
【python爬虫课程设计】新冠疫情下的中国与世界——绘制疫情柱状图和词云
一、选题的背景
1.背景:在2021年的末尾,因为新冠病毒的变异和全球疫苗的不平衡,全球疫情再度面临严峻态势。现已临近年底,回国返乡的人数不断增加,随之而来的便是外来输入病例的增加。全国的疫情也经常在部分地区上有小爆发的情况发生。
2.目的:为此背景下,我想对本次新冠疫情在全球范围内和在我国境内的传播情况进行python的数据爬取和分析,使了解疫情情况的同时,自身的编程水平也得到锻炼与提高。并在项目开始之前提出问题:我国各省现有确诊人数最多的是哪儿个省?全球范围内现有确诊人数最多的是哪儿三个国家?让我们带着问题进行探索。
二、主题式网络爬虫设计方案
1.主题式网络爬虫名称
【python爬虫课程设计】新冠疫情下的中国与世界——绘制疫情柱状图和词云
2.主题式网络爬虫爬取的内容与数据特征分析
爬取相关疫情实时数据,包含地区,累计确诊病例,现有确诊病例等数据,包含国内与全球的疫情数据。并通过数据可视化表现出来。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路: 1. 数据采集。具体来源于
https://voice.baidu.com/act/newpneumonia/newpneumonia/?
2. 进行数据的清洗,对需要的数据进行定位和提取,并进行存取。
3. 传入数据,绘制词云和进一步数据可视化。
技术难点:1.节点的寻找。
2.数据可视化的灵活运用。
三、主题页面的结构特征分析
1.寻找所需的数据。登录网站,右键网络源代码。
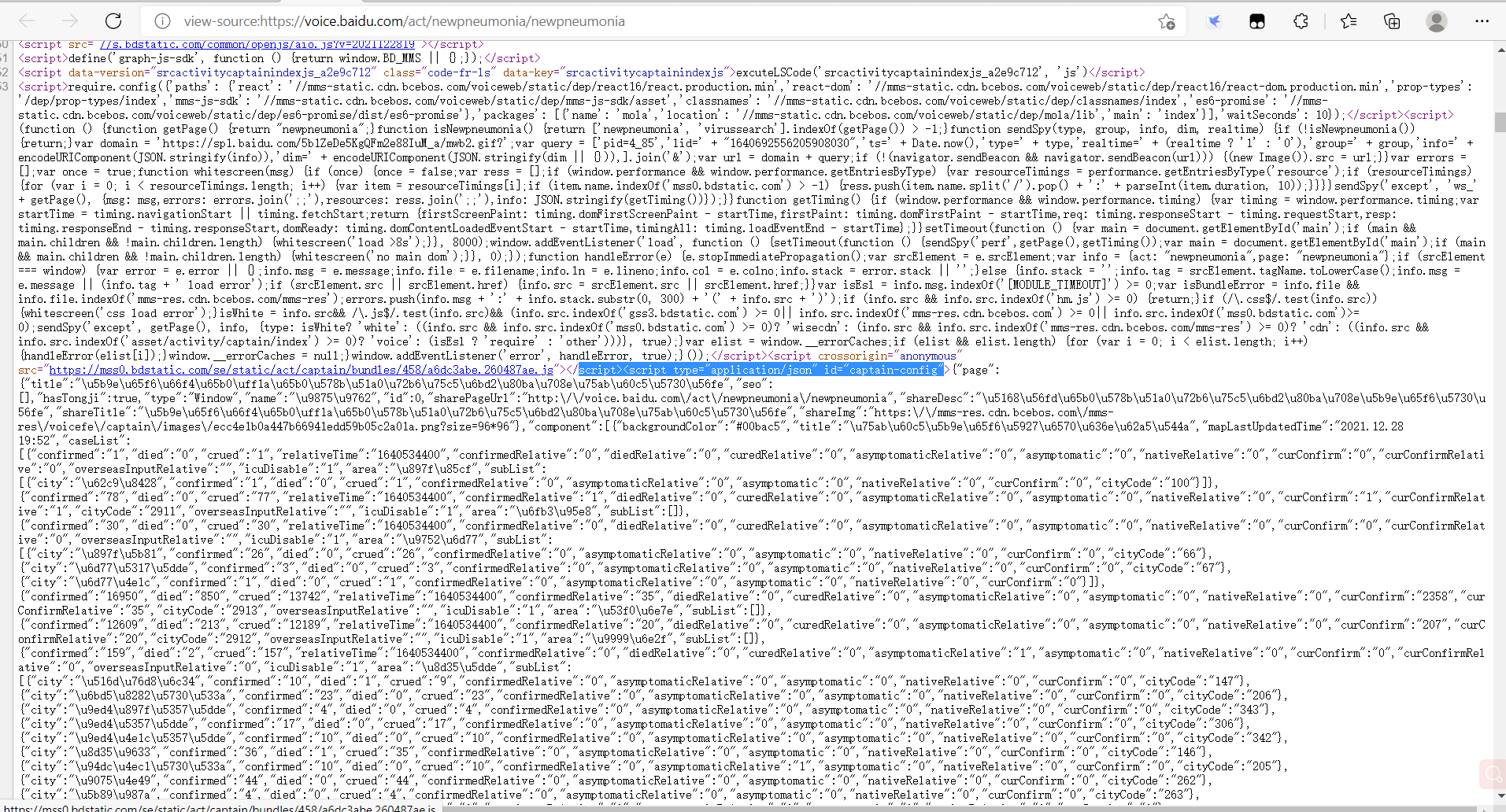
2.Htmls 页面解析
josn格式可以观察到每个数据都可以通过索引得到。通过字典索引即可得到需要数据。
3.节点(标签)查找方法与遍历方法
经分析数据是由一个script标签包裹起来。因此可以用xpath语法整理数据。
四、网络爬虫程序设计
1.爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1 import requests 2 from lxml import etree 3 import json 4 import openpyxl 5 6 url="https://voice.baidu.com/act/newpneumonia/newpneumonia/?" 7 response=requests.get(url) 8 # print(response.text) 9 # 生成HTML对象 10 html=etree.HTML(response.text) 11 result=html.xpath('//script[@type="application/json"]/text()') 12 result=result[0] 13 14 #json.loads(方法可以将字符串转化为python数据类型) 15 result=json.loads(result) 16 17 18 # 创建一个工作簿 19 wb = openpyxl.Workbook() 20 21 # 创建一个工作表 22 