spark厦门大学
Spark:基于内存的计算框架


spark生态系统

spark基本架构:
RDD: Resilient Distributed Dataset(弹性分布式数据集)
数据可大可小 弹性分配分区 分布式在内存中
DAG:Directed Acyclic Graph(有向无环图)
Executor 进程(process)和线程(thread)的区别 Process means any program is in execution process 里有好几个thread(状态:running,ready,blocked)
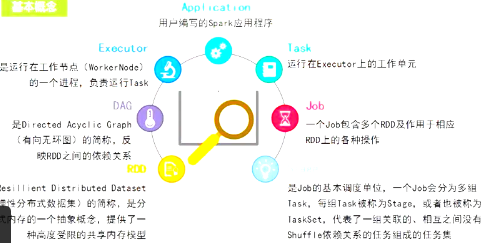

Cluster Manager可以是yarn
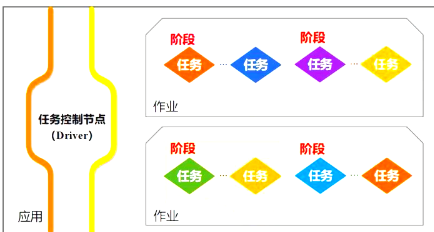
spark运行基本流程:
driver主节点运行 sparkcontest对象(负责所有)
sparkcontest-》请求资源yarn-》分配资源-》启动Executor进程
分配任务: sparkcontest 根据RDD依赖关系生成 DAG图-》交给DAG Scheduler-》解析DAG成为Stage(包含许多任务)-》Task Sduler《--Worker Node申运行
Task Scheduler负责分配任务 计算向数据靠拢原则(在数据所在计算机运行)
任务返回: Worker Node-》Task scheduler-》DAG Scheduler-》sparkcontext
RDD运行原理

序列化serialization- Object(例:java对象)-》可保存和传输的格式(二进制、字符串)
反序列化deserialization-》还原成对象
RDD 为了解决这个 RDD提供抽象结构 转换处理 不同RDD转换有依赖关系,形成DAG
DAG可以进行优化 实现数据管道(流水线化处理)数据在内存
RDD--分布式对象的集合 本质上市只读的分区记录集合(高度受限的共享内存模型)
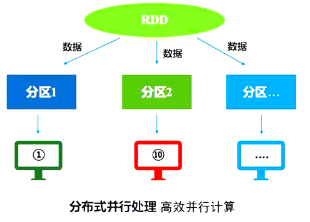
数据分布式 计算也可以并行
RDD 只有转化过程中可以修改 通过生成一个新的RDD来修改数据
RDD两大类型操作:
Action(动作类型),Transformation(转换类型)--粗粒度coarse grained修改(一次只能针对RDD全集转换)
Spark不支持细粒度修改(fine grained)如网页爬虫
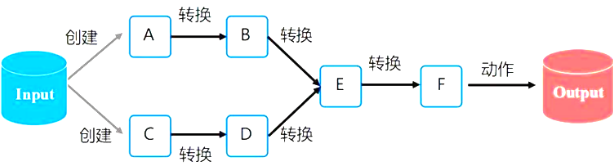
惰性机制:转换只记录轨迹,只有action触发计算(应该是由于之后系统可以对之进行优化)
为何spark高效:天然容错性 lineage各个步骤血缘关系 错误或丢失 可重新生成
作业到阶段的过程
发生shuffle操作就是宽依赖 否则就是窄依赖
宽依赖(Wide or shffle Dependencies)和窄依赖(Narrow Dependencies)
窄依赖:一个父RDD分区对应一个子RDD分区 或者多个父RDD 对应一个子RDD
宽依赖:一个父RDD分区对应多个子RDD分区
这两个就是阶段划分依据 宽:划分成多个阶段(不能流水线优化)窄:可以
fork&join

ref:https://www.cnblogs.com/jesse123/p/11423243.html
问题 1.如果如此 即使shuffle分阶段运行 shuffle结果记录在磁盘上 那不是在action之前就进行了计算?
2. 可以一个父亲对应两个儿子 不产生shuffle操作吗?
pyspark中运行代码:
pyspark --master <master-url>


yarn-client 指挥所在所登陆电脑中(调试)
cluster 建在集群中某台电脑上 客户端可以关机(上线发布)
yarn 默认 yarn-client
Spark 2.0分布式集群环境搭建
http://dblab.xmu.edu.cn/blog/1187-2/
start hadoop
spark start-master
start-slaves
启动后查看

http://192.168.56.2:8080/
启动spark后把hadoop替换了

spark-submit --master local[2] /usr/local/spark/examples/src/main/python/pi.py
单节点
spark-submit --master spark://node-master:7077 /usr/local/spark/examples/src/main/python/ml/pca_example.py
15s
spark-submit --master spark://node-master:7077 --deploy-mode client /usr/local/spark/examples/src/main/python/ml/pca_example.py
17s
yarn:
spark-submit --master yarn /usr/local/spark/examples/src/main/python/ml/pca_example.py
不成功 原因估计是单节点
双节点
yarn:
spark-submit --master yarn /usr/local/spark/examples/src/main/python/ml/pca_example.py
28s
standalone:
spark-submit --master spark://node-master:7077 /usr/local/spark/examples/src/main/python/ml/pca_example.py
25s
在8088 hadoop FINISHED端口看log
RDD编程
spark架构

