
linux三剑客grep、sed、awk
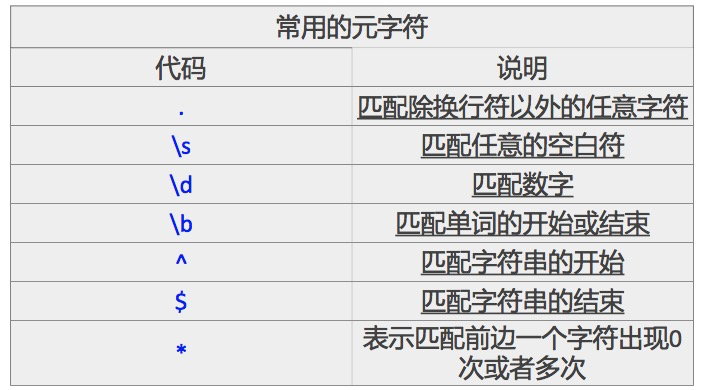
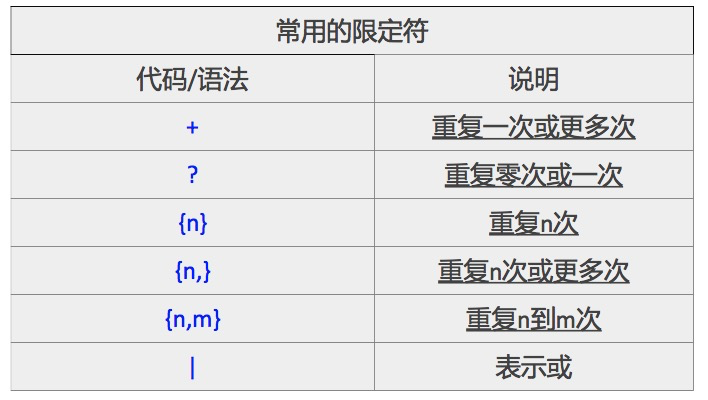
linux三剑客grep、sed、awk一般都会配合正则表达式进行使用,正则表达式的常用元字符如下:
普通正则
扩展正则
一、grep
1、命令形式
grep [options] pattern [file]
2、选项

注:grep使用扩展正则的时候要用-E
3、实战
(1)查找文件中显示root的行号
grep -n root test.txt

(2)查看文件中不显示root的行号
grep -nv root test.txt

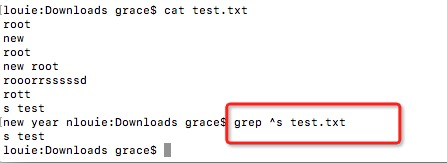
(3)查找以s开头的行
grep ^s test.txt
(4)查找以n结尾的行
grep ^s test.txt

二、sed
sed是流编辑器,一次处理一行数据。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。然后读入下行,执行下一个循环。
1、命令形式
sed [-hn..][-e<script>][-f<script FILE][FILE]
-h:显示帮助
-n:仅显示script处理后的结果
-e<script>:以选项中指定的script来处理输入的文本文件。
-f<script>以选项中指定的script文件来处理输入的文本文件。
2、常用命令
a:新增 sed -e '4a newline' (在第4行后面新增一行newline)
c:取代 sed -e '2,5c No 2-5 number' (用c后面的内容‘No 2-5 number’取代2-5行的内容)
d:删除 sed -e '2,5d' (删除2-5行的内容)
i:插入 sed -e '2i newline' (在第2行前面插入一行,内容为'newline')
p:打印 sed -n 'root/p' (两个/之间的内容代表正则,打印出匹配root的内容)
s:取代 sed -e 's/old/new/g' (用new取代old,g 表示全局取代,不加g只能替换每一行的第一个匹配的内容)
3、实战
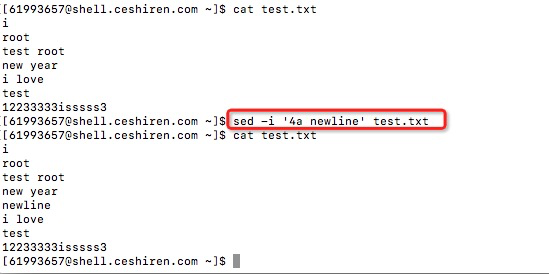
(1)sed -e '4a newline' (在第4行后面新增一行newline)

