C++ STL 系列——无序容器(unordered_map、unordered_multimap、unordered_set、unordered_multiset)
一、什么是无序容器
无序容器是 C++ 11 标准正式引入到 STL 标准库中的,和关联式容器一样,无序容器也使用键值对的方式存储数据,不过关联式容器底层采用红黑树,无序容器底层采用哈希表。
C++ STL 底层采用哈希表实现无序容器时,会将所有数据存储到一整块连续的内存空间中,并且当数据存储位置发生冲突时,解决方法选用的是“链地址法”(又称“开链法”)。
无序容器特点:
- 无序容器内部存储的键值对是无序的,各键值对的存储位置取决于该键值对中的键
- 和关联式容器相比,无序容器擅长通过指定键查找对应的值(平均时间复杂度为 O(1));但对于使用迭代器遍历容器中存储的元素,无序容器的执行效率则不如关联式容器。
1.1 无序容器种类
| 无序容器 | 功能 |
|---|---|
| unordered_map | 存储键值对 <key, value> 类型的元素,其中各个键值对键的值不允许重复,且该容器中存储的键值对是无序的。 |
| unordered_multimap | 和 unordered_map 唯一的区别在于,该容器允许存储多个键相同的键值对。 |
| unordered_set | 不再以键值对的形式存储数据,而是直接存储数据元素本身(当然也可以理解为,该容器存储的全部都是键key 和值 value 相等的键值对,正因为它们相等,因此只存储 value 即可)。另外,该容器存储的元素不能重复,且容器内部存储的元素也是无序的。 |
| unordered_multiset | 和 unordered_set 唯一的区别在于,该容器允许存储值相同的元素。 |
与有序容器仅有一个区别,无序容器是不会对存储的键值对排序。实际场景中如果涉及大量遍历容器的操作,建议首选关联式容器;反之,如果更多的操作是通过键获取对应的值,则应首选无序容器。
1.2 自定义无序容器的哈希函数和比较规则
每种无序容器都指定了默认的 hash<key> 哈希函数和 equal_to<key> 比较规则,但它们仅适用于基本类型。
自定义哈希函数
哈希函数只是一个称谓,其本体并不是普通的函数形式,而是一个函数对象类。因此,如果我们想自定义个哈希函数,就需要自定义一个函数对象类。
class Person{
public:
Person(string name, int age):name(name),age(age){};
string getName() const;
int getAge() const;
private:
string name;
int age;
};
string Person::getName() const
return this->name;
int Person::getAge() const
return this->age;
如果需要创建一个可存储 Person 类对象的 unordered_set 容器,需要以函数对象类的方式自定义一个哈希函数:
class hash_fun(){
public:
int operator()(const Person &A) const
return A.getAge();
};
- 注意,重载 ( ) 运算符时,其参数必须为 const 类型,且该方法也必须用 const 修饰。
- 利用 hash_fun 函数对象类的 () 运算符重载方法,自定义了适用于 Person 类对象的哈希函数。该哈希函数每接收一个 Person 类对象,都会返回该对象的 age 成员变量的值。
std::unordered_set<Person, hash_fun> myset;
自定义比较规则
默认情况下无序容器使用的 std::equal_to<key> 比较规则,其本质也是一个函数对象类,底层实现如下:
template<class T>
class equal_to{
public:
bool operator()(const T& _Left, const T& _Right) const
return (_Left == _Right);
};
对于自定义的类型,实现自定义比较规则有两种方法:
- 在自定义类中重载
==运算符,这会使在自定义类的std::equal_to<key>中使用==运算符合法。- 以函数对象类的方式,自定义一个适用于 myset 容器的比较规则
重载 == 运算符
// 在 Person 类外部添加,重载 ==
bool operator==(const Person &A, const Person &B)
return (A.getAge() == B.getAge());
重载 == 运算符后,还是以默认的 std::equal_to<key> 函数作为比较规则
std::unordered_set<Person, hash_fun> myset{{"zhangsan", 40},{"zhangsan", 40},{"lisi", 40},{"lisi", 30}};
// 只会存储 {"zhangsan", 40} 和 {"lisi", 30}
以函数对象类的方式自定义比较规则
class mycmp{
public:
bool operator()(const Person &A, const Person &B) const
return ( A.getName() == B.getName()) && (A.getAge() == B.getAge());
};
// 创建 myset 容器
std::unordered_set<Person, hash_fun, mycmp> myset{ {"zhangsan", 40},{"zhangsan", 40},{"lisi", 40},{"lisi", 30} };
完整代码:
#include <iostream>
#include <string>
#include <unordered_set>
using namespace std;
class Person{
public:
Person(string name, int age):name(name), age(age){};
string getName() const;
int ageAge() const;
private:
string name;
int age;
};
string Person::getName() const
return this->name;
int Person::getAge() const
return this->age;
// 自定义哈希函数
class hash_fun{
public:
int operator()(const Person &A) const
return A.getAge();
};
// 重载 == 运算符,容器继续使用默认 equal_to<key> 规则
bool operator==(const Person &A, const Person &B)
