
如何优雅重启 kubernetes 的 Pod

最近在升级服务网格 Istio,升级后有个必要的流程就是需要重启数据面的所有的 Pod,也就是业务的 Pod,这样才能将这些 Pod 的 sidecar 更新为新版本。
方案 1
因为我们不同环境的 Pod 数不少,不可能手动一个个重启;之前也做过类似的操作:
kubectl delete --all pods --namespace=dev
这样可以一键将 dev 这个命名空间下的 Pod 删掉,kubernetes 之后会自动将这些 Pod 重启,保证和应用的可用性。
但这有个大问题是对 kubernetes 的调度压力较大,一般一个 namespace 下少说也是几百个 Pod,全部需要重新调度启动对 kubernetes 的负载会很高,稍有不慎就会有严重的后果。
所以当时我的第一版方案是遍历所有的 deployment,删除一个 Pod 后休眠 5 分钟再删下一个,伪代码如下:
deployments, err := clientSet.AppsV1().Deployments(ns).List(ctx, metav1.ListOptions{})
if err != nil {
return err
}
for _, deployment := range deployments.Items {
podList, err := clientSet.CoreV1().Pods(ns).List(ctx, metav1.ListOptions{
LabelSelector: fmt.Sprintf("app=%s", deployment.Name),
})
err = clientSet.CoreV1().Pods(pod.Namespace).Delete(ctx, pod.Name, metav1.DeleteOptions{})
if err != nil {
return err
}
log.Printf(" Pod %s rebuild success.\n", pod.Name)
time.Sleep(time.Minute * 5)
}
存在的问题
这个方案确实是简单粗暴,但在测试的时候就发现了问题。
当某些业务只有一个 Pod 的时候,直接删掉之后这个业务就挂了,没有多余的副本可以提供服务了。
这肯定是不能接受的。
甚至还有删除之后没有重启成功的:
- 长期没有重启导致镜像缓存没有了,甚至镜像已经被删除了,这种根本就没法启动成功。
- 也有一些 Pod 有
Init-Container会在启动的时候做一些事情,如果失败了也是没法启动成功的。
总之就是有多种情况导致一个 Pod 无法正常启动,这在线上就会直接导致生产问题,所以方案一肯定是不能用的。
方案二
为此我就准备了方案二:
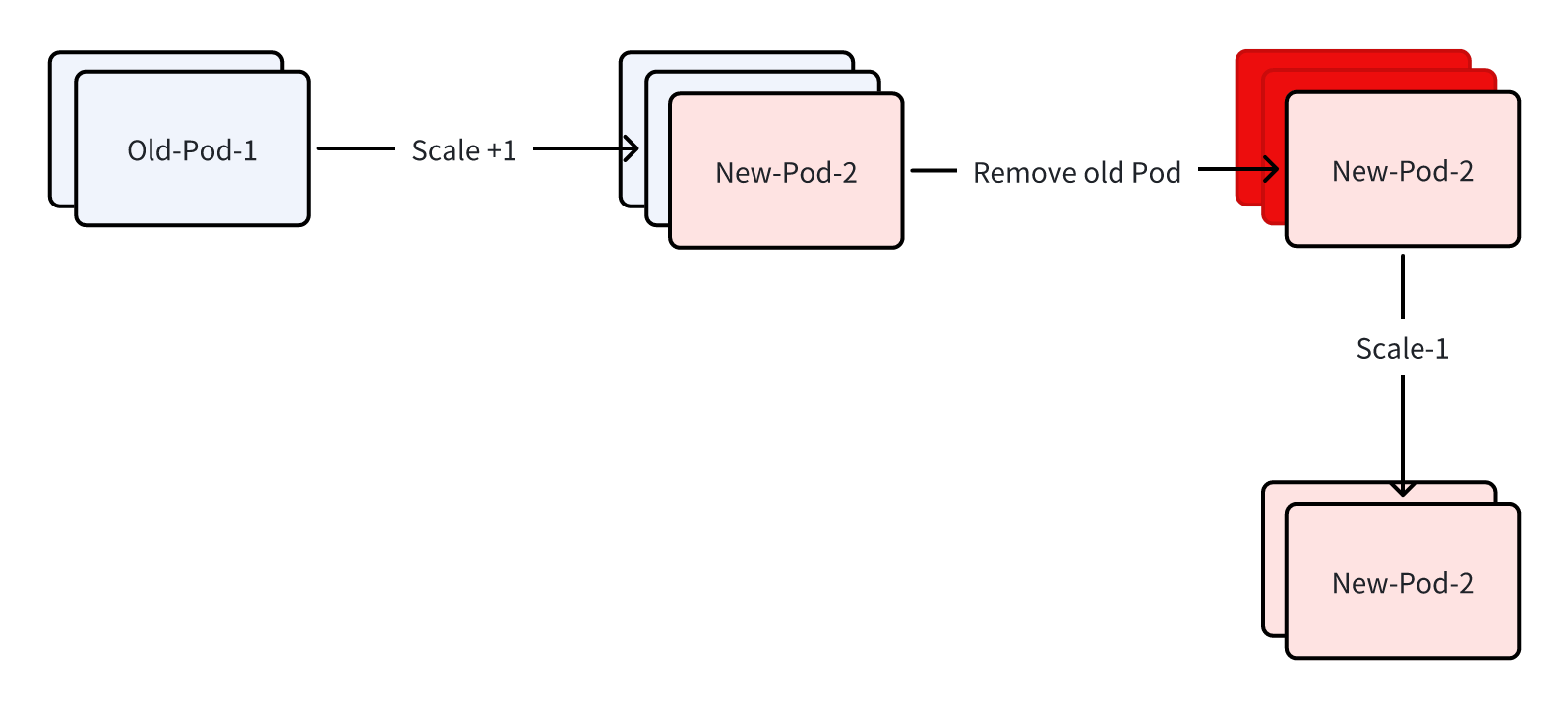
- 先将副本数+1,这是会新增一个 Pod,也会使用最新的 sidecar 镜像。
- 等待新建的 Pod 重启成功。
- 重启成功后删除原有的 Pod。
- 再将副本数还原为之前的数量。
这样可以将原有的 Pod 平滑的重启,同时如果新的 Pod 启动失败也不会继续重启其他 Deployment 的 Pod,老的 Pod 也是一直保留的,对服务本身没有任何影响。
存在的问题
看起来是没有什么问题的,就是实现起来比较麻烦,流程很繁琐,这里我贴了部分核心代码:
func RebuildDeploymentV2(ctx context.Context, clientSet kubernetes.Interface, ns string) error {
deployments, err := clientSet.AppsV1().Deployments(ns).List(ctx, metav1.ListOptions{})
if err != nil {
return err
}
for _, deployment := range deployments.Items {
// Print each Deployment
log.Printf("Ready deployment: %s\n", deployment.Name)
originPodList, err := clientSet.CoreV1().Pods(ns).List(ctx, metav1.ListOptions{
LabelSelector: fmt.Sprintf("app=%s", deployment.Name),
})
if err != nil {
return err
}
// Check if there are any Pods
if len(originPodList.Items) == 0 {
log.Printf(" No pod in %s\n", deployment.Name)
continue
}
// Skip Pods that have already been upgraded
updateSkip := false
for _, container := range pod.Spec.Containers {
if container.Name == "istio-proxy" && container.Image == "proxyv2:1.x.x" {
log.Printf(" Pod: %s Container: %s has already upgrade, skip\n", pod.Name, container.Name)
