
linux性能统计分析
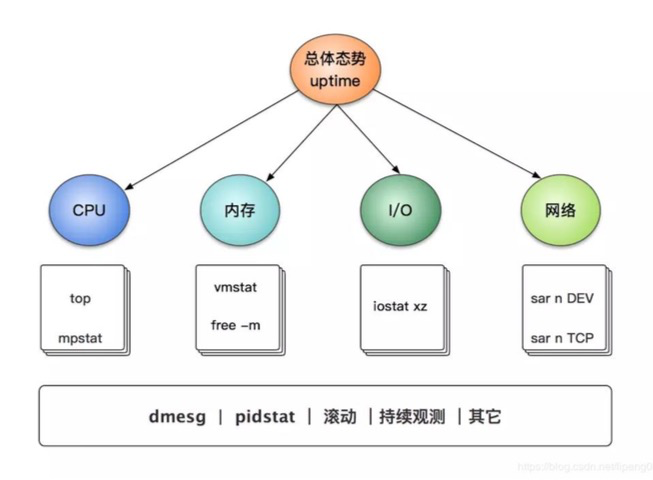
一、uptime
17:03:37 up 203 days, 5:45, 10 users, load average: 0.07, 0.11, 0.13
当前时间 开机时间203天 5小时45分 ,10个正在登陆的用户,平均负载:1分钟的,5分钟的和1
深入理解负载
cpu==1; load average ==1, cpu时刻在用
cpu==4; load average==1 ,cpu只使用25%
平均负载数不大于3,则系统运行良好!
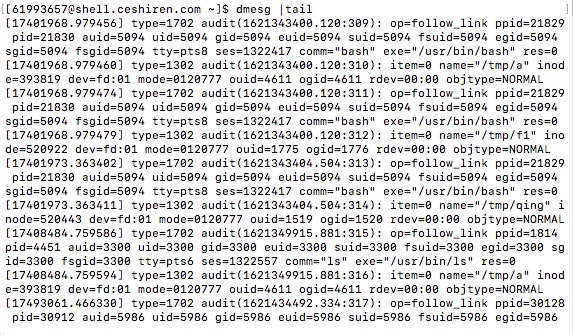
二、dmesg
打印10条系统日志信息
三、vmstat

字段含义说明:
(来自https://blog.csdn.net/m0_38110132/article/details/84190319)
|
类别 |
项目 |
含义 |
说明 |
|
Procs(进程) |
r |
等待执行的任务数 |
展示了正在执行和等待cpu资源的任务个数。当这个值超过了cpu个数,就会出现cpu瓶颈。 |
|
B |
等待IO的进程数量 |
|
|
|
Memory(内存) |
swpd |
正在使用虚拟的内存大小,单位k |
|
|
free |
空闲内存大小 |
|
|
|
buff |
已用的buff大小,对块设备的读写进行缓冲 |
|
|
|
cache |
已用的cache大小,文件系统的cache |
|
|
|
inact |
非活跃内存大小,即被标明可回收的内存,区别于free和active |
具体含义见:概念补充(当使用-a选项时显示) |
|
|
active |
活跃的内存大小 |
具体含义见:概念补充(当使用-a选项时显示) |
|
|
Swap |
si |
每秒从交换区写入内存的大小(单位:kb/s) |
|
|
so |
每秒从内存写到交换区的大小 |
|
|
|
IO |
bi |
每秒读取的块数(读磁盘) |
块设备每秒接收的块数量,单位是block,这里的块设备是指系统上所有的磁盘和其他块设备,现在的Linux版本块的大小为1024bytes |
|
bo |
每秒写入的块数(写磁盘) |
块设备每秒发送的块数量,单位是block |
|
|
system |
in |
每秒中断数,包括时钟中断 |
这两个值越大,会看到由内核消耗的cpu时间sy会越多
秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目 |
|
cs |
每秒上下文切换数 |
||
|
CPU(以百分比表示) |
us |
用户进程执行消耗cpu时间(user time) |
us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期超过50%的使用,那么我们就该考虑优化程序算法或其他措施了 |
|
sy |
系统进程消耗cpu时间(system time) |
sys的值过高时,说明系统内核消耗的cpu资源多,这个不是良性的表现,我们应该检查原因。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足 |
|
|
Id |
空闲时间(包括IO等待时间) |
一般来说 us+sy+id=100 |
|
|
wa |
等待IO时间 |
wa过高时,说明io等待比较严重,这可能是由于磁盘大量随机访问造成的,也有可能是磁盘的带宽出现瓶颈。 |
posted on 2021-05-21 11:42 crystal1126 阅读(55) 评论(0) 编辑 收藏 举报