ws=wb.active 23 ws.title = "国内疫情" 24 25 # 对表的第一行进行解释说明 26 ws.append(["省份","累计确诊","死亡","治愈","现有确诊","累计确诊增量","死亡增量","治愈增量","现有确诊增量"]) 27 28 #分别对字典中国内和国外的的值进行采集 29 result_in=result['component'][0]['caseList'] 30 result_out=result['component'][0]['globalList'] 31 32 33 #传入相对应的数据 34 for each in result_in: 35 temp_list=[each['area'],each['confirmed'],each['died'],each['crued'],each['curConfirm'],each['curConfirmRelative'], 36 each['diedRelative'],each['curedRelative'],each['curConfirmRelative']] 37 ws.append(temp_list) 38 39 for each in result_out: 40 sheet_title=each['area'] 41 42 #创建新的工作表 43 ws_out=wb.create_sheet(sheet_title) 44 45 #对表的第一行进行解释说明 46 ws_out.append(['国家','累计确诊','死亡','治愈','现有确诊','累计确诊增量']) 47 for country in each['subList']: 48 temp_list=[country['country'],country['confirmed'],country['died'],country['crued'], 49 country['curConfirm'],country['confirmedRelative']] 50 51 52 ws_out.append(temp_list) 53 54 #输出文件 55 wb.save('.EXCEL.xlsx') 56 57 58 """ 59 area-->省份/直辖市/特别行政区等 60 city-->城市 61 confirmed-->累计确诊人数 62 died--> 死亡人数 63 crued--> 治愈人数 64 curConfirmRelative-->累计确诊的增量 65 curedRelative-->治愈的增量 66 curConfirm-->现有确诊人数 67 curConfirmRelative-->现有确诊的增量 68 diedRelative-->死亡的增量 69 70 """
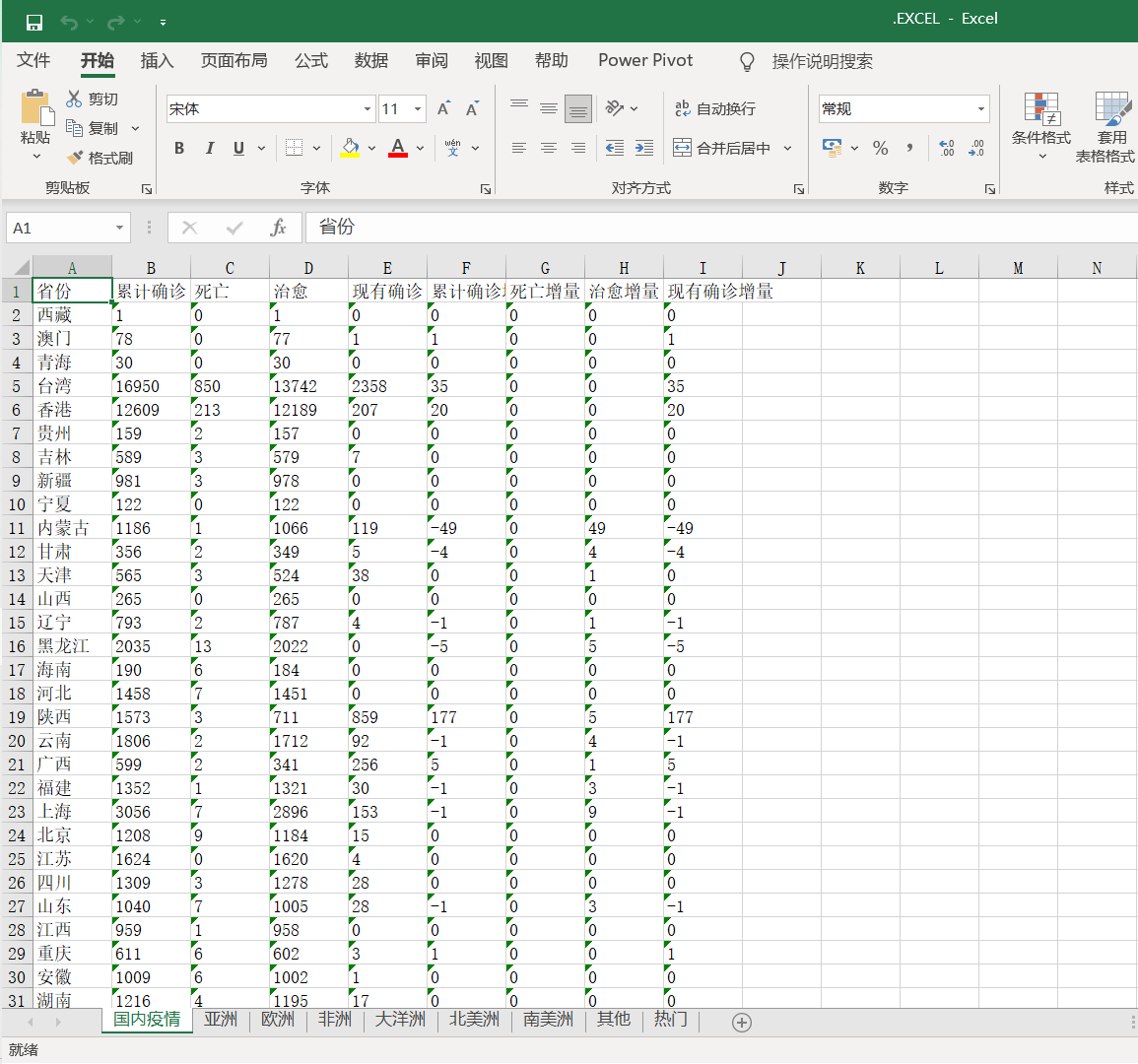
运行后:

打开文件: 国内疫情
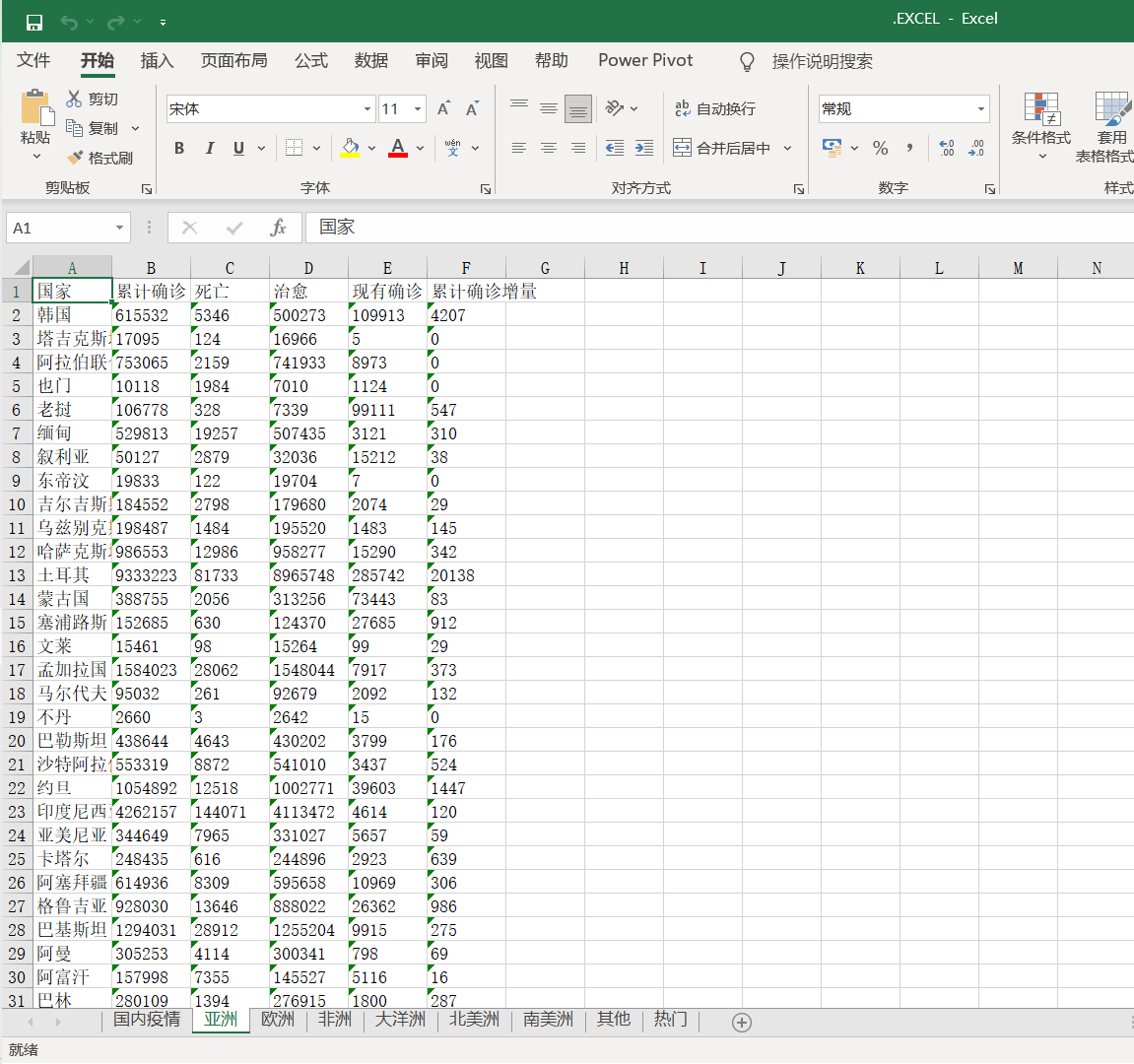
国外疫情——亚洲
2.绘制wordcloud