未修改文件内容,直接修改文件内容需要加-i
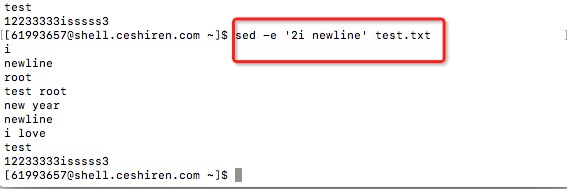
(2)sed -e '2i newline' (在第2行前面插入一行,内容为'newline')
(3)取代 sed -e 's/root/hello/g' (用hello取代root,/g 表示全局取代,不加/g只能替换每一行的第一个匹配的内容)

使用g的效果

3、awk
把文件文件逐行读入,并以空格为默认分隔符进行逐行切片,切开后的内容再进行后续处理。
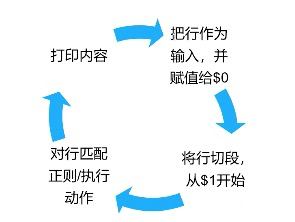
1、命令形式
awk 'pattern+action' [file]
2、常用参数


3、实战
(1)打印/etc/password文件中有root信息的行,并打印出shell信息
awk -F : '/root/{print $7}' /etc/password (以':'进行域分隔,$7对应shell信息一列)
awk中使用正则时,需要用/ /括起来
(2)打印/etc/password文件的第二行内容
awk -F : 'NR==2{print $0}' /etc/password
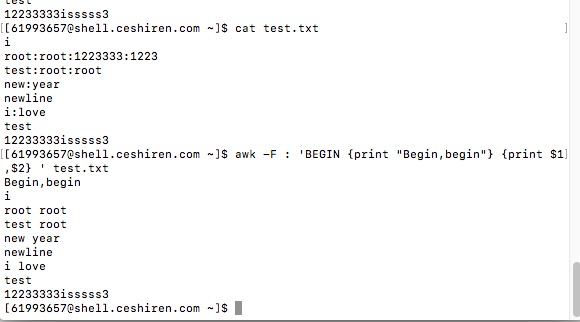
(3)使用Begin加入标题,并打印$1,$2
awk -F : 'BEGIN {print "Begin,begin"} {print $1,$2} ' test.txt
4、自定义分隔符
$ echo '11 22|33|44|55'|awk 'BEGIN{RS="|"} {print $0}'

4、linux三剑客实战
log文件中内容的格式如下:
223.104.7.59 - - [05/Dec/2018:00:00:01 +0000] "GET /topics/17112 HTTP/2.0" 200 9874 "https://www.googleapis.com/auth/chrome-content-suggestions" "Mozilla/5.0 (iPhone; CPU iPhone OS 12_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) CriOS/70.0.3538.75 Mobile/15E148 Safari/605.1" 0.040 0.040 .
(1)找出log中的404 500的报错有多少条
grep -E ' 404 | 500 ' nginx.log |wc -l
awk '/ 404 | 500 /' nginx.log |wc -l
awk '$9~/404|500/' nginx.log |wc -l (将第9列与404和500进行匹配)

(2)查找访问量最高的ip
awk '{print $1}' nginx.log| sort |uniq -c|sort -nr|head -3
先打印出所有的ip;然后排序;然后删除重复的行,并在每一行旁边显示重复次数;按照数值大小倒序排序;取前3个

grep -oE '^[0-9]*.[0-9]*.[0-9]*.[0-9]*' nginx.log |sort|uniq -c|sort -nr|head -3

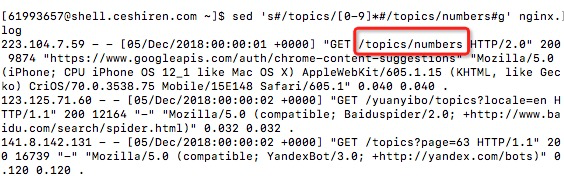
(3)将nginx.log中的/topics/数字修改成/topics/numbers
sed 's#/topics/[0-9]*#/topics/numbers#g' nginx.log (sg之间的分割符号不局限于用/,也可以用其他符号代替)
(4)将所有的ip地址横向打印
awk '{print $1}' nginx.log | sed ':1;N;s/\n/|/g;t1'
N的作用是将下一行的内容追加到上一行(包含换行符)
:1的作用是对命令的位置打标记
t1的作用是跳转到标记处

posted on 2021-05-18 18:48 crystal1126 阅读(77) 评论(0) 编辑 收藏 举报


