
Oracle之增、删、改、查
结构化查询语言 (Structured Query Language, SQL)
SQL的组成:
-
数据操作语言(DML)
对数据进行查询、插入、删除和修改等操作,例如SELECT、INSERT、UPDATE、DELETE等。
- 查询语言(QL)
也可以将对数据的查询操作称为查询语言。按照指定的组合、条件表达式或排序检索已存在的数据库中数据,不改变数据库中数据。例如SELECT…FROM…WHERE…
-
数据控制语言(DCL)
用来授予或收回访问数据库的某种特权;用来控制存取许可、存取权限等。例如GRANT、REVOKE等。
-
数据定义语言(DDL)
用来创建、修改或删除数据库中各种对象,包括表、视图、索引等。例如CREATE TABLE、DROP TALBE等。
-
事务控制语言(TCL)
事务控制语言也可以归为数据控制语言。用于控制数据操纵事务的发生时间及效果、对数据库进行监视。例如COMMIT、SAVEPOINT、ROLLBACK等。
1、插入数据
命令格式:insert into <表明> (列名) values (字段值)
insert into Student(Sid,Sname,Sgender,Scid) values(1,'张三','男',1); -- 列名可省略 insert into Student values(2,'李四','女',2);
-
- insert into <表名> (列名) select <列名> from <源表名>
--将数据表Student中指定列的数据插入到数据表TongXueLu中指定的列 insert into TongXueLu(Tid,Tname,Taddress,Tmail) select Sid,Sname,Saddress,Smail from Student;
-
- insert into <表名> (列名) select <列名> from dual UNION
select <列名> from dual UNION
... ...
insert into Student (Sid,Sname,Smail) select 1,'张三','123' from dual union select 2,'李四','456' from dual union select 3,'王五','789' from dual union select 4,'赵六','aaa' from dual union
... ...
2、删除数据
命令格式:delete from <表名> [where <删除条件>]
-- 删除数据表Student中的所有数据 delete from Student; -- 删除数据表Student中字段SGender的值为‘男’的数据 delete from Student where SGender='男';
--删除数据表Student中字段SID的值大于4,并且字段SGender的值为‘男’的数据
delete from Student where SID>4 and SGender='男';
3、修改数据
命令格式:update <表名> set <列名=更新值> [where <更新条件>]
--将数据表Student中所有数据行SGender列的值修改为‘男’,SAddress列的值修改为‘CH’ update Student set SGender='男',SAddress='CH';
--将数据表Student中SAddress的值为‘HN’的所有数据行的SGender的值改为‘男’
update Student set SGender='男' where SAddress='HN'; --将数据表Student中字段Score的值小于等于95的所有数据行的Score的值加5 update Student set Score=Score+5 where Score<=95;
4、查询数据
命令格式:select <列名> from <表名> [where <查询条件>] [order by <排序的列名> [asc或desc]]
--查询数据表Student中的所有数据 select * from Student;
--查询数据表Student中SAddress为空的所有数据行
select * from Student where SAddress is null; --查询数据表Student中所有SID的值大于1并且SGender的值为‘女’的所有数据 select * from Student where SID>1 and SGender = '女'; --查询数据表Student中所有数据行的SID、SName、SAddress三列的值 select SID,SName,SAddress from Student;
ASC(降序排列),如果不指定排序方式,默认为降序。
DESC(升序排列)
--查询数据表Student中按照Score降序排列后的前5条数据 select * from Student where rownum<=5 order by Score desc; --查询数据表Student中的所有数据,按照Score列的值降序排列,如果Score列的值一样,则按照SName列的值升序排列 select * from Student order by Score desc,SName;
