
论文笔记:FSRCNN
n 本文是对SRCNN的改进,主要有三点:
1.在网络最后一层添加转置卷积层,以后端升采样结构取代SRCNN的前端升采样结构。
2.在非线性映射之前进行降维,mapping之后进行升维
3.filter size变小,而mapping层增多。
1.简介
经典的SRCNN无法满足实时性要求。经过研究我们发现这是因为其存在两个固有的局限:
1.由于SRCNN是先插值放大再输入网络,我们的计算复杂性就随着HR图像的尺寸平方次递增。例如,假如放大倍数为n,则计算代价是原始LR计算代价的$n^{2}$倍。如果网络直接学习LR图像,则可以加速$n^{2}$倍。
2.第二个局限是非线性映射层。输入图像块被映射到高维LR特征空间中,然后非线性映射到高维HR特征空间中。映射层更宽可以大大提高精读,但也降低了计算速度。
解决第一个问题的思路是,使用后端升采样的思路,在最后一层添加转置卷积,如此一来计算复杂度仅仅和LR图像的尺寸成正比。
解决第二个问题的思路是,使得非线性映射处在低维特征空间中。
我们的FSRCNN还有一个好处,就是针对不同的放大系数可以共享权值(转置卷积层以外的层的权值)
本文主要贡献三点:1.重新设计的沙漏型网络结构。2.实时性处理。3.针对不同放大系数的快速训练及测试。
2.Related Work
2.1 SR
SRCNN一经问世,迅速得到应用。有学者将其应用于具体领域,也有学者尝试更深的网络,也有学者使用基于先验知识的子网络代替SRCNN中第二层。但是都存在相应的问题。
2.2 CNN加速
很多学者试图加速CNN。我们的模型主要有两点区别:1. 其他学者专注于对现有训练好的模型的近似,而我们直接重新设计了网络结构。2.那些方法都是针对高层CV问题设计的,我们是针对底层问题。我们的模型不包括FC层,filter的近似值将严重影响结果。
3.FSRCNN
3.1 SRCNN
不多介绍
3.2 FSRCNN
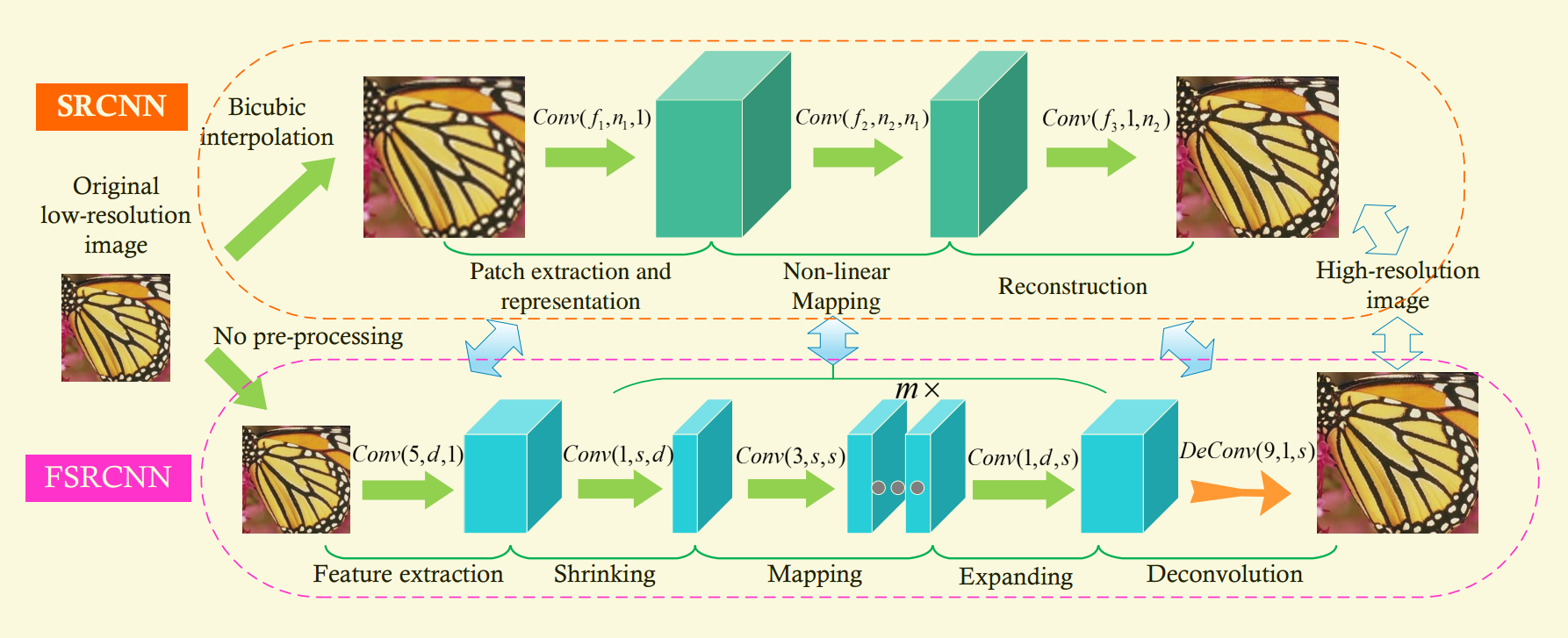
网络分为五部分:特征提取,压缩,非线性映射,扩充,转置卷积
网络的参数很多。其中对不敏感参数预先设定一个值,敏感参数未设定。敏感参数往往代表一些重要影响因素。
3.2.1 feature extraction
这部分类似于SRCNN 中的第一层,不同之处在于SRCNN是从插值图像抽取特征,而此处是从原始LR图像抽取特征。
超参设置:由于SRCNN中是从插值图像提取特征,f=9;而本文是从原始图像提取特征,因此设置f=5即可覆盖9*9的patch。另外设置c=1。现在只有filter数量$n_{1}$未设置,$n_{1}$也可以看作是LR特征的维度。$n_{1}$是第一个敏感向量。$n_{1}$记作d
第一层被表示为Conv(5, d, 1)
