联邦学习综述
1. 背景介绍
-
系统部署
移动手机和可穿戴设备是现代十分常见的数据产生设备。这些设备每天都会产生巨量的各种形式的数据。考虑到算力需求,数据传输以及个人隐私的限制,系统部署越来越倾向于在本地存储数据,模型计算由边缘设备完成。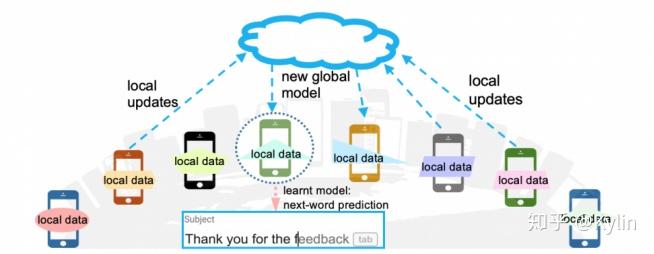
-
数据孤岛
数据往往以孤岛形式出现。在现实中想要将分散在各地、各个机构的数据进行整合几乎是不可能的,或者说所需的成本是巨大的。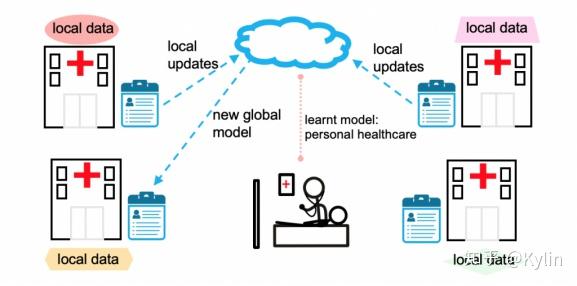
2. 联邦学习概念
- 本质:一种分布式机器学习技术,或机器学习框架,让人工智能系统能够更加高效、准确的共同使用各自的数据,实现共同建模,提高 AI 模型的效果。
- 公式化定义
经典的联邦学习问题需要从上百万的远程设备中存储的海量数据里面学习到一个全局统计模型。这个任务可以用以下目标函数来表述:
$ min \quad F(w), \quad where \quad F(w) := \Sigma^{m}_{k=1}{p}_k{F}_k(w) $
- 其中 m 代表设备总量,\(F_k\) 为第 k 个设备的本地目标函数,\(p_k\) 被定义为对应设备的影响权重。
- \(p_k\) 具有性质:\(p_k\) ≥ 0,且 \(\Sigma^{m}_{k=1}{p}_k = 1\)。
- \(F_k\)通常被定义为基于本地数据的经验风险。
-
联邦学习与现有研究的区别
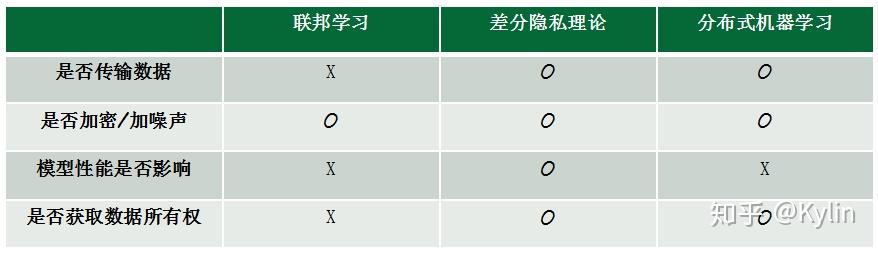
联邦学习中工作节点代表的是模型训练的数据拥有方,其对本地的数据具有完全自治的权限,可以自主决定何时加入联邦学习进行建模,相对地在参数服务器中,中心节点始终占据着主导地位。
联邦学习本质上仍是一种分布式机器学习,所以不完全认同该图中与分布式机器学习的区别,况且完全可以设计不需要传输数据,只传输梯度的分布式机器学习。
- 联邦学习与传统分布式学习的区分

- 用户对于自己的设备和有着控制权。传统分布式往往由 server 控制。
- Worker节点是不稳定的,比如手机可能突然就没电了,或者进入了电梯突然没信号了等情况。传统分布式学习 worker 往往是在机房中,稳定。
- 通信代价往往比计算代价要高。联邦学习 worker 往往通过无线通信,通信时延大。