通配符(通常和LIKE搭配使用)
-
- %:匹配任意个字符
- _:匹配一个字符
--查询所有SName的值以‘张’字开头的数据行,例如,‘张三’,‘张大头’等(必须以‘张’字开头,后边可以有任意多个字符) select * from Student where SName like '张%'; --查询所有SName的值以‘张’字结尾的数据行,例如,‘张’,‘水牛张’等(必须以‘张’字结尾,前边可以有任意多个字符) select * from Student where SName like '%张'; --查询SName的值中包含‘小’字的所有数据行,例如‘小白’、‘李小二’、‘AA小’等 select * from Student where SName like '%小%'; --查询SName的值为两个字的所有数据行,例如,‘张三’,‘李四’,‘王五’等(只要求长度为2个字) select * from Student where SName like '__'; --查询所有SName的值为2个字,并且以‘张’字开头的所有数据行,例如,‘张三’,‘张扬’等(必须以‘张’字开头,必须为2个字) select * from Student where SName like '张_';
使用正则表达式
oracle10g以上支持正则表达式的Oracle 系统函数主要有下面四个:
-
- REGEXP_LIKE :与LIKE的功能相似
- REGEXP_INSTR :与INSTR的功能相似
- REGEXP_SUBSTR :与SUBSTR的功能相似
- REGEXP_REPLACE :与REPLACE的功能相似
--查询SName的值以F、K或者W开头的,由大写字母组成的长度为4的所有数据行 select * from Student where regexp_like(SName,'^[FKW][A-Z]{3}$'); --查询SName的值不是以F或者K开头的,有大写字母组成的长度为4的所有数据行 select * from Student where regexp_like(SName,'^[^FK][A-Z]{3}$');
分组查询的目的是为了将一组数据按照一定的规则进行分组,并对分组的结果进行分析,最终得到我们想要的数据。分组查询通常与一些聚合函数(详见Oracle 系统函数)一起使用。
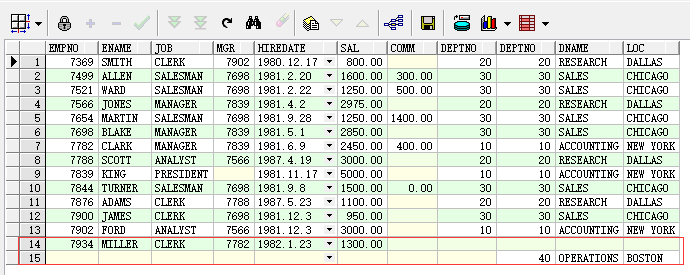
数据表EMP中有以下数据,我们通过该数据表进行接下来的工作:
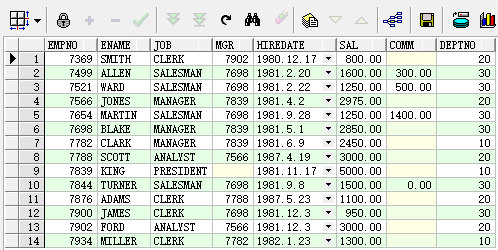
使用Group By时,需要注意,对select后边的列名是有限制的。
使用group by子句时,select后边的列名如果没有使用聚合函数,就必须作为分组依据,才能放在select后使用。
--错误的写法 select * from emp group by job;--将job作为分组依据,所有select后边只能使用job,或者是使用聚合函数
--select后使用了ename,但是ename没有作为分组依据
select ename,job from emp group by job; --正确写法 select job from emp group by job;--根据job分组,获取分组后每组的job select job,avg(sal),count(*) from emp group by job;--根据job分组,获取分组后每组的job、每组的平均工资以及每组的人数
select job,deptno,count(*) from emp group by job,deptno;--根据job和deptno分组,获取分组后的job、deptno以及每组的人数
执行结果分别如下:
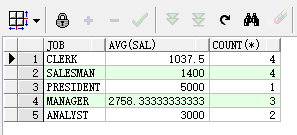
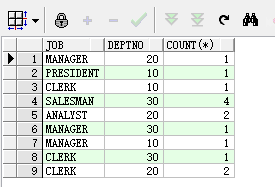
使用group by子句时,如果需要对分组结果进行筛选时,需要使用having,而不是where。
--获取部门中员工工资大于2000的人数和部门号 select deptno,count(*) from emp where emp.sal>2000 group by deptno --显示部门平均工资低于2000的部门号和它的平均工资 select deptno,avg(sal) from emp group by deptno having avg(sal)<2000;