1 import openpyxl 2 #绘制词云需要导入的模块 3 from wordcloud import WordCloud 4 5 #读取数据 6 wb=openpyxl.load_workbook('.data3.xlsx') 7 8 #获取工作表 9 ws=wb['国内疫情'] 10 frequency_in={} 11 #遍历每个省份的值 12 for row in ws.values: 13 14 #去掉第一行 15 if row[0]=='省份': 16 pass 17 else: 18 frequency_in[row[0]]=float(row[1]) 19 20 21 frequency_out={} 22 sheet_names=wb.sheetnames 23 for each in sheet_names: 24 if "洲" in each: 25 ws=wb[each] 26 for row in ws.values: 27 if row [0]=='国家': 28 pass 29 else: 30 frequency_out[row[0]]=float(row[1]) 31 32 def yiqingciyun(frequency,name): 33 wordcloud = WordCloud(font_path="C:/Windows/Fonts/STLITI.TTF", 34 background_color="white", 35 width=2021, height=1080) 36 37 #根据确诊病例的数目生成词云 38 wordcloud.generate_from_frequencies(frequency) 39 40 #保存词云 41 wordcloud.to_file('%s.png'%(name)) 42 43 #绘制词云,生成png文件 44 yiqingciyun(frequency_in,'国内疫情情况词云图') 45 yiqingciyun(frequency_out,'世界疫情情况词云图')
生成两个png文件
国内疫情词云图

国外疫情词云图

3.数据可视化
1.绘制中国各省市的现有确诊人数
1 # 绘制中国各省市的现有确诊人数 2 # 导入pyecharts绘图库 3 from pyecharts import options as opts 4 from pyecharts.charts import Bar 5 from pyecharts.commons.utils import JsCode 6 from pyecharts.globals import ThemeType 7 import pandas as np 8 9 # 读取原先收集好的数据 10 df=np.read_excel('WORLD.xlsx') 11 a=df['现有确诊'].values.tolist() 12 13 print(a) 14 c = ( 15 Bar({"theme": ThemeType.MACARONS}) 16 .add_xaxis(df['省份'].values.tolist()) 17 .add_yaxis("现有确诊人数",a) 18 19 20 .set_global_opts( 21 title_opts={"text": "Bar-通过 dict 进行配置"} 22 ) 23 # 生成html文件 24 .render("confirmdied2.html") 25 )
