【夜莺监控方案】04-k8s集群监控(下)(kube-state-metrics+cadvisor+prometheus+n9e及FAQ)
前言
相关文档如下:
《03-k8s集群监控(上)》
4. 接入prometheus
说明:
- k8s集群的prometheus负责采集k8s集群信息
- n9e中的prometheus再读取集群中prometheus的数据
这样便于多个k8s集群接入、管理、删除
- 配置 prometheus
修改配置文件 prometheus.yml,添加如下内容:
############### crust-k8s ########################
- job_name: 'crust-k8s'
scrape_interval: 15s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job=~"kubernetes-.*"}'
static_configs:
- targets:
- '10.10.xxx.201:30003'
labels:
cluster: 'crust-k8s' #用该标签区分集群
############### do-k8s ########################
- job_name: 'do-k8s'
scrape_interval: 15s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job=~"kubernetes-.*"}'
static_configs:
- targets:
- '10.10.xxx.100:30003'
labels:
cluster: 'do-k8s'
- 容器prometheus
n9e的prometheus写好了启动文件,直接启动即可。
# service prometheus restart
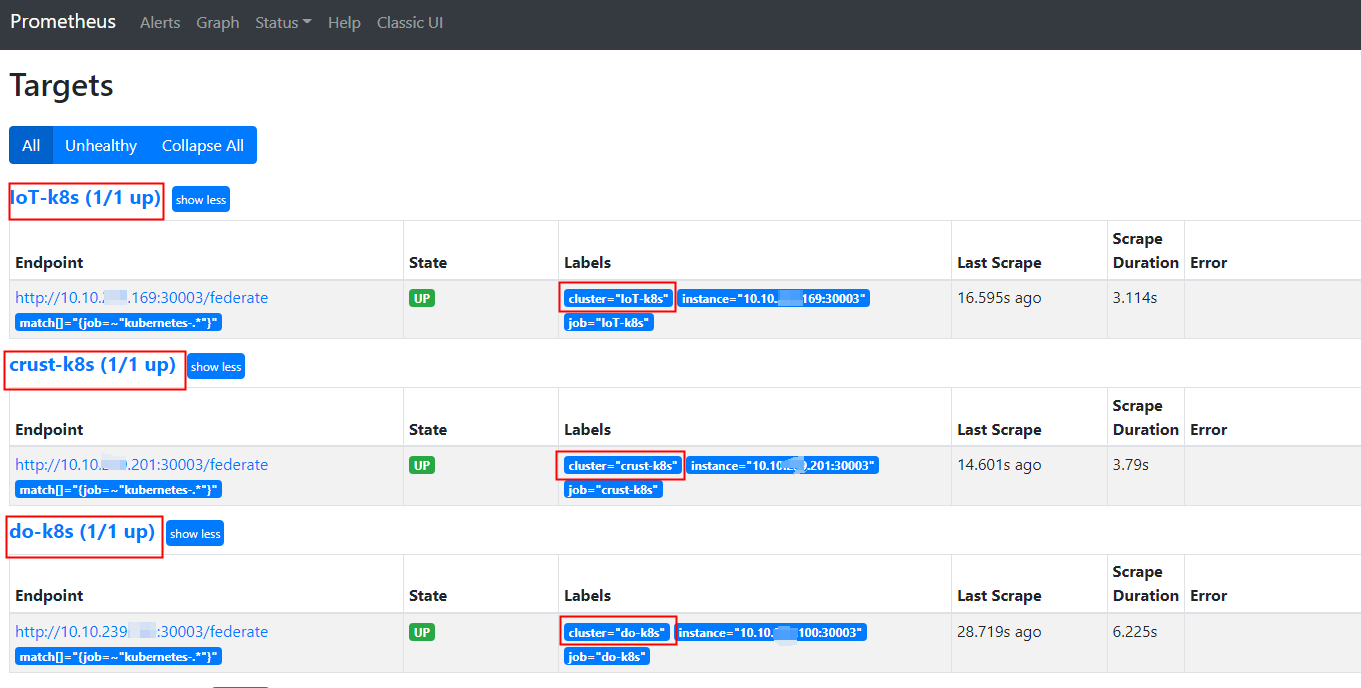
- 查看结果
5. 接入n9e
5.1 手动接入(方法一)
创建图表入口:
监控看图 > 监控大盘 > 新建大盘 > 新建大盘分组 > 新建图表
- 配置方式
因为k8s集群中需要计算的数据比较多,因此我们使用prometheus 配置方式(n9e配置方式不支持计算)

- Promql
sum by (pod) (rate(container_cpu_usage_seconds_total{image!="",namespace="$namespace",cluster="$cluster"}[1m] ) )
我们使用了 n a m e s p a c e 和 namespace 和 namespace和cluster 两个变量作为筛选条件,接下来配置变量
- 配置变量
![image.png]()