return (A.getAge() == B.getAge());
// 完全自定义比较规则,弃用 equal_to<key>
class mycmp{
public:
bool operator()(const Person &A, const Person &B) const
return (A.getName() == B.getName()) && (A.getAge() == B.getAge());
};
int main(){
//使用自定义的 hash_fun 哈希函数,比较规则仍选择默认的 equal_to<key>,前提是必须重载 == 运算符
std::unordered_set<Person, hash_fun> myset1{ {"zhangsan", 40},{"zhangsan", 40},{"lisi", 40},{"lisi", 30} };
//使用自定义的 hash_fun 哈希函数,以及自定义的 mycmp 比较规则
std::unordered_set<Person, hash_fun, mycmp> myset2{ {"zhangsan", 40},{"zhangsan", 40},{"lisi", 40},{"lisi", 30} };
cout << "myset1:" << endl;
for (auto iter = myset1.begin(); iter != myset1.end(); ++iter)
cout << iter->getName() << " " << iter->getAge() << endl; // zhangsan 40 lisi 30
cout << "myset2:" << endl;
for (auto iter = myset2.begin(); iter != myset2.end(); ++iter)
cout << iter->getName() << " " << iter->getAge() << endl; // lisi 40 zhangsan 40 lisi 30
return 0;
}
1.3 容器选择
C++ STL 标准库(以 C++ 11 为准)提供了以下几种容器供我们选择:
- 序列式容器:array、vector、deque、list 和 forward_list;
- 关联式容器:map、multimap、set 和 multiset;
- 无序关联式容器:unordered_map、unordered_multimap、unordered_set 和 unordered_multiset;
- 容器适配器:stack、queue 和 priority_queue。
- 采用连续的存储空间:array、vector、deque(一段一段连续空间);
- 采用分散的存储空间:list、forward_list 以及所有的关联式容器和哈希容器。
选择容器需要考虑的一些因素:
| 因素 | 序列容器 | 关联容器 | 哈希容器 | 连续 | 分散 |
|---|---|---|---|---|---|
| 是否需要在容器的指定位置插入新元素? | 是 | ||||
| 是否对容器中各元素的存储位置有要求? | 否 | ||||
| 是否需要使用指定类型的迭代器?(随机访问/双向/前向) | |||||
| 当发生新元素的插入或删除操作时,是否要避免移动容器中的其它元素? | 是,避免 | ||||
| 容器中查找元素的效率是否为关键的考虑因素? | 是 |
二、unordered_map 容器
unordered_map 容器和 map 容器仅有一点不同,即 map 容器中存储的数据是有序的,而 unordered_map 容器中是无序的。
unordered_map 容器模板的定义:
template < class Key, // 键值对中键的类型
class T, // 键值对中值的类型
class Hash = hash<Key>, //容器内部存储键值对所用的哈希函数
class Pred = equal_to<Key>, // 判断各个键值对键相同的规则
class Alloc = allocator< pair<const Key,T> > // 指定分配器对象的类型
> class unordered_map;
| 参数 | 含义 |
|---|---|
| <key,T> | 前 2 个参数分别用于确定键值对中键和值的类型,也就是存储键值对的类型。 |
| Hash = hash |
用于指明容器在存储各个键值对时要使用的哈希函数,默认使用 STL 标准库提供的 hash |
| Pred = equal_to |
unordered_map 容器中存储的键不能相等,判断是否相等的规则,就由此参数指定。默认情况下,使用 STL 标准库中提供的 equal_to |
2.1 创建 unordered_map 容器
- 默认构造函数
std::unordered_map<std::string, std::string> umap; - 创建的同时初始化
std::unordered_map<std::string, std::string> umap{ {"Python 教程","http://c.biancheng.net/python/"}, {"Java 教程","http://c.biancheng.net/java/"}, {"Linux 教程","http://c.biancheng.net/linux/"} }; - 拷贝/移动构造函数
// 拷贝构造函数 std::unordered_map<std::string, std::string> umap2(umap); // 移动构造函数 // 返回临时 unordered_map 容器的函数 std::unordered_map <std::string, std::string > retUmap(){ std::unordered_map<std::string, std::string>tempUmap{ {"Python 教程","http://c.biancheng.net/python/"}, {"Java 教程","http://c.biancheng.net/java/"}, {"Linux 教程","http://c.biancheng.net/linux/"} }; return tempUmap; } // 调用移动构造函数,创建 umap2 容器 std::unordered_map<std::string, std::string> umap2(retUmap()); - 选择已有容器部分区域创建
//传入 2 个迭代器, std::unordered_map<std::string, std::string> umap2(++umap.begin(),umap.end());
2.2 成员方法
| 成员方法 | 功能 |
|---|---|
| begin() | 返回指向容器中第一个键值对的正向迭代器。 |
| end() | 返回指向容器中最后一个键值对之后位置的正向迭代器。 |