--查询与SMITH同一部门的所有员工信息 select * from emp where deptno=(select deptno from emp where ename='SMITH'); --单列子查询 --查询与WARD一个部门且岗位一样的员工信息 select * from emp where (deptno,job)=(select deptno,job from emp where ename='WARD'); --多列子查询 --查询与SMITH同一部门的所有员工信息 select * from emp where deptno=(select deptno from emp where ename='SMITH'); --单行子查询 --查询每个部门工作最高的员工信息 select * from emp where sal in (select max(sal) from emp group by deptno); --多行子查询 --查询高于10号部门平均工资的所有员工信息信息 select * from emp where sal>(select avg(sal) from emp where deptno = 10); --from子句子查询 select e.* from (select empno,ename,sal from emp) e;
常用关键字(between...end...、is null、is not null、in、not in、exists、not exists、all、any、some)
between ... and ...(闭区间)
--查询所有Score的值为80-90的所有数据行 select * from Student where Score between 80 and 90;
is null/is not null
--查询所有SAddress的值为空的所有数据行 select * from Student where SAddress is null; --查询所有SMail的值不为空的所有数据行 select * from Student where SMail is not null;
in/not in
--查询SAddress为北京、上海、广州或者深圳的所有数据行 select * from Student where SAddress in ('北京','上海','广州','深圳'); --查询SAddress不是北京、上海、广州或者深圳的所有数据行 select * from Student where SAddress not in ('北京','上海','广州','深圳'); --查询所有与10号部门员工工作相同的员工信息 select * from emp where job in (select job from emp where deptno=10);
exists/not exists
--如果数据表emp中存在部门编号为10的数据行,则查询出数据表emp中的所有数据;如果不存在则不查询 select * from emp where exists(select 1 from emp where deptno =10); --如果数据表emp中不存在部门编号为10的数据行,则查询出数据表emp中的所有数据;如果存在则不查询 select * from emp where not exists(select 1 from emp where deptno =10);
子查询语句中的‘select 1’换成‘select *’也可以,这个地方写什么无所谓,因为子查询的结果只表示是否能够查询出数据,如果有数据,则主查询的where条件成立,如果没有查询出数据,则主查询的where条件不成立。
in和exists的区别
执行顺序:in先执行子查询,后执行主查询;exists先执行主查询,后执行子查询
执行效率:主查询的结果集记录条数>子查询的结果集记录条数,使用in效率更高(如果主查询的数据表中使用了索引,则使用主查询中的数据表的索引);主查询的结果集记录条数<子查询的结果集记录条数,使用exists的效率更高(如果子查询的数据表中使用了索引,则使用子查询中的数据表的索引)
not in和not exists
如果查询语句使用了not in 那么内外表都进行全表扫描,并且没有用到索引;而not extsts 的子查询依然能用到表上的索引。所以无论哪个表大,用not exists都比not in要快。
all
--查询出工资比10号部门所有员工都高的员工信息(查询工资高于10号部门最高工资的员工信息) select * from emp where sal > all(select sal from emp where deptno=30); select * from emp where sal > (select max(sal) from emp where deptno=30);
any
--查询出工资比10号部门任意一个员工高的员工信息(查询工资高于10号部门最低工资的员工信息) select * from emp where sal>any(select sal from emp where deptno=30); select * from emp where sal>(select min(sal) from emp where deptno=30);
some
some即一些。和any的用法基本相同,和in的作用也非常相似,用any的地方都可以用some代替。不过some大多用在=操作中。表示等于所选集合中的任何一个。当然any也可以用于=操作中,效果和some相同。
