
论文笔记:VDSR
CVPR 2016
1.之前方法存在的问题
SRCNN的缺点:
1.深度不够导致,感受野小。尤其是大尺度变换,从小patch中提取的信息不足以进行高质量重建。
2.收敛慢
3.只能实现单一尺度超分辨
2.这篇文章的改进和优点
1.本结构网络感受野更大。利用了更大区域的上下文信息。
2.残差学习和自适应梯度裁剪使得此模型学习率较高,收敛快,效果也好
另,由于LR和HR图像很大程度上共享信息,所以可以直接对残差图像建模。这应该是这篇文章最牛逼的地方了。LR和HR图像很大程度上是相似的,它们的低频信息相近,所不同的是LR缺少了很多高频信息。即:输出=低分辨输入+学习到的残差,这恰恰和resnet的思想高度吻合!
3.此网络可以满足多scale factor。(训练期间尺度增长)
3.本结构的步骤
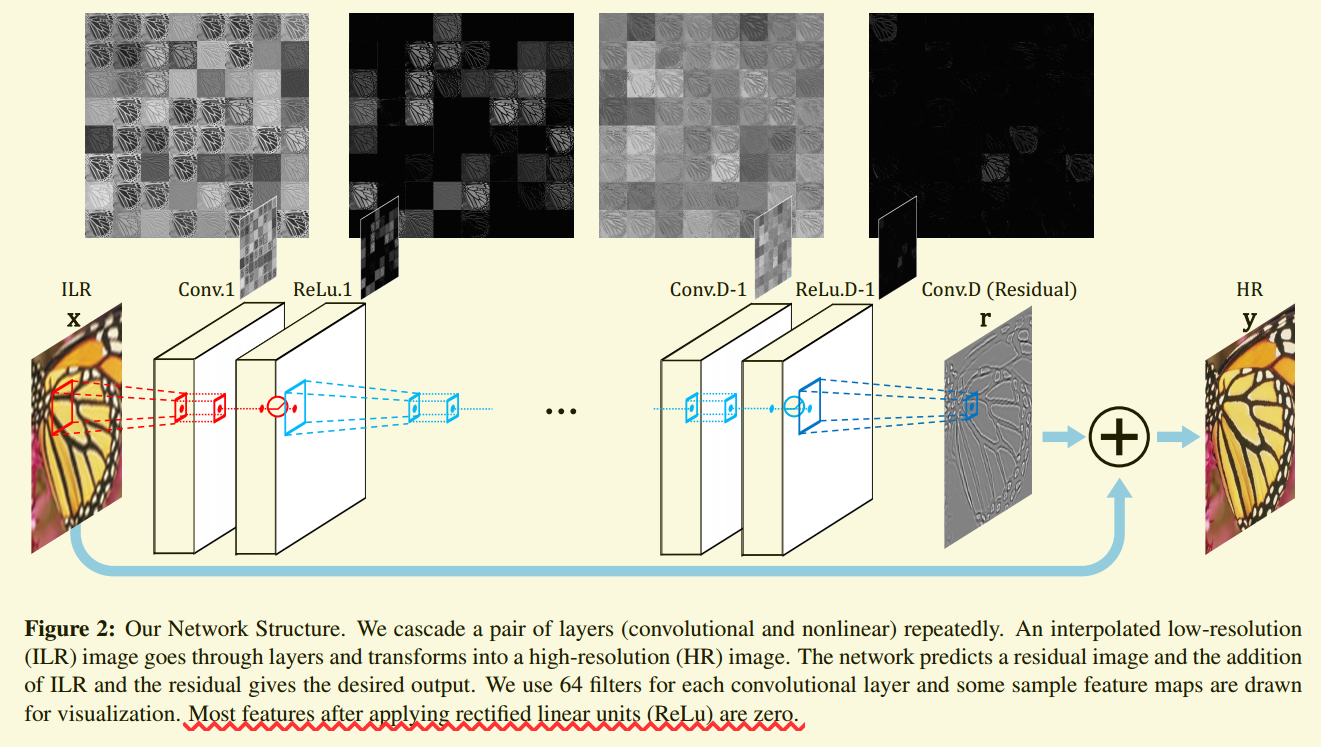
1.先将图像插值到目标尺寸,输入网络
2.针对亮度通道,中间进行了20层3*3卷积(使用零填充保持特征图尺寸)
3.输出
4.本文存在的问题
个人存在的疑问在于:单一网络多scale部分
残差学习不得不使得学习率较高

 浙公网安备 33010602011771号
浙公网安备 33010602011771号