变量名: 仅为用户提供过滤的标识(promql中变量名不是它)
Filter metric:仅是一个筛选标签或资源分组的条件,没有实际意义。
标签或资源分组:从下拉框中选择一个作为筛选条件,注意promql 中变量名写的是它
5.2 导入模板(方法二)
[
{
"id": 0,
"name": "kubernetes",
"tags": "k8stest",
"configs": "{\"tags\":[{\"tagName\":\"cluster\",\"key\":\"cluster\",\"value\":\"do-k8s\",\"prefix\":false,\"metric\":\"container_cpu_usage_seconds_total\"},{\"tagName\":\"namespace\",\"key\":\"namespace\",\"value\":\"iot-v3x\",\"prefix\":false,\"metric\":\"container_cpu_usage_seconds_total\"}]}",
"chart_groups": [
{
"id": 0,
"dashboard_id": 0,
"name": "容器cpu相关",
"weight": 0,
"charts": [
{
"id": 518,
"group_id": 81,
"configs": "{\"name\":\"pod_cpu使用率【单位%】\",\"mode\":\"prometheus\",\"prome_ql\":[\"sum by (pod) (rate(container_cpu_usage_seconds_total{image!=\\\"\\\",namespace=\\\"$namespace\\\",cluster=\\\"$cluster\\\"}[1m]))\"],\"layout\":{\"h\":2,\"w\":8,\"x\":0,\"y\":0,\"i\":\"0\"}}",
"weight": 0
},
{
"id": 519,
"group_id": 81,
"configs": "{\"name\":\"pod_cpu用户态使用率 【单位%】\",\"mode\":\"prometheus\",\"prome_ql\":[\"sum by (pod) (rate(container_cpu_user_seconds_total{image!=\\\"\\\",namespace=\\\"$namespace\\\",cluster=\\\"$cluster\\\"}[1m]))\"],\"layout\":{\"h\":2,\"w\":8,\"x\":8,\"y\":0,\"i\":\"1\"}}",
"weight": 0
},
{
"id": 520,
"group_id": 81,
"configs": "{\"name\":\"pod_cpu内核态使用率【单位%】\",\"mode\":\"prometheus\",\"prome_ql\":[\"sum by (pod) (rate(container_cpu_system_seconds_total{image!=\\\"\\\",namespace=\\\"$namespace\\\",cluster=\\\"$cluster\\\"}[1m]))\"],\"layout\":{\"h\":2,\"w\":8,\"x\":16,\"y\":0,\"i\":\"2\"}}",
"weight": 0
}
]
},
{
"id": 0,
"dashboard_id": 0,
"name": "容器内存相关",
"weight": 1,
"charts": [
{
"id": 517,
"group_id": 82,
"configs": "{\"name\":\"pod_mem已使用内存(不含cache)单位:M\",\"mode\":\"prometheus\",\"prome_ql\":[\"sum by (pod) ((container_memory_usage_bytes{image!=\\\"\\\",namespace=\\\"$namespace\\\",cluster=\\\"$cluster\\\"})-(container_memory_cache{image!=\\\"\\\",namespace=\\\"$namespace\\\",cluster=\\\"$cluster\\\"}))/1024/1024\"],\"layout\":{\"h\":2,\"w\":24,\"x\":0,\"y\":0,\"i\":\"0\"}}",
"weight": 0
},
{
"id": 195,
"group_id": 82,
"configs": "{\"name\":\"pod_mem已使用大小(包含cache)(单位:M)\",\"mode\":\"prometheus\",\"link\":\"http://10.10.239.201:30003/\",\"prome_ql\":[\"sum by (pod) (container_memory_usage_bytes{image!=\\\"\\\",namespace=\\\"$namespace\\\",cluster=\\\"$cluster\\\"})/1024/1024\"],\"layout\":{\"h\":2,\"w\":24,\"x\":0,\"y\":2,\"i\":\"1\"}}",
"weight": 0
}
]
},
{
"id": 0,
"dashboard_id": 0,
"name": "容器io",
"weight": 2,
"charts": [
{
"id": 196,
"group_id": 83,
"configs": "{\"name\":\"pod网络io\",\"mode\":\"prometheus\",\"link\":\"http://127.0.0.1:9090\",\"prome_ql\":[\"sort_desc(sum by (pod_name) (rate (container_network_transmit_bytes_total{image!=\\\"\\\",namespace=\\\"$namespace\\\",cluster=\\\"$cluster\\\"}[5m]) ))\"],\"layout\":{\"h\":2,\"w\":24,\"x\":0,\"y\":0,\"i\":\"0\"}}",
"weight": 0
}
]
},
{
"id": 0,
"dashboard_id": 0,
"name": "pod数量",
"weight": 3,
"charts": [
{
"id": 197,
"group_id": 84,
"configs": "{\"name\":\"集群运行中的pod总数量\",\"mode\":\"prometheus\",\"link\":\"http://127.0.0.1:9090\",\"prome_ql\":[\"sum(kubelet_running_pod_count{cluster=\\\"$cluster\\\"})\"],\"layout\":{\"h\":2,\"w\":24,\"x\":0,\"y\":0,\"i\":\"0\"}}",
"weight": 0
}
]
}
]
}
]
6. FAQ
6.1 集群数据时常取不到
【现象】
如下图,数据经常取不到

###【分析】
查看n9e的Prometheuse数据如下:

点击上图中 do-k8s的数据页面,访问确实会超过10s,而Prometheus的默认超时时间是10s
【解决】
修改n9e上Prometheus的超时时间,添加scrape_timeout选项,时间设置高一些。
global:
scrape_interval: 60s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 60s # Evaluate rules every 15 seconds. The default is every 1 minute.
scrape_timeout: 20s # scrape_timeout is set to the global default (10s).
重启Prometheus。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号