- 分布在Worker节点上的数据并不是独立同分布的(not IID),因此很多已有的减少通信次数的算法就不适用。
- 节点负载不平衡,有的设备数据多有的设备数据少。比如有的用户几天拍一张照片有的用户一天拍好多照片,这给建模带来了困难。如果给图片的权重一样,那么模型可能往往取决于拍图片多的用户,拍照少的用户就被忽略了。如果用户的权重相同,这样学出来的模型对拍照多的用户又不太好了。负载不平衡也给计算带来了挑战,数据少的用户可能一下子算了很多epoc了,数据多的用户还早着。这一点上,联邦学习不像传统的分布式学习可以做负载均衡,即将一个节点的数据转移到另一个节点。
3. 联邦学习的分类
把每个参与共同建模的企业称为参与方,根据多参与方之间数据分布的不同,把联邦学习分为三类:横向联邦学习、纵向联邦学习与联邦迁移学习(工业界目前用的少)。
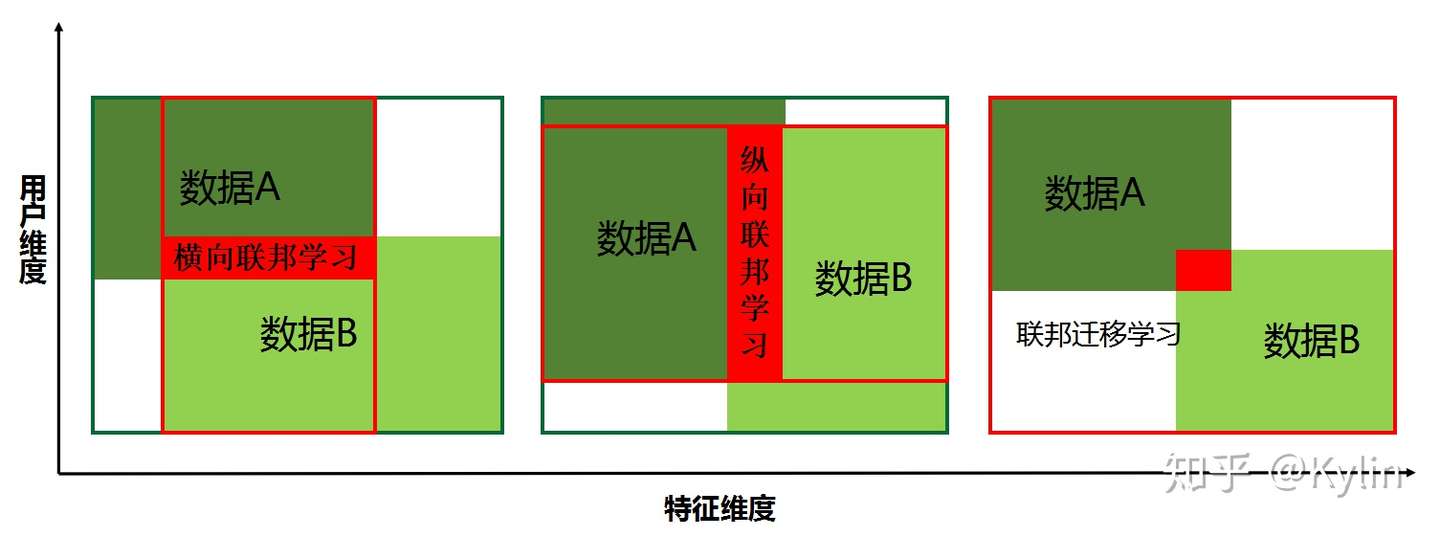
3.1. 横向联邦学习
谷歌最初采用横向联邦的方式解决安卓手机终端用户在本地更新模型的问题的。
- 本质是样本的联合。适用于参与者间业态相同但触达客户不同,即特征重叠多,用户重叠少时的场景,比如不同地区的银行间,业务相似(特征相似),用户不同(样本不同)。
- 学习过程
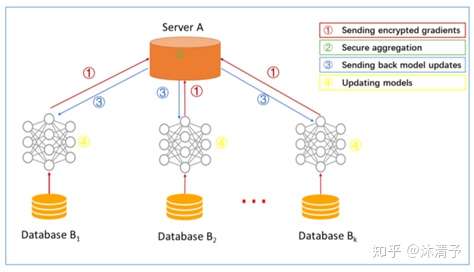
step 1:参与方在本地计算模型梯度,然后将梯度结果加密上传到服务器;
step 2:服务器 A 聚合各用户的梯度,更新模型参数;
step 3:服务器 A 返回更新后的模型给各参与方;
step 4:各参与方基于加密梯度更新各自模型。 - 步骤解读
- 传统机器学习建模时,通常把模型训练集数据集合到一个数据中心,然后再训练模型。
- 横向联邦学习中,可以看作是基于样本的分布式模型训练,分发全部数据到不同的机器,每台机器从服务器下载模型,然后利用本地数据训练模型,之后返回给服务器需要更新的参数;服务器聚合各机器上的返回的参数,更新模型,再把最新的模型反馈到每台机器。
- 整个过程中每台机器上都是相同且完整的模型,且机器之间不交流不依赖,在预测时每台机器也可以独立预测。
3.2. 纵向联邦学习
- 本质是特征的联合,适用于用户重叠多,特征重叠少的场景,比如同一地区的商超和银行,他们之间用户相同,但业务不同(特征)。
- 学习过程
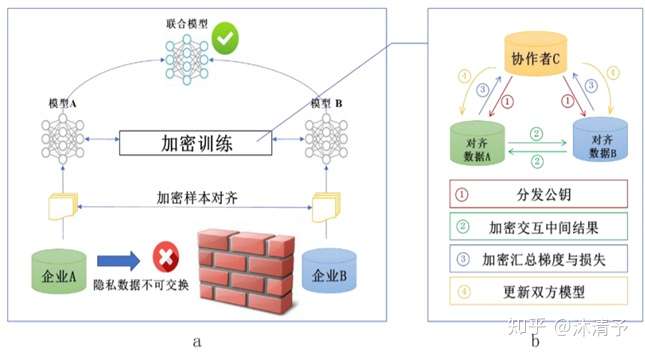