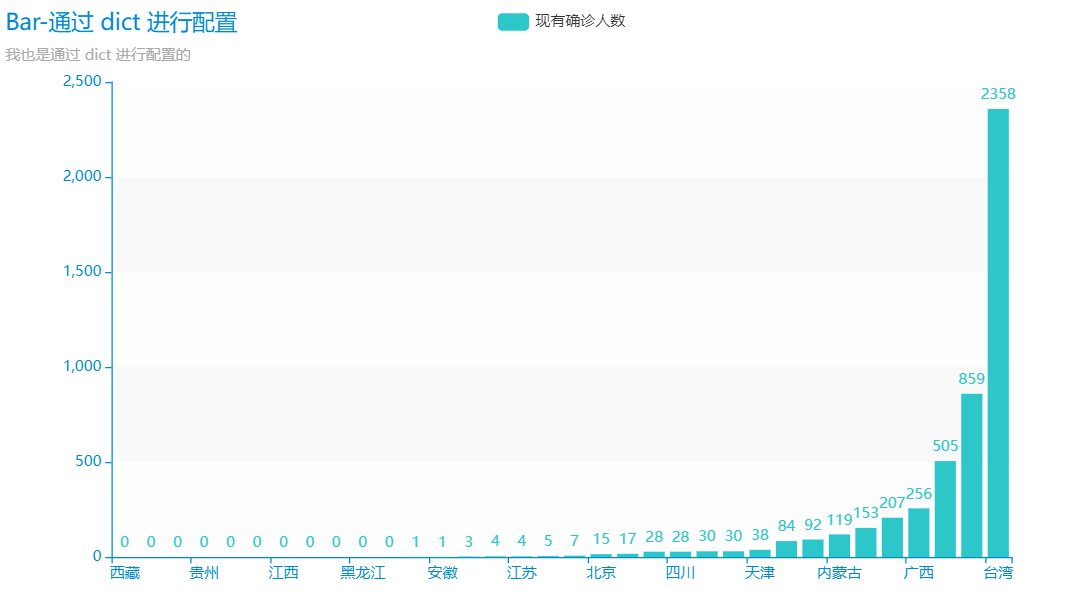
2.绘制中国各省市的累计确诊人数和死亡人数对比
1 # 绘制中国各省市的累计感染人数和死亡人数对比 2 # 导入pyecharts绘图库 3 from pyecharts import options as opts 4 from pyecharts.charts import Bar 5 from pyecharts.commons.utils import JsCode 6 from pyecharts.globals import ThemeType 7 import pandas as np 8 9 #读取原先收集好的数据 10 df=np.read_excel('WORLD.xlsx') 11 a=df['累计确诊'].values.tolist() 12 b=df['死亡'].values.tolist() 13 14 print(a) 15 c = ( 16 Bar({"theme": ThemeType.MACARONS}) 17 .add_xaxis(df['省份'].values.tolist()) 18 .add_yaxis("确诊人数",a) 19 .add_yaxis("死亡人数",b) 20 21 .set_global_opts( 22 title_opts={"text": "Bar-通过 dict 进行配置""} 23 ) 24 # 生成html文件 25 .render("confirmdied.html") 26 )

特点:定义两个纵坐标,实现更美观的可视化。
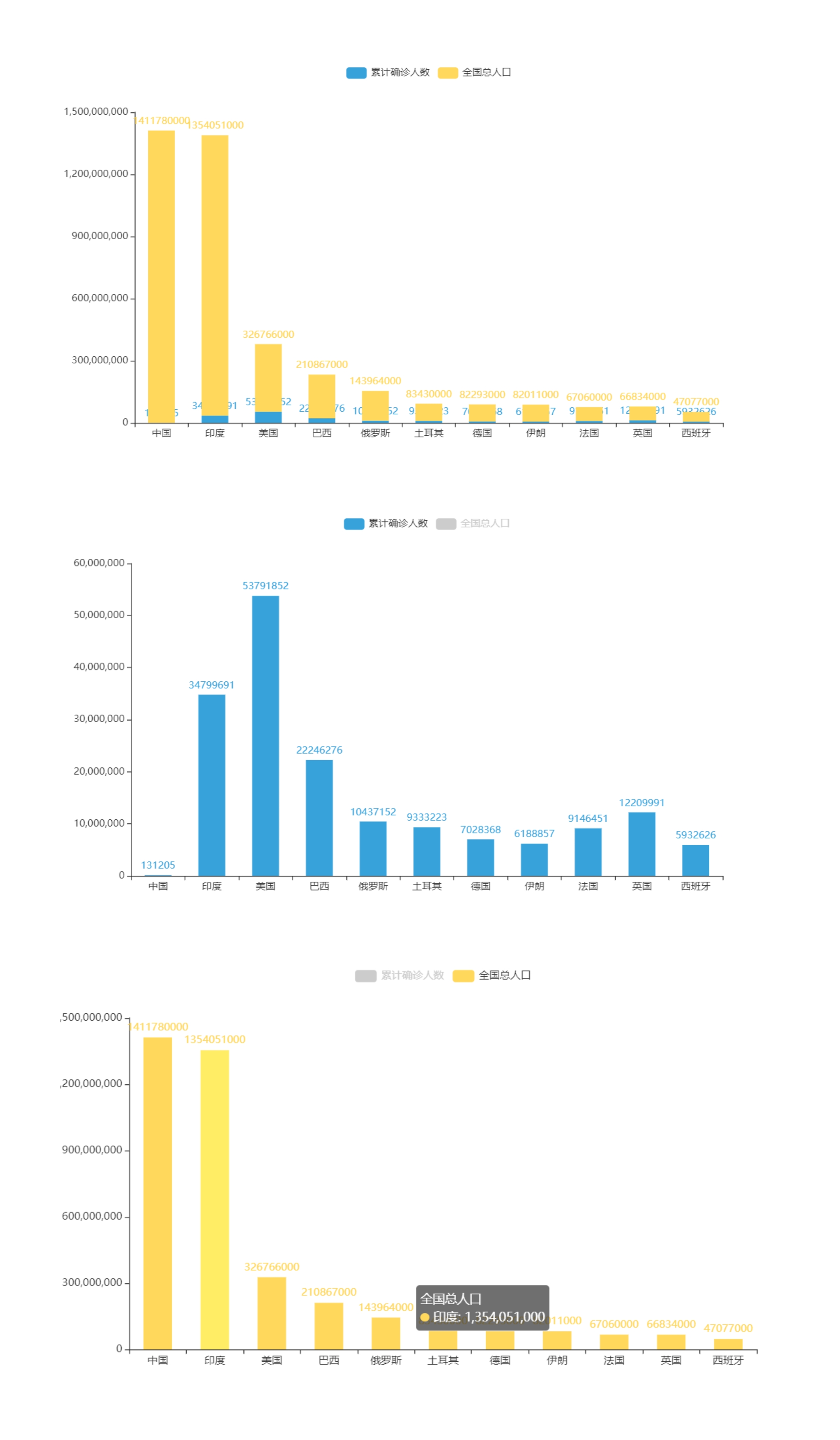
3.中国和世界其他大国人口和本次疫情下累计确诊人数对比
1 from pyecharts import options as opts 2 from pyecharts.charts import Bar 3 from pyecharts.commons.utils import JsCode 4 from pyecharts.globals import ThemeType 5 import pandas as np 6 7 # 读取原先收集好的数据 8 df=np.read_excel('WORLD.xlsx',sheet_name='热门') 9 a=df['累计确诊'].values.tolist() 10 b=df['总人口'].values.tolist() 11 12 c = ( 13 Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT)) 14 .add_xaxis(df["国家"].values.tolist()) 15 .add_yaxis("累计确诊人数",a,stack="stack1", category_gap="50%") 16 .add_yaxis("全国总人口",b,stack="stack1", category_gap="50%") 17 18 #生成文件 19 .render("111.html") 20 )
