bitmaps默认bit都是0,答错可以不设置。
- 计算用户总共答对了几道题,就可以使用 BITCOUNT 命令统计1的bit个数。
可见,Redis的bitmap接口可以用非常高的存储效率和计算加速效果。
待更新:
HyperLogLog
GEO
Reference
《Redis设计与实现》
《Redis开发与运维》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号