| cbegin() | 和 begin() 功能相同,只不过在其基础上增加了 const 属性,即该方法返回的迭代器不能用于修改容器内存储的键值对。 |
| cend() | 和 end() 功能相同,只不过在其基础上,增加了 const 属性,即该方法返回的迭代器不能用于修改容器内存储的键值对。 |
| empty() | 若容器为空,则返回 true;否则 false。 |
| size() | 返回当前容器中存有键值对的个数。 |
| max_size() | 返回容器所能容纳键值对的最大个数,不同的操作系统,其返回值亦不相同。 |
| operator[key] | 该模板类中重载了 [] 运算符,其功能是可以向访问数组中元素那样,只要给定某个键值对的键 key,就可以获取该键对应的值。注意,如果当前容器中没有以 key 为键的键值对,则其会使用该键向当前容器中插入一个新键值对。 |
| at(key) | 返回容器中存储的键 key 对应的值,如果 key 不存在,则会抛出 out_of_range 异常。 |
| find(key) | 查找以 key 为键的键值对,如果找到,则返回一个指向该键值对的正向迭代器;反之,则返回一个指向容器中最后一个键值对之后位置的迭代器(如果 end() 方法返回的迭代器)。 |
| count(key) | 在容器中查找以 key 键的键值对的个数。 |
| equal_range(key) | 返回一个 pair 对象,其包含 2 个迭代器,用于表明当前容器中键为 key 的键值对所在的范围。 |
| emplace() | 向容器中添加新键值对,效率比 insert() 方法高。 |
| emplace_hint() | 向容器中添加新键值对,效率比 insert() 方法高。 |
| insert() | 向容器中添加新键值对。 |
| erase() | 删除指定键值对。 |
| clear() | 清空容器,即删除容器中存储的所有键值对。 |
| swap() | 交换 2 个 unordered_map 容器存储的键值对,前提是必须保证这 2 个容器的类型完全相等。 |
| bucket_count() | 返回当前容器底层存储键值对时,使用桶(一个线性链表代表一个桶)的数量。 |
| max_bucket_count() | 返回当前系统中,unordered_map 容器底层最多可以使用多少桶。 |
| bucket_size(n) | 返回第 n 个桶中存储键值对的数量。 |
| bucket(key) | 返回以 key 为键的键值对所在桶的编号。 |
| load_factor() | 返回 unordered_map 容器中当前的负载因子。负载因子,指的是的当前容器中存储键值对的数量(size())和使用桶数(bucket_count())的比值,即 load_factor() = size() / bucket_count()。 |
| max_load_factor() | 返回或者设置当前 unordered_map 容器的负载因子。 |
| rehash(n) | 将当前容器底层使用桶的数量设置为 n。 |
| reserve() | 将存储桶的数量(也就是 bucket_count() 方法的返回值)设置为至少容纳 count 个元(不超过最大负载因子)所需的数量,并重新整理容器。 |
| hash_function() | 返回当前容器使用的哈希函数对象。 |
对于实现互换 2 个相同类型 unordered_map 容器的键值对,除了可以调用该容器模板类中提供的 swap() 成员方法外,STL 标准库还提供了同名的 swap() 非成员函数。
2.3 无序容器的底层实现机制
C++ STL 标准库中,不仅是 unordered_map 容器,所有无序容器的底层实现都采用的是哈希表存储结构。更准确地说,是用“链地 址法”(又称“开链法”)解决数据存储位置发生冲突的哈希表,整个存储结构如图所示。
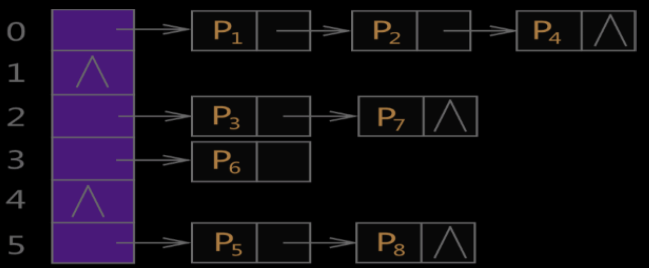
- 当使用无序容器存储键值对时,会先申请一整块连续的存储空间,但此空间并不用来直接存储键值对,而是存储各个链表的 头指针,各键值对真正的存储位置是各个链表的节点。
- STL 标准库通常选用 vector 容器存储各个链表的头指针。
当有新键值对存储到无序容器中时,整个存储过程分为好几步:
- 将该键值对中键的值带入设计好的哈希函数,会得到一个哈希值(一个整数,用 H 表示);
- 将 H 和无序容器拥有桶的数量 n 做整除运算(即 H % n),该结果即表示应将此键值对存储到的桶的编号;
- 建立一个新节点存储此键值对,同时将该节点链接到相应编号的桶上。
哈希表存储结构有一个重要的属性,称为负载因子(load factor)。该属性同样适用于无序容器,用于衡量容器 存储键值对的空/满程序,即负载因子越大,意味着容器越满,即各链表中挂载着越多的键值对,这无疑会降低容器查找目标键值对的效率;反之,负载因子越小,容器肯定越空,但并不一定各个链表中挂载的键值对就越少。
无序容器中,负载因子的计算方法为: 负载因子 = 容器存储的总键值对 / 桶数
默认情况下,无序容器的最大负载因子为 1.0。如果操作无序容器过程中,使得最大复杂因子超过了默认值,则容器会自动增加桶数, 并重新进行哈希,以此来减小负载因子的值。需要注意的是,此过程会导致容器迭代器失效,但指向单个键值对的引用或者指针仍然有效。
无序容器管理哈希表的成员方法
| 成员方法 | 功能 |
|---|---|
| bucket_count() | 返回当前容器底层存储键值对时,使用桶的数量。 |
| max_bucket_count() | 返回当前系统中,unordered_map 容器底层最多可以使用多少个桶。 |
| bucket_size(n) | 返回第 n 个桶中存储键值对的数量。 |
| bucket(key) | 返回以 key 为键的键值对所在桶的编号。 |
| load_factor() | 返回 unordered_map 容器中当前的负载因子。 |
| max_load_factor() | 返回或者设置当前 unordered_map 容器的最大负载因子。 |
| rehash(n) | 尝试重新调整桶的数量为等于或大于 n 的值。如果 n 大于当前容器使用的桶数,则该方法会是容器重新哈希, 该容器新的桶数将等于或大于 n。反之,如果 n 的值小于当前容器使用的桶数,则调用此方法可能没有任何作用。 |
| reserve(n) | 将容器使用的桶数(bucket_count() 方法的返回值)设置为最适合存储 n 个元素的桶数。 |
| hash_function() | 返回当前容器使用的哈希函数对象。 |
2.4 成员方法
| 成员方法 | 功能 |
|---|---|
| begin() | 返回指向容器中第一个键值对的正向迭代器。 |
| end() | 返回指向容器中最后一个键值对之后位置的正向迭代器。 |