通过增加预设的各国人口数值,使总人口数与累计确诊人数想对应,使各国的疫情防控情况对比的一目了然。
四、附完整程序源代码
1 #数据采集 2 import requests 3 from lxml import etree 4 import json 5 import openpyxl 6 7 url="https://voice.baidu.com/act/newpneumonia/newpneumonia/?" 8 response=requests.get(url) 9 10 # print(response.text) 11 # 生成HTML对象 12 13 html=etree.HTML(response.text) 14 result=html.xpath('//script[@type="application/json"]/text()') 15 result=result[0] 16 17 #json.loads(方法可以将字符串转化为python数据类型) 18 result=json.loads(result) 19 20 21 # 创建一个工作簿 22 wb = openpyxl.Workbook() 23 24 25 # 创建一个工作表 26 ws=wb.active 27 ws.title = "国内疫情" 28 29 30 # 对表的第一行进行解释说明 31 ws.append(["省份","累计确诊","死亡","治愈","现有确诊","累计确诊增量","死亡增量","治愈增量","现有确诊增量"]) 32 33 34 #分别对字典中国内和国外的的值进行采集 35 result_in=result['component'][0]['caseList'] 36 result_out=result['component'][0]['globalList'] 37 38 39 #传入相对应的数据 40 for each in result_in: 41 temp_list=[each['area'],each['confirmed'],each['died'],each['crued'],each['curConfirm'],each['curConfirmRelative'], 42 each['diedRelative'],each['curedRelative'],each['curConfirmRelative']] 43 ws.append(temp_list) 44 45 for each in result_out: 46 sheet_title=each['area'] 47 48 #创建新的工作表 49 ws_out=wb.create_sheet(sheet_title) 50 51 #对表的第一行进行解释说明 52 ws_out.append(['国家','累计确诊','死亡','治愈','现有确诊','累计确诊增量']) 53 for country in each['subList']: 54 