纵向联邦学习的本质是交叉用户在不同业态下的特征联合,比如商超A和银行B,在传统的机器学习建模过程中,需要将两部分数据集中到一个数据中心,然后再将每个用户的特征 join成一条数据用来训练模型,所以就需要双方有用户交集(基于join结果建模),并有一方存在label。
-
学习步骤
- 第三方 C 加密样本对齐。在系统级做这件事,因此在企业感知层面不会暴露非交叉用户。
- 对齐样本进行模型加密训练:
step1:由第三方C向A和B发送公钥,用来加密需要传输的数据;
step2:A和B分别计算和自己相关的特征中间结果,并加密交互,用来求得各自梯度和损失;
step3:A和B分别计算各自加密后的梯度并添加掩码发送给C,同时B计算加密后的损失发送给C;
step4:C解密梯度和损失后回传给A和B,A、B去除掩码并更新模型。
-
步骤解读


纵向联邦学习的具体训练步骤如下:
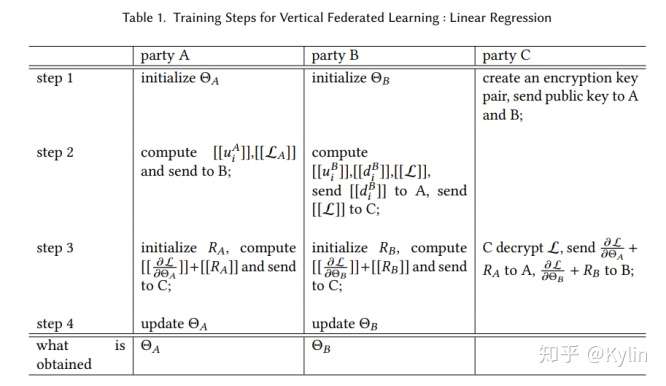

在整个过程中参与方都不知道另一方的数据和特征,且训练结束后参与方只得到自己侧的模型参数,即半模型。
- 预测过程:
由于各参与方只能得到与自己相关的模型参数,预测时需要双方协作完成,如下图所示:
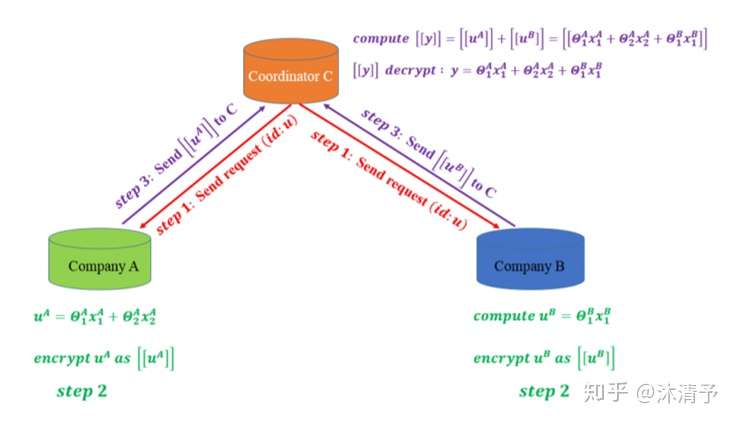
共同建模的结果:
- 双方均获得数据保护
- 共同提升模型效果
- 模型无损失
3.3. 联邦迁移学习
-
适用场景
当参与者特征和样本重叠都很少时可以考虑使用联邦迁移学习,如不同地区的商超和银行间的联合。 -
定义
- 迁移学习,是指利用数据、任务、或模型之间的相似性,将在源领域学习过的模型,应用于 目标领域的一种学习过程。
- 在两个数据集的用户与用户特征重叠都较少的情况下,我们不对数据进行切分,而可以利用迁移学习来客服数据或标签不足的情况。
迁移学习的核心是,找到源领域和目标领域之间的相似性,举一个杨强教授经常举的例子来说明:我们都知道在中国大陆开车时,驾驶员坐在左边,靠马路右侧行驶。这是基本的规则。然而,如果在英国、香港等地区开车,驾驶员是坐在右边,需要靠马路左侧行驶。那么,如果我们从中国大陆到了香港,应该如何快速地适应 他们的开车方式呢?诀窍就是找到这里的不变量:不论在哪个地区,驾驶员都是紧靠马路中间。这就是我们这个开车问题中的不变量。 找到相似性 (不变量),是进行迁移学习的核心。


