structured streaming

https://dzone.com/articles/spark-streaming-vs-structured-streaming 比较spark streaming 和structured streaming
1。微批处理模式

日志操作保证一致性 带来微小延迟 100ms
2。持续处理模式
毫秒级延迟 异步写日志
structured streaming 程序
#!/usr/bin/env python3 # -*- coding: utf-8 -*- from pyspark.sql import SparkSession from pyspark.sql.functions import split from pyspark.sql.functions import explode if __name__=="__main__": spark=SparkSession.builder.appName("StructuredNetworkWordCount").getOrCreate() #getOrcreate : get a sparksession object, if current process has one, then use that ,if there is not, then is there a gloval sparksession, if not ,then create one. spark.sparkContext.setLogLevel("WARN") #get rid of info lines=spark.readStream.format("socket")\ .option("host","localhost")\ .option("port",9999)\ .load() words=lines.select( explode( split(lines.value,"") ).alias("word") ) wordCounts=words.groupBy("word").count() query = wordCounts.writeStream.outputMode("complete")\ .format("console")\ .trigger(processingTime="8 seconds")\ .start() query.awaitTermination()
spark-submit --master local StructuredNetworkWordCount.py yarn模式需要多台机器 所以用local模式运行
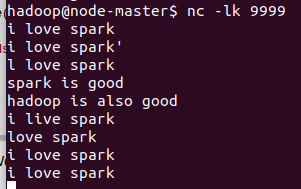

但是只能运行10s内 他的结果
File源

structuredStreamingFileSourceGenerator.py
import os import shutil import random import time TEST_DATA_TEMP_DIR = '/tmp/' #创建一个文件夹在tmp下 TEST_DATA_DIR='/tmp/testdata' ACTION_DEF=['login','logout','purchase'] #三种状态 DISTRICT_DEF=['fujian','beijing','shanghai','guangzhou'] JSON_LINE_PATTERN='{{"eventTime":{},"action":"{}","district":"{}"}}\n' #转义字符 escape character #testing, to judge whether the folder exist. if so delete old data, and build now folder #判断文件是否存在,存在删除老数据
def test_setUp(): if os.path.exists(TEST_DATA_DIR): shutil.rmtree(TEST_DATA_DIR,ignore_errors=True) os.mkdir(TEST_DATA_DIR) def test_tearDown(): if os.path.exists(TEST_DATA_DIR): shutil.rmtree(TEST_DATA_DIR,ignore_errors=True) #实验做完了把文件删掉 #generate testing file def write_and_move(filename,data): with open(TEST_DATA_TEMP_DIR+filename,"wt",encoding="utf-8") as f: #创建好临时文件,移动到文件夹 f.write(data) #wt代表文档,with open会自动关闭文件释放内存 shutil.move(TEST_DATA_TEMP_DIR + filename,TEST_DATA_DIR+filename) if __name__ == "__main__": test_setUp() for i in range(1000): filename='e-mail-{}.json'.format(i) #.format插入数据 content='' rndcount=list(range(100)) random.shuffle(rndcount) for _ in rndcount: content += JSON_LINE_PATTERN.format(str(int(time.time())),\ random.choice(ACTION_DEF), random.choice(DISTRICT_DEF)) write_and_move(filename,content) time.sleep(1) #生成1000个文件,每个有100行数据 test_tearDown()
第二步 创建程序对数据进行统计
structuredStreamingFileCount.py
# -*- coding: UTF-8 -*- import os import shutil from pprint import pprint from pyspark.sql import SparkSession from pyspark.sql.functions import window,asc from pyspark.sql.types import StructType,StructField from pyspark.sql.types import TimestampType,StringType #define JSON file location as constant TEST_DATA_DIR_SPARK='file:///tmp/testdata/' if __name__ == "__main__": schema=StructType([StructField("eventTime",TimestampType(),True),\ StructField("action",StringType(),True),\ StructField("district",StringType(),True)]) spark=SparkSession\ .builder\ .appName("StructuredPurchaseCount")\ .getOrCreate() spark.sparkContext.setLogLevel("WARN") #设置流计算过程 lines=spark.readStream\ .format("json")\ .schema(schema)\ .option("maxFilesPerTrigger",100)\ .load(TEST_DATA_DIR_SPARK) #定义窗口 windowDuration = '1 minutes' windowedCounts=lines.filter("action='purchase'")\ #只想统计购买人的数量 .groupBy('district',window('eventTime',windowDuration))\ #对这些人根据地区进行分组统计 窗口统计,时间间隔1分钟 .count()\ .sort(asc('window')) #根据窗口进行排序 #启动流计算 query=windowedCounts\ .writeStream\ .outputMode("complete")\ .format("console")\ .option('truncate','false')\ .trigger(processingTime="10 seconds")\ .start() query.awaitTermination()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号