temp_list=[country['country'],country['confirmed'],country['died'],country['crued'], 55 country['curConfirm'],country['confirmedRelative']] 56 57 58 ws_out.append(temp_list) 59 60 #输出文件 61 wb.save('WORLD.xlsx') 62 63 64 """ 65 area-->省份/直辖市/特别行政区等 66 city-->城市 67 confirmed-->累计确诊人数 68 died--> 死亡人数 69 crued--> 治愈人数 70 curConfirmRelative-->累计确诊的增量 71 curedRelative-->治愈的增量 72 curConfirm-->现有确诊人数 73 curConfirmRelative-->现有确诊的增量 74 diedRelative-->死亡的增量 75 76 """ 77 78 79 80 # -------------------------------------------------------------------------- 81 82 83 84 # 绘制疫情防控图片词云 85 import openpyxl 86 #绘制词云需要导入的模块 87 from wordcloud import WordCloud 88 89 #读取数据 90 wb=openpyxl.load_workbook('.data3.xlsx') 91 92 #获取工作表 93 ws=wb['国内疫情'] 94 frequency_in={} 95 #遍历每个省份的值 96 for row in ws.values: 97 98 #去掉第一行 99 if row[0]=='省份': 100 pass 101 else: 102 frequency_in[row[0]]=float(row[1]) 103 104 105 frequency_out={} 106 sheet_names=wb.sheetnames 107 for each in sheet_names: 108 if "洲" in each: 109 ws=wb[each] 110 for row in ws.values: 111 if row [0]=='国家': 112 pass 113 else: 114 frequency_out[row[0]]=float(row[1]) 115 116 def yiqingciyun(frequency,name): 117 wordcloud = WordCloud(font_path="C:/Windows/Fonts/STLITI.TTF", 118 background_color="white", 119 width=2021, height=1080) 120 121 #根据确诊病例的数目生成词云 122 wordcloud.generate_from_frequencies(frequency) 123 124 #保存词云 125 wordcloud.to_file('%s.png'%(name)) 