| cbegin() | 和 begin() 功能相同,只不过在其基础上增加了 const 属性,即该方法返回的迭代器不能用于修改容器内存储的键值对。 |
| cend() | 和 end() 功能相同,只不过在其基础上,增加了 const 属性,即该方法返回的迭代器不能用于修改容器内存储的键值对。 |
| find(key) | 查找以 key 为键的键值对,如果找到,则返回一个指向该键值对的正向迭代器;反之,则返回一个指向容器中最后 一个键值对之后位置的迭代器(如果 end() 方法返回的迭代器)。 |
| equal_range(key) | 返回一个 pair 对象,其包含 2 个迭代器,用于表明当前容器中键为 key 的键值对所在的范围。 |
equal_range(key) 很少用,因为该容器中存储的键值都不相等
2.5 获取元素的 4 种方法
- [] 运算符,利用下标访问普通数组中元素,如果没有则添加
// 创建 umap 容器
unordered_map<string, string> umap{
{"Python 教程","http://c.biancheng.net/python/"},
{"Java 教程","http://c.biancheng.net/java/"},
{"Linux 教程","http://c.biancheng.net/linux/"} };
// 获取 "Java 教程" 对应的值
string str = umap["Java 教程"];
// 添加
umap["C 教程"] = "http://c.biancheng.net/c/";
- at() 成员方法,查找失败会报错
//创建 umap 容器
unordered_map<string, string> umap{
{"Python 教程","http://c.biancheng.net/python/"},
{"Java 教程","http://c.biancheng.net/java/"},
{"Linux 教程","http://c.biancheng.net/linux/"} };
//获取指定键对应的值
string str = umap.at("Python 教程");
- find() 成员方法。成功返回指向该键值对的迭代器,失败返回 end() 方法一致的迭代器,指向最后一个键值对之后位置。
unordered_map<string, string> umap{
{"Python 教程","http://c.biancheng.net/python/"},
{"Java 教程","http://c.biancheng.net/java/"},
{"Linux 教程","http://c.biancheng.net/linux/"} };
unordered_map<string, string>::iterator iter = umap.find("Python 教程");
unordered_map<string, string>::iterator iter2 = umap.find("GO 教程"); // 查找失败
if (iter2 == umap.end())
cout << "当前容器中没有以\"GO 教程\"为键的键值对";
- 通过 begin()/end() 或者 cbegin()/cend() 遍历
2.6 insert() 用法
insert() 方法可以向已建 unordered_map 容器中添加新的键值对。根据功能的不同,共有四种用法。
- 将 pair 类型键值对添加到容器中
// 以普通方式传递参数
pair<iterator,bool> insert ( const value_type& val );
// 以右值引用的方式传递参数
template <class P>
pair<iterator,bool> insert ( P&& val );
返回 pair 类型值,内部包含一个 iterator 迭代器和 bool 变量,添加成功 bool 为 True,添加失败 bool 为 False。
// 创建空 umap 容器
unordered_map<string, string> umap;
// 构建要添加的键值对
std::pair<string, string>mypair("STL 教程", "http://c.biancheng.net/stl/");
// 创建接收 insert() 方法返回值的 pair 类型变量
std::pair<unordered_map<string, string>::iterator, bool> ret;
// 调用 insert() 方法的第一种语法格式
ret = umap.insert(mypair);
// 调用 insert() 方法的第二种语法格式
ret = umap.insert(std::make_pair("Python 教程","http://c.biancheng.net/python/"));
- 指定新键值对要添加到容器中的位置
// 以普通方式传递 val 参数
iterator insert ( const_iterator hint, const value_type& val );
// 以右值引用方法传递 val 参数
template <class P>
iterator insert ( const_iterator hint, P&& val );
hint 参数为迭代器,用于指定新键值对要添加到容器中的位置;val 参数指的是要添加容器中的键值对;添加成功返回的迭代器指向新添加的键值对,失败返回的迭代器指向容器中已有相同的键值对。注意最终存储的位置实际上不取决于 hint 参数(hash)
// 创建空 umap 容器
unordered_map<string, string> umap;
// 构建要添加的键值对
std::pair<string, string>mypair("STL 教程", "http://c.biancheng.net/stl/");
// 创建接收 insert() 方法返回值的迭代器类型变量
unordered_map<string, string>::iterator iter;
// 调用第一种语法格式
iter = umap.insert(umap.begin(), mypair);
// 调用第二种语法格式
iter = umap.insert(umap.begin(),std::make_pair("Python 教程", "http://c.biancheng.net/python/"));
- 将某个 unordered_map 容器指定区域所有键值对复制到另一个 unordered_map 容器中
template <class InputIterator>
void insert ( InputIterator first, InputIterator last );
其中 first 和 last 都为迭代器,[first, last)表示复制其它 unordered_map 容器中键值对的区域。
// 创建并初始化 umap 容器
unordered_map<string, string> umap{