创建RDD
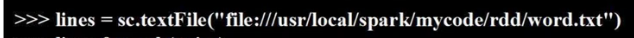
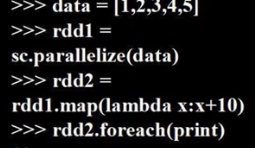
并行化集合创建RDD


完全一样
from pyspark import SparkConf, SparkContext # Init. conf = SparkConf().setMaster("local").setAppName("My App") sc = SparkContext(conf = conf) logFile = "file:///usr/local/spark/README.md" # Load. logData = sc.textFile(logFile, 2).cache() # RDD. numAs = logData.filter(lambda line: 'a' in line).count() numBs = logData.filter(lambda line: 'b' in line).count() print('Lines with a: %s, Lines with b: %s' % (numAs, numBs))
spark-submit WordCount.py成功
关闭调试信息,可以改为 INFO --> ERROR
hadoop@node-master$ find spark/ -name "*" | xargs grep "log4j.rootCategory=" spark/conf/log4j.properties.template:log4j.rootCategory=INFO, console
或者
spark-submit ./spark/examples/src/main/python/pi.py 2>&1 | grep "Pi is roughly"
RDD转换
filter函数
map函数同时对所有的进行操作

flatMap
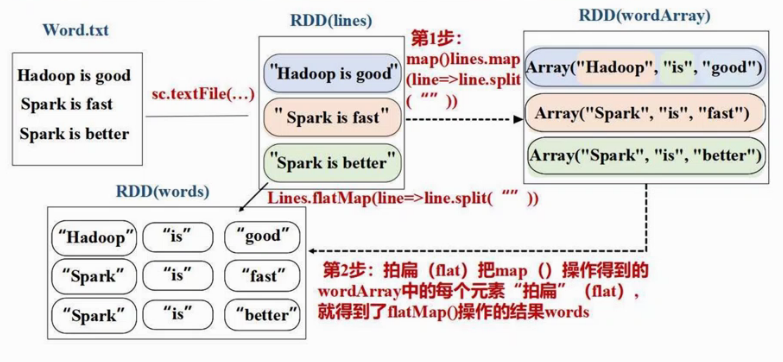


Reducedbykey (group by key后进行计算)

“is” <1,1,1> a:left 1 b:right 1, 1+1; a:left2 b:right 1, 2+1
RDD Action


持久化:


unpersist手动移除
RDD分区作用:
增加并行度,RDD保存在不同节点上
减少通信开销



分区方式:
HashPartitioner哈希分区
RangePartitioner区域分区
自定义分区:
例:


partitionBy只接受键值对输入, 取分好区的地一个元素
取分好区的地一个元素
写出10个文件

RDD key,value pair创建
1。使用map函数

2。并行集合或列表

常用键值对RDD操作
1。reduceByKey

2。groupByKey
(“spark”,1)
(“spark”,2) =》(“spark”,1,2)
list={("spark",1),("spark",2),("hadoop",3),("hadoop",5)}
RDD=sc.parallelize(list)
RDD.groupByKey().foreach(print)
('hadoop',<pyspark.resultiterable.ResultIterable object at 0x7f2e1093ecf8>)
......

3.keys
把pair RDD中的key返回形成新的RDD

4。values
同理

5。sortByKey()
返回一个根据键排序的RDD
6。sortBy()

7。mapValues()
对RDD每个value应用一个函数,key不会变

8。join()


实例:
key即图书,value即销量,计算每种图书每天平均销量
rdd=sc.parallelize([("spark",2),("hadoop",6),("hadoop,4"),("spark",6)])
rdd.mapValues(lambda x:(x,1)).\
reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1])).\
mapValues(lambda x:x[0]/x[1]).collect()
[('hadoop',5.0),('spark',4.0)]
文件数据读写:
直到执行之前,都只记录

写入的是一个目录,因为可能会生成多个文件
载入是一个目录:
textFile=sc.textFile("file:///usr/local/spark/writeback")
分布式文件系统读写:

保存:

读写HBase数据
hbase 4维定位 行键,列族,列限定符,版本时间戳 Row Key, Column Family, Column Qualifier,Version

 浙公网安备 33010602011771号
浙公网安备 33010602011771号