126 127 128 129 # -------------------------------------------------------------------------- 130 131 132 133 #绘制词云,生成png文件 134 135 yiqingciyun(frequency_in,'国内疫情情况词云图') 136 yiqingciyun(frequency_out,'世界疫情情况词云图') 137 138 # 绘制中国各省市的累计感染人数和死亡人数对比 139 # 导入pyecharts绘图库 140 from pyecharts import options as opts 141 from pyecharts.charts import Bar 142 from pyecharts.commons.utils import JsCode 143 from pyecharts.globals import ThemeType 144 import pandas as np 145 146 #读取原先收集好的数据 147 df=np.read_excel('WORLD.xlsx') 148 a=df['累计确诊'].values.tolist() 149 b=df['死亡'].values.tolist() 150 151 print(a) 152 c = ( 153 Bar({"theme": ThemeType.MACARONS}) 154 .add_xaxis(df['省份'].values.tolist()) 155 .add_yaxis("确诊人数",a) 156 .add_yaxis("死亡人数",b) 157 158 .set_global_opts( 159 title_opts={"text": "Bar-通过 dict 进行配置", "subtext": "我也是通过 dict 进行配置的"} 160 ) 161 # 生成html文件 162 .render("confirmdied.html") 163 ) 164 165 166 167 # -------------------------------------------------------------------------- 168 169 170 171 # 绘制中国各省市的现有确诊人数 172 # 导入pyecharts绘图库 173 from pyecharts import options as opts 174 from pyecharts.charts import Bar 175 from pyecharts.commons.utils import JsCode 176 from pyecharts.globals import ThemeType 177 import pandas as np 178 179 # 读取原先收集好的数据 180 df=np.read_excel('WORLD.xlsx') 181 a=df['现有确诊'].values.tolist() 182 183 print(a) 184 c = ( 185 Bar({"theme": ThemeType.MACARONS}) 