--查询出10,20,30号部门的所有员工 select * from emp where deptno in(10,20,30); select * from emp where deptno=any(10,20,30); select * from emp where deptno=some(10,20,30);
union、union all
union多表联接,将两个或多个查询结果集联接成一个结果集显示。
多表联接时,要求多个结果集的列数必须一致,并且对应列的数据类型也要一致。
union和union all的区别在于,union会去掉两个结果集中重复的元素,只保留其中一个;而union all不会去掉重复的数据。
select * from te where tid in (7369, 7499) union select empno, ename from emp where empno in (7369, 7499, 7521);--结果集有3条数据,tid分别为7369,7499,7521 select * from te where tid in (7369, 7499) union all select empno, ename from emp where empno in (7369, 7499, 7521);--结果集有5条数据,tid分别为7369,7369,7499,7499,7521
distinct
distinct的作用是去重,对于重复的数据只保留一个。
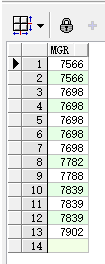
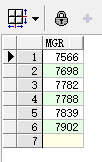
select mgr from emp order by mgr; select distinct mgr from emp order by mgr;
上边两行代码的执行结果分别为:
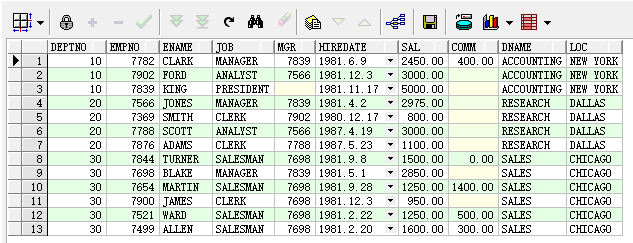
--查询所有员工的个人信息以及对应的部门信息 --1、from中使用子查询 select e.*,d.* from emp e,(select * from dept) d where e.deptno=d.deptno; --2、一次查询多张表,通过某种条件进行连接 select e.*,d.* from emp e,dept d where e.deptno=d.deptno; --3、通过inner join连接 select * from emp inner join dept on emp.deptno=dept.deptno;
- 外连接
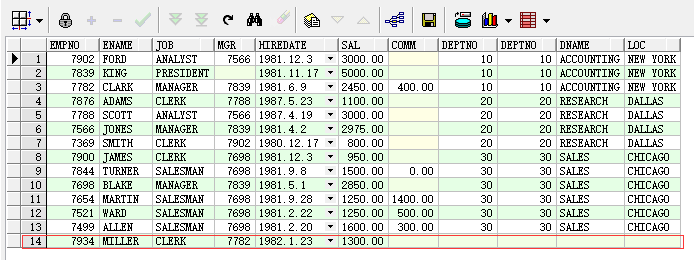
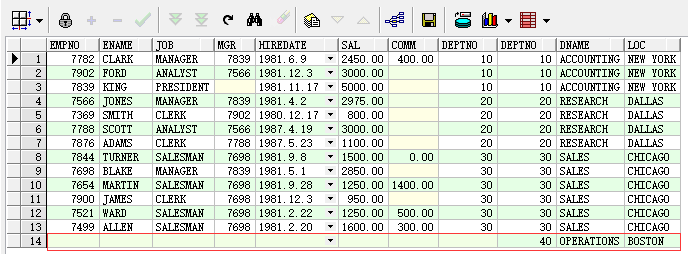
--查询所有员工的个人信息以及对应的部门信息 --1、左外连接(数据以左边的数据表为准,左边数据表中的数据一定会在结果集中出现,而右边数据表中的数据如果不满足连接条件则不会出现在结果中) select * from emp left join dept on emp.deptno=dept.deptno; --2、右外连接(数据以右边的数据表为准,右边数据表中的数据一定会在结果集中出现,而右边数据表中的数据如果不满足连接条件则不会出现在结果集中) select * from emp right join dept on emp.deptno=dept.deptno; --外链接的扩展 --1、左外连接(左边表独有的数据) select * from emp left join dept on emp.deptno=dept.deptno where dept.deptno is null; --2、右外连接(右边表独有的数据) select * from emp right join dept on emp.deptno=dept.deptno where emp.deptno is null;
上述通过左、右外连接两种方式获取所有员工个人信息和对应部门信息的查询语句的执行结果如下图所示:
左外连接:
右外连接:
获取左、右数据表独有数据的查询语句执行结果分别如下:
获取左边表独有数据:

获取右边表独有数据:

- 全连接
--获取左、右两张数据表的所有数据 select * from emp full join dept where emp.deptno=dept.deptno; --获取左、右两张数据独有的数据 select * from emp full join dept on emp.deptno=dept.deptno where emp.deptno is null or dept.deptno is null;

- 自然连接
--不需要为其指定连接条件,自然连接会自动匹配 select * from emp natural join dept;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号