Selenium元素定位的几种方式
一、通过id查找
例:<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
element = driver.find_element_by_id("kw")
二、通过name查找
例:<input name="cheese" type="text"/>
cheese = driver.find_element_by_name("cheese")
三、通过classname查找
例:<div class="cheese"><span>Cheddar</span></div>
cheeses = driver.find_elements_by_class_name("cheese")
四、通过标签名查找
例:<iframe src="..."></iframe>
frame = driver.find_element_by_tag_name("iframe")
五、通过链接文本查找
例:<a href="http://www.baidu.com">转到百度</a>
ele = driver.find_element_by_link_text("转到百度")
注:有的时候,链接的文本很长,我们甚至只需要通过部分文本去找到该链接元素
只要这个链接文本是唯一的就行
六、通过CSS选择器查找
eles = driver.find_element_by_css_selector('#choose_car option')
基本用法:
|
方式 |
用法 |
举例 |
描述 |
|
根据class查找 |
.class |
.intro |
查找class=”intro”元素 |
|
根据id查找 |
#id |
#firstname |
查找id=”firstname”的元素 |
|
根据标签名查找 |
tagname |
div |
查找<div>元素 |
|
根据属性查找 |
[attribute] |
[target] |
查找具有”target”属性的元素 |
|
[attribute=value] |
[target=_blank] |
查找包含target=”_blank”的元素 |
|
|
[attribute^=value] |
[href^=”https”] |
查找包含href属性,且该属性的值以”https”开头的元素 |
|
|
[attribute$=value] |
[href$=”.pdf”] |
查找包含href属性,且该属性的值以”.pdf”结尾的元素 |
|
|
[attribute*=value] |
[href*=”abc”] |
查找包含href属性,且该属性的值包含“abc”的元素 |
高级用法:
|
用法 |
举例 |
描述 |
|
后代元素选择器 |
div p |
选择所有在<div>里面的<p> |
|
子元素选择器 |
div>p |
选择所有<div>的<p>子元素 |
|
组选择器,同时选择多个元素 |
<div>,<p> |
同时选择所有的<div>元素和<p>元素 |
|
相邻兄弟元素 |
<div>+<p> |
选择所有<div>后面紧跟的<p>元素 |
|
兄弟元素 |
<div>~<p> |
选择所有<div>元素后面的<P>元素(不一定要紧跟) |
|
:empty |
p:empty |
选择没有子节点(包括文本)的<p>元素 |
|
:first-child |
p:first-child |
选择所有是 父元素第一个元素的<p>元素 |
|
:first-of-type |
p:first-of-type |
选择所有是 父元素第一个<p>元素的<p>元素 |
|
:last-child |
p:last-child |
选择所有是其父元素最后一个元素的<p>元素 |
|
:last-of-type |
p:last-of-type |
选择所有是其父元素最后一个<p>元素的<p>元素 |
|
:nth-child(n) |
p:nth-child(2) |
选择所有是其父元素第二个元素的<p>元素 |
|
:nth-of-type(n) |
p:nth-of-type(2) |
选择所有是其父元素的第二个<p>元素的<p>元素 |
|
:nth-last-child(n) |
p:nth-last-child(2) |
选择所有是其父元素倒数第二个元素的<p>元素 |
|
:nth-last-of-type(n) |
p:nth-last-of-type |
选择所有是其父元素倒数第二个<p>元素的<p>元素 |
|
:only-child |
p:only-child |