186 187 .add_xaxis(df['省份'].values.tolist()) 188 .add_yaxis("现有确诊人数",a) 189 190 191 .set_global_opts( 192 title_opts={"text": "Bar-通过 dict 进行配置"} 193 ) 194 # 生成html文件 195 .render("confirmdied2.html") 196 ) 197 198 199 200 # -------------------------------------------------------------------------- 201 202 203 204 # 绘制中国和世界上其他大国的累计确诊人数对比 205 from pyecharts import options as opts 206 from pyecharts.charts import Bar 207 from pyecharts.commons.utils import JsCode 208 from pyecharts.globals import ThemeType 209 import pandas as np 210 211 # 读取原先收集好的数据 212 df=np.read_excel('WORLD.xlsx',sheet_name='热门') 213 a=df['累计确诊'].values.tolist() 214 b=df['总人口'].values.tolist() 215 216 c = ( 217 Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT)) 218 .add_xaxis(df["国家"].values.tolist()) 219 .add_yaxis("累计确诊人数",a,stack="stack1", category_gap="50%") 220 .add_yaxis("全国总人口",b,stack="stack1", category_gap="50%") 221 222 #生成文件 223 .render("111.html") 224 ) 225 226 227 228 # --------------------------------END-----------------------------------------
五、总结
1.总结
通过本次的课程设计学习,我们可以很轻松的回答课程开始之初我们提出的两个问题。我国各省现有确诊人数最多的是——台湾省。全球范围内现有确诊人数最多的三个国家分别是美国,印度和巴西。
2.目标
已经达到我预期的目标。通过对爬取的数据进行数据可视化分析,可以较便捷得看出我国在疫情防控中的工作是有效果的,且是远超世界上其他大国的。但在我国各省看来,疫情的可控性还需要加强。还需要我们每个人付出努力。也期盼之后的春节我们的国家可以国泰民安。
3.自我建议
(1)加强自身独立自主的能力,提高编程技能。在本次课程设计中,询问了室友许多的内容。自己在编程上的功底薄弱,有待加强。
(2)多逛csdn等编程学习平台,扎实自身,并打开视野。