- 训练过程和推理过程
联邦迁移学习的步骤与纵向联邦学习相似,只是中间传递结果不同(实际上每个模型的中间传递结果都不同)。


4. 联邦学习研究热点
4.1 Communication Efficiency
并行梯度下降中(parallel gradient descent),第 \({i}\) 个worker执行了任务:
- 从server接收模型参数 \({w}\)
- 根据 \({w}\) 和本地数据计算梯度 \({g_i}\)
- 将 \({g_i}\) 发送给server
然后 server 接收了所有用户的 \({g_i}\) 之后,执行任务:
- 接收 \({g_1}, {g_2},...,{g_m}\)
- 计算:\({g = \Sigma^m_{i=1}{g_i}}\)
- 做一次梯度下降,更新模型参数:\(w_{i+1} = w_{i} - \alpha \cdot g\)
- 然后将新的参数发送给用户,等待用户数据重复执行下一轮迭代
federated averaging algorithm 中,用更少的通信次数达到了收敛。
federated averaging algorithm 中, worker 执行任务:
- 从 server 接收参数 \(w\)
- 迭代一下过程:
a. 根据 \({w}\) 和本地数据计算梯度 \({g}\)
b. 本地化更新:\(w = w - \alpha \cdot g\)- 将 \(\widetilde{w}_{i}=w\) 传给 server
然后 server 接收了全部 \(\widetilde{w}\) 后,执行更新:
更新 \(w \leftarrow \frac{1}{m}\left(\widetilde{w}_{1}+\cdots+\widetilde{w}_{m}\right)\),下一轮迭代时将此 \(w\) 传给所有 server
- 其他结论:
- 相同次数的通信, Federated Averaging收敛的更快。两次通信之间 Federated Averaging 让worker 节点做大量计算,以牺牲计算量为代价换取更小的通信次数。
- 相同次数的epochs,梯度下降收敛的会更快。
- FedAvg 来作联邦学习,数据不需要独立同分布。
4.2 Privacy
联邦学习中,用户的数据始终没有离开用户,那么数据是否安全呢?