{"STL 教程","http://c.biancheng.net/stl/"},
{"Python 教程","http://c.biancheng.net/python/"},
{"Java 教程","http://c.biancheng.net/java/"} };
// 创建一个空的 unordered_map 容器
unordered_map<string, string> otherumap;
// 指定要拷贝 umap 容器中键值对的范围
unordered_map<string, string>::iterator first = ++umap.begin();
unordered_map<string, string>::iterator last = umap.end();
// 将指定 umap 容器中 [first,last) 区域内的键值对复制给 otherumap 容器
otherumap.insert(first, last);
- 一次想 unordered_map 容器添加多个键值对
void insert(initializer_list<value_type> il);
il 参数指可用于初始化列表的形式指定多个键值对元素
// 创建空的 umap 容器
unordered_map<string, string> umap;
umap.insert({ {"STL 教程","http://c.biancheng.net/stl/"},
{"Python 教程","http://c.biancheng.net/python/"},
{"Java 教程","http://c.biancheng.net/java/"} });
2.7 emplace() 和 emplace_hint() 方法
template <class... Args>
pair<iterator, bool> emplace ( Args&&... args );
参数 args 表示可直接向该方法传递创建新键值对所需要的 2 个元素的值,其中第一个元素将作为键值对的键,另一个作为键值对的值。
- 当 emplace() 成功添加新键值对时,返回的迭代器指向新添加的键值对,bool 值为 True;
- 当 emplace() 添加新键值对失败时,说明容器中本就包含一个键相等的键值对,此时返回的迭代器指向的就是容器中键相同的这个键值对,bool 值为 False。
// 创建 umap 容器
unordered_map<string, string> umap;
// 定义一个接受 emplace() 方法的 pair 类型变量
pair<unordered_map<string, string>::iterator, bool> ret;
// 调用 emplace() 方法
ret = umap.emplace("STL 教程", "http://c.biancheng.net/stl/");
emplace_hint() 方法的语法格式如下:
template <class... Args>
iterator emplace_hint ( const_iterator position, Args&&... args );
emplace_hint 不同之处:
- emplace_hint() 方法的返回值仅是一个迭代器,而不再是 pair 类型变量。当该方法将新键值对成功添加到容器中时,返回的迭代器指 向新添加的键值对;反之,如果添加失败,该迭代器指向的是容器中和要添加键值对键相同的那个键值对。
- emplace_hint() 方法还需要传递一个迭代器作为第一个参数,该迭代器表明将新键值对添加到容器中的位置。需要注意的是,新键值对添加到容器中的位置,并不是此迭代器说了算,最终仍取决于该键值对的键的值。该迭代器仅是建议。
// 创建 umap 容器
unordered_map<string, string> umap;
// 定义一个接受 emplace_hint() 方法的迭代器
unordered_map<string,string>::iterator iter;
// 调用 empalce_hint() 方法
iter = umap.emplace_hint(umap.begin(),"STL 教程", "http://c.biancheng.net/stl/");
2.8 删除元素 erase()/clear()
- erase():删除 unordered_map 容器中指定的键值对;
- clear():删除 unordered_map 容器中所有的键值对,即清空容器。
erase()
- 接受一个正向迭代器,并删除该迭代器指向的键值对
// 创建 umap 容器
unordered_map<string, string> umap{
{"STL 教程", "http://c.biancheng.net/stl/"},
{"Python 教程", "http://c.biancheng.net/python/"},
{"Java 教程", "http://c.biancheng.net/java/"} };
// 定义一个接收 erase() 方法的迭代器
unordered_map<string,string>::iterator ret;
// 删除容器中第一个键值对
ret = umap.erase(umap.begin());
返回一个指向被删除键值对之后位置的迭代器。
2. 根据键值对的键来删除键值对
size_type erase ( const key_type& k );
k 表示目标键值对的键的值;返回一个整数,表示成功删除的键值对的数量
// 创建 umap 容器
unordered_map<string, string> umap{
{"STL 教程", "http://c.biancheng.net/stl/"},
{"Python 教程", "http://c.biancheng.net/python/"},
{"Java 教程", "http://c.biancheng.net/java/"} };
int delNum = umap.erase("Python 教程"); // delNum 为 1
- 删除指定范围内的所有键值对
unordered_map<string, string> umap{
{"STL 教程", "http://c.biancheng.net/stl/"},
{"Python 教程", "http://c.biancheng.net/python/"},
{"Java 教程", "http://c.biancheng.net/java/"} };
unordered_map<string, string>::iterator first = umap.begin();
unordered_map<string, string>::iterator last = --umap.end();
// 删除[fist,last)范围内的键值对
auto ret = umap.erase(first, last); // 将仅剩最后一个键值对