3.2.2 shrinking
在SRCNN中,由于d很大,所以第二层计算复杂度相对大,这一现象也存在于高层视觉任务中。
我们在第二层添上一个shrinking层来降维,使用的是1*1卷积,$n_{2}$=s. s<<d.
这一层被表示为Conv(1, s, d)
3.2.3 Non-linear mapping
非线性映射层的宽度和深度很关键。由于5*5卷积效果比1*1好,我们取一个折中3*3.为了保持好的表现,我们使用多个3*3卷积代替一个更宽的。
这一层被表示为m*Conv(3, s, s)
3.2.4 Expanding
这是shrinking层的反向过程。如果直接使用低维特征生成HR图像,效果降低(Set5上降低了0.3dB)。因此我们先将特征维度进行扩充。
这一层被表示为Conv(1, d, s)
3.2.5 Deconvolution
DeConv(9; 1; d)
转置卷积的相比直接插值的好处在于参数可学习。观察图三可知,转置卷积中学习到的filter像第一层一样是有意义的。

激活函数:使用PReLU以避免ReLU出现的dead feature
$$f \left( x_{i} \right) = max \left( x_{i}, 0 \right) + a_{i}min \left( 0, x_{i} \right)$$
损失函数:MSE
网络结构:Conv(5; d; 1)−PReLU −Conv(1; s; d)−PReLU −m×Conv(3; s; s)−PReLU − Conv(1; d; s) − PReLU − DeConv(9; 1; d)
计算复杂度:![]()
3.3 和SRCNN的不同
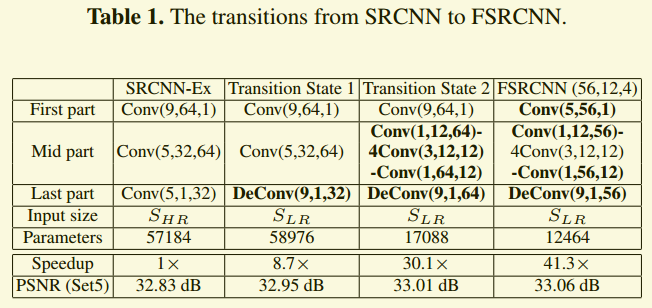
主要体现在本表中。首先使用转置卷积代替插值,速度得到加快,效果得到微微提升。之后改造映射层,参数大幅减少,速度大幅提升,效果得到微微提升。最后改造特征提取层,嫌少了一些冗余的参数,速度得到提升,同时效果得到很微弱的提升。
3.4 对于不同放大系数的优势
本网络中,只有最后一层含有放大系数的信息。实验表明,针对不同放大系数,本网络的卷积层filter几乎相同。而在SRCNN中针对不同放大系数,filters是截然不同的。
4.实验
4.1 实验细节
数据集:91image+General-100. 数据增强:scaling:0.9, 0.8, 0.7, 0.6, 2. ;旋转:90, 180, 270度旋转
测试集验证集:测试集:Set5 , Set14 and BSD200 验证集:BSD200中抽取20张。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号