选择所有是其父元素唯一一个子元素的<p>元素 |
|
:only-of-type |
p:only-of-type |
选择所有是其父元素唯一一个<P>子元素的<p>元素 |
|
:not(selector) |
:not(p) |
选择所有不是<p>元素的元素 |
七、通过Xpath查找
eles = food.find_elements_by_xpath('./p')
基本用法:
|
用法 |
举例 |
描述 |
|
绝对路径(/) |
/html/body/div/p |
表示html文档中的p节点,xpath路径表示了元素的位置 |
|
相对路径(//) |
//footer//p |
表示footer元素中所有的后代P类型元素 |
|
混合使用 |
//footer/div/p |
表示html文档中footer元素下的div元素下的p元素 |
|
根据属性选择 |
//*[@style]
//*[not(@style)](不包含) |
表示选择HTML文档下所有包含style属性的元素 |
|
//p[@spec='len2']
|
选择所有具有spec 属性且值为“len2” 的p元素 |
|
|
//a[contains(@href,'51job.com')]
|
选择所有具有href属性,且该属性的值包含“51job.com”的a元素 |
|
|
//a[starts-with(@href,'http://big5.51job')] |
表示属性href以“http://big5.51job”开头 |
高级用法:
|
方式 |
用法 |
举例 |
描述 |
|
根据文本定位元素
|
全部文字 |
//*[text()='花呗套现'] |
文本等于“花呗套现”的元素 |
| 部分文字 | //*[contains(text(),'花呗') | 文本包含"花呗”的元素 | |
|
子元素选择器 |
根据下标获取(下标从1开始) |
//div[@id='food']/p[1] |
获取第一个p子元素 |
|
倒数索引 |
//div[@id='food']/*[last()](倒数第一个) //div[@id='food']/*[last()-1](倒数第二个) //div[@id='food']/*[last()-2](倒数第三个) |
last()代表倒数第一个元素
|
|
|
postion():代表元素的位置 |
//div[@id='food']/*[position()=2] |
表示第二个元素 |
|
|
//div[@id='food']/[position()=last()] |
表示最后一个元素 |
||
|
//div[@id='food']/[position()=last()-2] |
表示倒数第三个元素 |
||
|
//div[@id='food']/[position()>=last()-2] |
表示最后三个元素 |
||
|
组选择器 |
用竖线隔开 |
//p | //button |
等价于css中的p, button |
|
相邻兄弟选择器 |
following-sibling:: |
//*[@id=’food’]/following-sibling::div |
选择id=food节点的相邻兄弟div元素
|
|
preceding-sibling:: |
//*[@id=’food’]/preceding-sibling::div |
选择id=food节点的前面的兄弟P元素
|
selenium高级语法参考:https://www.cnblogs.com/crystal1126/p/12807407.html
元素的相对定位:
如:
food = driver.find_element_by_id("food")
eles = food.find_elements_by_xpath('./p')
如果不加点 ,eles = food.find_elements_by_xpath('/p') 与 eles = driver.find_elements_by_xpath('/p') -----这两个方式效果是一样的
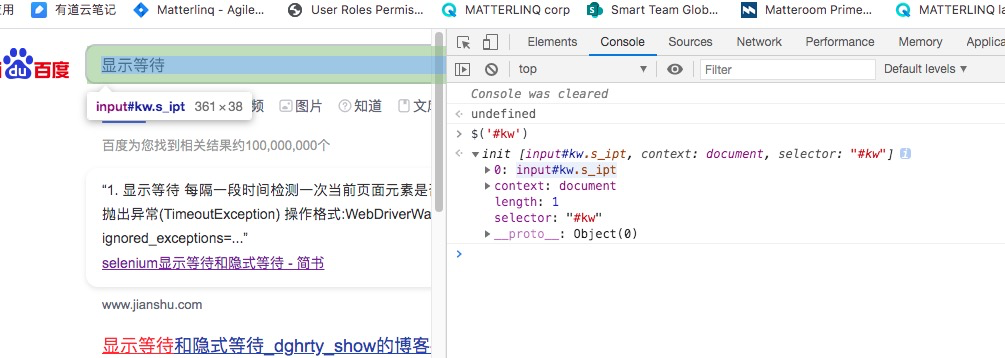
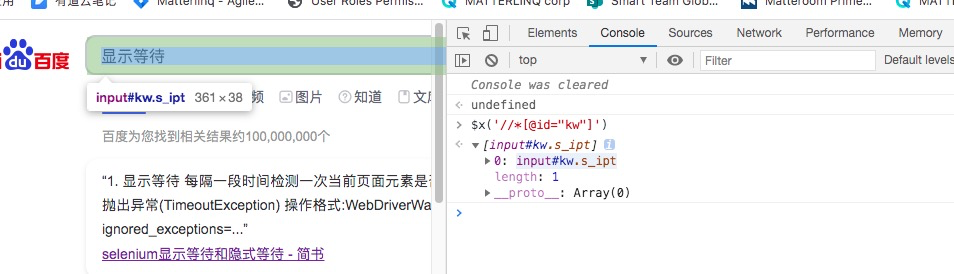
在浏览器console中确认元素定位是否正确
CSS定位方式:$('#kw')
xpath定位方式:$x('//*[@id="kw"]')
posted on 2019-09-22 21:26 crystal1126 阅读(1627) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号