实际上算梯度的过程就是对数据的一个变换,将数据映射到梯度。

虽然数据没有发出去,但是梯度是几乎包含数据所有信息的,所以一定程度上,可以通过梯度反推出数据。如将梯度作为输入特征,然后学习一个分类器,其根本原理就是梯度带有用户信息。当前主流抵御这种攻击的办法往梯度加噪声,但这容易带来模型不准确,准确率降低等问题。
4.3 Adversarial Robustness
第三个研究热点让联邦学习可以抵御拜占庭错误和恶意攻击。简单说就是 worker 中出了叛徒,如何学到更好地模型。

- Attack 1 :将部分测试集数据进行修改,使这部分数据成为“毒药”;
- Attack 2 :将本地数据的标签换成错的,用正确的图片和错误的标签来计算梯度方向;
- Defense 1 :server 用某个 worker 传来的梯度来更新参数,再测试用了该参数的模型准确率;(效果一般)
- Defense 2:Server 比较各 worker 传过来的梯度,检验是否存在差异很大的梯度;假设了数据独立同分布,但实际上联邦学习场景的数据往往不是独立同分布的,效果一般。
- Defense 3: Server 对各 worker 传来的梯度加权平均,如中位数。同样假设了数据独立同分布。
Shusen Wang 结论:联邦学习目前没有良好的抵御方法。
5. 联邦学习的学习资料
-
联邦学习生态网站
-
开源项目
- FederatedAI / FATE :https://github.com/FederatedAI/FATE
- Eggroll WeBankFinTech/eggroll:https://github.com/WeBankFinTech/Eggroll
-
视频资料
-
Shusen Wang 《分布式机器学习》
-
并行计算与机器学习(1/3)(中文) Parallel Computing for Machine Learning (Part 1/3):并行计算基础以及MapReduce
这节课的主要内容:
0:28 Motivation:并行计算有什么用?为什么机器学习的人需要懂并行计算。
2:42 最小二乘回归(如果已经懂最小二乘,建议跳到 6:43 )。
6:43 用并行计算来解最小二乘回归。
11:14 并行计算中的通信问题。
13:10 MapReduce,已经如何用MapReduce实现并行梯度下降,以及通信、同步的问题 -
并行计算与机器学习(2/3)(中文) Parallel Computing for Machine Learning (Part 2/3):参数服务器、去中心化
这节课的主要内容:
1:02 Parameter Server(参数服务器),以及用Parameter Server实现异步梯度下降。
8:27 Decentralized Network(去中心化网络), 以及用Decentralized Network实现梯度下降。
15:39 Parallel Computing(并行计算)和Distributed Computing(分布式计算)的异同。 -
并行计算与机器学习(3/3)(中文) Parallel Computing for Machine Learning (Part 3/3):Ring All-Reduce
这节课的主要介绍TensorFlow中的并行计算库、以及其中Ring All-Reduce的原理。
这节课的主要内容:
1:09 如何应用TensorFlow的并行计算库训练神经网络
7:41 Ring All-Reduce的技术原理。 -
联邦学习:技术角度的讲解(中文)Introduction to Federated Learning
这节课的主要内容:
3:13 分布式机器学习
6:07 联邦学习和传统分布式学习的区别
12:46 联邦学习中的通信问题
15:24 Federated Averaging算法
21:24 联邦学习中的隐私泄露和隐私保护
27:52 联邦学习中的安全问题(拜占庭错误、data poisoning、model poisoning)
33:00 总结
-
-
Reference
[1] 联邦学习 Federated Learning: https://zhuanlan.zhihu.com/p/93761403
[2] 详解联邦学习Federated Learning:https://zhuanlan.zhihu.com/p/79284686
[3] 综述:《联邦学习:概念与应用》:https://zhuanlan.zhihu.com/p/127319831
[4] 分布式机器学习(下)-联邦学习:https://zhuanlan.zhihu.com/p/114028503
Shusen Wang "并行计算与分布式学习 "、"联邦学习:技术角度的讲解(中文)Introduction to Federated Learning" 系列视频。