clear()
一次性删除 unordered_map 容器中所有键值对
unordered_map<string, string> umap{
{"STL 教程", "http://c.biancheng.net/stl/"},
{"Python 教程", "http://c.biancheng.net/python/"},
{"Java 教程", "http://c.biancheng.net/java/"} };
umap.clear(); // umap 容器清空,umap.size() = 0
三、unordered_multimap 容器
和 unordered_map 容器一样,unordered_multimap 容器也以键值对的形式存储数据,且底层也采用哈希表结构存储各个键值对。 两者唯一的不同之处在于,unordered_multimap 容器可以存储多个键相等的键值对。
unordered_multimap 容器存储的所有键值对,键相等的键值对会被哈希到同一个桶中存储。
unordered_multimap 定义在 <unordered_map> 头文件中
#include <unordered_map>
using namespace std;
template < class Key, // 键(key)的类型
class T, // 值(value)的类型
class Hash = hash<Key>, // 底层存储键值对时采用的哈希函数
class Pred = equal_to<Key>, // 判断各个键值对的键相等的规则
class Alloc = allocator< pair<const Key,T> > // 指定分配器对象的类型
> class unordered_multimap;
| 参数 | 含义 |
|---|---|
| <key,T> | 前 2 个参数分别用于确定键值对中键和值的类型,也就是存储键值对的类型。 |
| Hash = hash |
用于指明容器在存储各个键值对时要使用的哈希函数,默认使用 STL 标准库提供的 hash |
| Pred = equal_to |
unordered_multimap 容器可以存储多个键相等的键值对,而判断是否相等的规则,由此参数指定。默认情况下,使用 STL 标准库中提供的 equal_to |
当 unordered_multimap 容器中存储键值对的键为自定义类型时,默认的哈希函数 hash
以及比较函数 equal_to 将不再适用,这种情况下,需要我们自定义适用的哈希函数和比较函数,并分别显式传递给 Hash 参数和 Pred 参数。
3.1 创建 unordered_multimap 容器的方法
- 默认构造函数
std::unordered_multimap<std::string, std::string> myummap;
- 创建同时完成初始化
unordered_multimap<string, string>myummap{
{"Python 教程","http://c.biancheng.net/python/"},
{"Java 教程","http://c.biancheng.net/java/"},
{"Linux 教程","http://c.biancheng.net/linux/"} };
- 拷贝/移动构造函数
unordered_multimap<string, string> myummap2(myummap);
// 返回临时 unordered_multimap 容器的函数
std::unordered_multimap <std::string, std::string > retUmmap() {
std::unordered_multimap<std::string, std::string>tempummap{
{"Python 教程","http://c.biancheng.net/python/"},
{"Java 教程","http://c.biancheng.net/java/"},
{"Linux 教程","http://c.biancheng.net/linux/"} };
return tempummap
}
// 创建并初始化 myummap 容器
std::unordered_multimap<std::string, std::string> myummap(retummap());
- 根据已有 unordered_map 容器部分区域新建 unordered_multimap 容器
// 传入 2 个迭代器
std::unordered_multimap<std::string, std::string> myummap2(++myummap.begin(), myummap.end());
3.2 成员方法
| 成员方法 | 功能 |
|---|---|
| begin() | 返回指向容器中第一个键值对的正向迭代器。 |
| end() | 返回指向容器中最后一个键值对之后位置的正向迭代器。 |
| cbegin() | 和 begin() 功能相同,只不过在其基础上增加了 const 属性,即该方法返回的迭代器不能用于修改容器内存储的键值对。 |
| cend() | 和 end() 功能相同,只不过在其基础上,增加了 const 属性,即该方法返回的迭代器不能用于修改容器内存储的键值对。 |
| empty() | 若容器为空,则返回 true;否则 false。 |
| size() | 返回当前容器中存有键值对的个数。 |
| max_size() | 返回容器所能容纳键值对的最大个数,不同的操作系统,其返回值亦不相同。 |
| find(key) | 查找以 key 为键的键值对,如果找到,则返回一个指向该键值对的正向迭代器;反之,则返回一个指向容器中 最后一个键值对之后位置的迭代器(如果 end() 方法返回的迭代器)。 |
| count(key) | 在容器中查找以 key 键的键值对的个数。 |
| equal_range(key) | 返回一个 pair 对象,其包含 2 个迭代器,用于表明当前容器中键为 key 的键值对所在的范围。 |
| emplace() | 向容器中添加新键值对,效率比 insert() 方法高。 |
| emplace_hint() | 向容器中添加新键值对,效率比 insert() 方法高。 |
| insert() | 向容器中添加新键值对。 |
| erase() | 删除指定键值对。 |
| clear() | 清空容器,即删除容器中存储的所有键值对。 |
| swap() | 交换 2 个 unordered_multimap 容器存储的键值对,前提是必须保证这 2 个容器的类型完全相等。 |
| bucket_count() | 返回当前容器底层存储键值对时,使用桶(一个线性链表代表一个桶)的数量。 |
| max_bucket_count() | 返回当前系统中,unordered_multimap 容器底层最多可以使用多少桶。 |
