
使用python操作HDF5文件
Hierarchical Data Format,又称HDF5
-
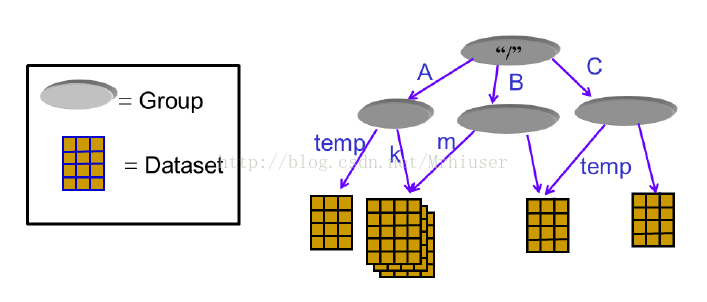
一个HDF5文件是一种存放两类对象的容器:dataset和group. Dataset是类似于数组的数据集,而group是类似文件夹一样的容器,存放dataset和其他group。在使用h5py的时候需要牢记一句话:groups类比词典,dataset类比Numpy中的数组。
-
-
HDF5 文件一般以 .h5 或者 .hdf5 作为后缀名,需要专门的软件才能打开预览文件的内容。HDF5 文件结构中有 2 primary objects: Groups 和 Datasets。
-
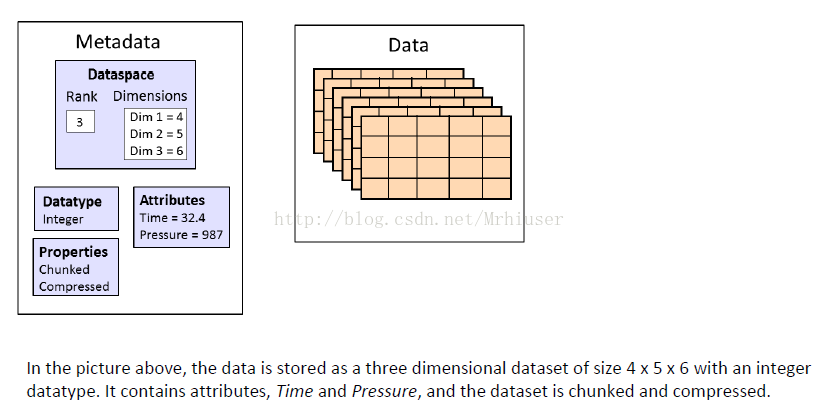
每个 dataset 可以分成两部分: 原始数据 (raw) data values 和 元数据 metadata (a set of data that describes and gives information about other data => raw data)。对于每一个dataset 而言,除了数据本身之外,这个数据集还会有很多的属性 attribute,。在hdf5中,还同时支持存储数据集对应的属性信息,所有的属性信息的集合就叫做metadata.
-
安装:
pip install h5py
对于数据集需要: 先创建h5文件,再去读h5文件 将dataset放在group里利用group进行层次嵌套.
1 f = filename.file得到文件的根目录 2 f.create_group("...../group_name") 3 f.create_dataset("...../dataset_name")
一般:
-
HDF5格式文件保存的是 : Model weights(字典,没有顺序)
-
JSON 和 YAML 格式文件保存的是: Model structure(顺序靠json描述)
-
h5格式:可以同时保存weights和structure
利用numpy数据初始化
1 #还可以直接用np数组给dataset初始化,此时data就涵盖了shape和dtype,即shape = data.shape,.... 2 arr = np.arange(100) 3 dset = f.create_dataset("/mydataset1",data = arr)#i4:32位的integer[-2^31,2^31]
数据处理上的用途
利用python的文件操作及数组等方式将训练数据及测试数据集标签,按数据划分方法,将文件名写入到python数组,最终将这些处理好的数组写入hdf5格式文件给dataset初始化.
示例
1 import h5py 2 import numpy as np 3 coco = h5py.File("D:/annot_coco.h5","r")#coco.name == / 根节点 4 # print(coco) 5 # print(coco["bndbox"]) 6 #只是遍历直接相连的一级节点 7 for name in coco: 8 # 本身就是字符串 9 print(coco[name]) 10 print(coco[name][:2]) 11 12 # def printname(name): 13 # print(name) 14 # 15 # 16 # 17 # #遍历整个coco下的节点 18 # coco.visit(printname) 19 #dataset.attrs 20 #dataset对象可以有自己的属性, 但所有属性数据的长度加起来不能超过64K, 包括属性名字. 21 22 dset.attrs['length'] = 100 23 dset.attrs['name'] = 'This is a dataset' 24 for attr in dset.attrs: 25 print attr, ":", dset.attrs[attr] 26 length : 100 27 name : This is a dataset
注意:
1 imgname_array = coco["imgname"][:]#不一样的,这是标准用法,还是要先取到全部,再去索引,否则结果维度不一样 2 # imgname_ = coco["imgname"][:1]#轴不会减少 3 # print(imgname_array.shape) 4 # print(imgname_)#[1,16] 5 # print(type(imgname_dataset)) 6 # print(type(imgname_array)) 7 img = imgname_array[0]
写字符串到h5文件
1 test_h5 = h5py.File("D:/test.h5","w") 2 imgname = np.fromstring('000000262145.jpg',dtype=np.uint8).astype('float64')#str_imgname------>float64 3 test_h5 .create_dataset('imgname', data=imgname)#变成f8之后就可以直接往h5中写了 4 test_h5.close() 5 """ 6 最后得出来的矩阵长度是字符串的长度。---1个字符串的长度就是对应编码的h5向量的长度 7 如果想将多个字符串拼成一个大的numpy矩阵,写到h5文件中,必须先将字符串转换成相同长度。 8 通常的做法是在字符串后面补上\x00。 9 """
从h5数据读出字符串格式
1 test_h5 = h5py.File("D:/test.h5","r") 2 img = test_h5['imgname'][:] 3 img = img.astype(np.uint8).tostring().decode('ascii') 4 print(img) 5 test_h5.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号