| bucket_size(n) | 返回第 n 个桶中存储键值对的数量。 |
| bucket(key) | 返回以 key 为键的键值对所在桶的编号。 |
| load_factor() | 返回 unordered_multimap 容器中当前的负载因子。负载因子,指的是的当前容器中存储键值对的数量 (size())和使用桶数(bucket_count())的比值,即 load_factor() = size() / bucket_count()。 |
| max_load_factor() | 返回或者设置当前 unordered_multimap 容器的负载因子。 |
| rehash(n) | 将当前容器底层使用桶的数量设置为 n。 |
| reserve() | 将存储桶的数量(也就是 bucket_count() 方法的返回值)设置为至少容纳 count 个元(不超过最大负载因子) 所需的数量,并重新整理容器。 |
| hash_function() | 返回当前容器使用的哈希函数对象。 |
四、unordered_set 容器
unordered_set 容器和 set 容器很像,唯一的区别就在于 set 容器会自行对存 储的数据进行排序,而 unordered_set 容器不会。
unordered_set 容器具有以下几个特性:
- 不再以键值对的形式存储数据,而是直接存储数据的值;
- 容器内部存储的各个元素的值都互不相等,且不能被修改。
- 不会对内部存储的数据进行排序;
#include <unordered_set>
using namespace std;
// 类模板定义
template < class Key, // 容器中存储元素的类型
class Hash = hash<Key>, // 确定元素存储位置所用的哈希函数
class Pred = equal_to<Key>, // 判断各个元素是否相等所用的函数
class Alloc = allocator<Key> // 指定分配器对象的类型
> class unordered_set;
| 参数 | 含义 |
|---|---|
| Key | 确定容器存储元素的类型,如果读者将 unordered_set 看做是存储键和值相同的键值对的容器,则此参数则用于 确定各个键值对的键和值的类型,因为它们是完全相同的,因此一定是同一数据类型的数据。 |
| Hash = hash |
指定 unordered_set 容器底层存储各个元素时,所使用的哈希函数。需要注意的是,默认哈希函数 hash |
| Pred = equal_to |
unordered_set 容器内部不能存储相等的元素,而衡量 2 个元素是否相等的标准,取决于该参数指定的函数。 默 认情况下,使用 STL 标准库中提供的 equal_to |
4.1 创建 unordered_set 容器
- 默认构造函数
std::unordered_set<std::string> uset;
- 创建时初始化
std::unordered_set<std::string> uset{ "http://c.biancheng.net/c/",
"http://c.biancheng.net/java/",
"http://c.biancheng.net/linux/" };
- 拷贝/移动构造函数
// 拷贝构造函数
std::unordered_set<std::string> uset2(uset);
// 移动构造函数
// 返回临时 unordered_set 容器的函数
std::unordered_set <std::string> retuset() {
std::unordered_set<std::string> tempuset{ "http://c.biancheng.net/c/",
"http://c.biancheng.net/java/",
"http://c.biancheng.net/linux/" };
return tempuset;
}
std::unordered_set<std::string> uset(retuset());
- 通过已有 unordered_set 部分区域新建
std::unordered_set<std::string> uset2(++uset.begin(), uset.end());
4.2 成员方法
| 成员方法 | 功能 |
|---|---|
| begin() | 返回指向容器中第一个元素的正向迭代器。 |
| end() | 返回指向容器中最后一个元素之后位置的正向迭代器。 |
| cbegin() | 和 begin() 功能相同,只不过其返回的是 const 类型的正向迭代器。 |
| cend() | 和 end() 功能相同,只不过其返回的是 const 类型的正向迭代器。 |
| empty() | 若容器为空,则返回 true;否则 false。 |
| size() | 返回当前容器中存有元素的个数。 |
| max_size() | 返回容器所能容纳元素的最大个数,不同的操作系统,其返回值亦不相同。 |
| find(key) | 查找以值为 key 的元素,如果找到,则返回一个指向该元素的正向迭代器;反之,则返回一个指向容器中最后 一个元素之后位置的迭代器(如果 end() 方法返回的迭代器)。 |
| count(key) | 在容器中查找值为 key 的元素的个数。 |
| equal_range(key) | 返回一个 pair 对象,其包含 2 个迭代器,用于表明当前容器中值为 key 的元素所在的范围。 |
| emplace() | 向容器中添加新元素,效率比 insert() 方法高。 |
| emplace_hint() | 向容器中添加新元素,效率比 insert() 方法高。 |
| insert() | 向容器中添加新元素。 |
| erase() | 删除指定元素。 |
| clear() | 清空容器,即删除容器中存储的所有元素。 |
| swap() | 交换 2 个 unordered_map 容器存储的元素,前提是必须保证这 2 个容器的类型完全相等。 |
| bucket_count() | 返回当前容器底层存储元素时,使用桶(一个线性链表代表一个桶)的数量。 |
| max_bucket_count() | 返回当前系统中,unordered_map 容器底层最多可以使用多少桶。 |
| bucket_size(n) | 返回第 n 个桶中存储元素的数量。 |
| bucket(key) | 返回值为 key 的元素所在桶的编号。 |
| load_factor() | 返回 unordered_map 容器中当前的负载因子。负载因子,指的是的当前容器中存储元素的数量(size())和使 用桶数(bucket_count())的比值,即 load_factor() = size() / bucket_count()。 |
| max_load_factor() | 返回或者设置当前 unordered_map 容器的负载因子。 |
| rehash(n) | 将当前容器底层使用桶的数量设置为 n。 |
| reserve() | 将存储桶的数量(也就是 bucket_count() 方法的返回值)设置为至少容纳 count 个元(不超过最大负载因子) 所需的数量,并重新整理容器。 |
| hash_function() | 返回当前容器使用的哈希函数对象。 |
五、unordered_multiset 容器
- unordered_multiset 不以键值对的形式存储数据,而是直接存储数据的值;
- 该类型容器底层采用的也是哈希表存储结构,它不会对内部存储的数 据进行排序;
- unordered_multiset 容器内部存储的元素,其值不能被修改。
- 和 unordered_set 容器不同的是,unordered_multiset 容器可以同时存储多个值相同的元素,且这些元素会存储到哈希表中同一个桶 (本质就是链表)上。
#include <unordered_set>
using namespace std;
// unordered_multiset 容器类模板定义
template < class Key, // 容器中存储元素的类型
class Hash = hash<Key>, // 确定元素存储位置所用的哈希函数
class Pred = equal_to<Key>, // 判断各个元素是否相等所用的函数
class Alloc = allocator<Key> // 指定分配器对象的类型
> class unordered_multiset;
| 参数 | 含义 |
|---|---|
| Key | 确定容器存储元素的类型,如果读者将 unordered_multiset 看做是存储键和值相同的键值对的容器,则此参数 则用于确定各个键值对的键和值的类型,因为它们是完全相同的,因此一定是同一数据类型的数据。 |
| Hash = hash |
指定 unordered_multiset 容器底层存储各个元素时所使用的哈希函数。需要注意的是,默认哈希函数 hash |
| Pred = equal_to |
用于指定 unordered_multiset 容器判断元素值相等的规则。默认情况下,使用 STL 标准库中提供的equal_to |
5.1 创建 unordered_multiset 容器
- 构造函数
std::unordered_multiset<std::string> umset;
- 创建容器同时初始化
std::unordered_multiset<std::string> umset{ "http://c.biancheng.net/c/",
"http://c.biancheng.net/java/",
"http://c.biancheng.net/linux/" };
- 拷贝/移动构造函数
// 拷贝构造函数
std::unordered_multiset<std::string> umset2(umset);
// 移动构造函数
// 返回临时 unordered_multiset 容器的函数
std::unordered_multiset <std::string> retumset() {
std::unordered_multiset<std::string> tempumset{
"http://c.biancheng.net/c/",
"http://c.biancheng.net/java/",
"http://c.biancheng.net/linux/" };
return tempumset;
}
// 调用移动构造函数
std::unordered_multiset<std::string> umset(retumset());
- 根据已有 unordered_multiset 容器部分区域新建
std::unordered_multiset<std::string> umset2(++umset.begin(), umset.end());
5.2 成员方法
| 成员方法 | 功能 |
|---|---|
| begin() | 返回指向容器中第一个元素的正向迭代器。 |
| end() | 返回指向容器中最后一个元素之后位置的正向迭代器。 |
| cbegin() | 和 begin() 功能相同,只不过其返回的是 const 类型的正向迭代器。 |
| cend() | 和 end() 功能相同,只不过其返回的是 const 类型的正向迭代器。 |
| empty() | 若容器为空,则返回 true;否则 false。 |
| size() | 返回当前容器中存有元素的个数。 |
| max_size() | 返回容器所能容纳元素的最大个数,不同的操作系统,其返回值亦不相同。 |
| find(key) | 查找以值为 key 的元素,如果找到,则返回一个指向该元素的正向迭代器;反之,则返回一个指向容器中最后 一个元素之后位置的迭代器(如果 end() 方法返回的迭代器)。 |
| count(key) | 在容器中查找值为 key 的元素的个数。 |
| equal_range(key) | 返回一个 pair 对象,其包含 2 个迭代器,用于表明当前容器中值为 key 的元素所在的范围。 |
| emplace() | 向容器中添加新元素,效率比 insert() 方法高。 |
| emplace_hint() | 向容器中添加新元素,效率比 insert() 方法高。 |
| insert() | 向容器中添加新元素。 |
| erase() | 删除指定元素。 |
| clear() | 清空容器,即删除容器中存储的所有元素。 |
| swap() | 交换 2 个 unordered_multimap 容器存储的元素,前提是必须保证这 2 个容器的类型完全相等。 |
| bucket_count() | 返回当前容器底层存储元素时,使用桶(一个线性链表代表一个桶)的数量。 |
| max_bucket_count() | 返回当前系统中,容器底层最多可以使用多少桶。 |
| bucket_size(n) | 返回第 n 个桶中存储元素的数量。 |
| bucket(key) | 返回值为 key 的元素所在桶的编号。 |
| load_factor() | 返回容器当前的负载因子。所谓负载因子,指的是的当前容器中存储元素的数量(size())和使用桶数 (bucket_count())的比值,即 load_factor() = size() / bucket_count()。 |
| max_load_factor() | 返回或者设置当前 unordered_map 容器的负载因子。 |
| rehash(n) | 将当前容器底层使用桶的数量设置为 n。 |
| reserve() | 将存储桶的数量(也就是 bucket_count() 方法的返回值)设置为至少容纳 count 个元(不超过最大负载因子) 所需的数量,并重新整理容器。 |
| hash_function() | 返回当前容器使用的哈希函数对象。 |