updateSkip = true
}
}
if updateSkip {
continue
}
// Scale the Deployment, create a new pod.
scale, err := clientSet.AppsV1().Deployments(ns).GetScale(ctx, deployment.Name, metav1.GetOptions{})
if err != nil {
return err
}
scale.Spec.Replicas = scale.Spec.Replicas + 1
_, err = clientSet.AppsV1().Deployments(ns).UpdateScale(ctx, deployment.Name, scale, metav1.UpdateOptions{})
if err != nil {
return err
}
// Wait for pods to be scaled
for {
podList, err := clientSet.CoreV1().Pods(ns).List(ctx, metav1.ListOptions{
LabelSelector: fmt.Sprintf("app=%s", deployment.Name),
})
if err != nil {
log.Fatal(err)
}
if len(podList.Items) != int(scale.Spec.Replicas) {
time.Sleep(time.Second * 10)
} else {
break
}
}
// Wait for pods to be running
for {
podList, err := clientSet.CoreV1().Pods(ns).List(ctx, metav1.ListOptions{
LabelSelector: fmt.Sprintf("app=%s", deployment.Name),
})
if err != nil {
log.Fatal(err)
}
isPending := false
for _, item := range podList.Items {
if item.Status.Phase != v1.PodRunning {
log.Printf("Deployment: %s Pod: %s Not Running Status: %s\n", deployment.Name, item.Name, item.Status.Phase)
isPending = true
}
}
if isPending == true {
time.Sleep(time.Second * 10)
} else {
break
}
}
// Remove origin pod
for _, pod := range originPodList.Items {
err = clientSet.CoreV1().Pods(ns).Delete(context.Background(), pod.Name, metav1.DeleteOptions{})
if err != nil {
return err
}
log.Printf(" Remove origin %s success.\n", pod.Name)
}
// Recover scale
newScale, err := clientSet.AppsV1().Deployments(ns).GetScale(ctx, deployment.Name, metav1.GetOptions{})
if err != nil {
return err
}
newScale.Spec.Replicas = newScale.Spec.Replicas - 1
newScale.ResourceVersion = ""
newScale.UID = ""
_, err = clientSet.AppsV1().Deployments(ns).UpdateScale(ctx, deployment.Name, newScale, metav1.UpdateOptions{})
if err != nil {
return err
}
log.Printf(" Depoloyment %s rebuild success.\n", deployment.Name)
log.Println()
}
return nil
}
看的出来代码是比较多的。
最终方案
有没有更简单的方法呢,当我把上述的方案和领导沟通后他人都傻了,这也太复杂了:kubectl 不是有一个直接滚动重启的命令吗。
❯ k rollout -h
Manage the rollout of one or many resources.
Available Commands:
history View rollout history
pause Mark the provided resource as paused
restart Restart a resource
resume Resume a paused resource
status Show the status of the rollout
undo Undo a previous rollout
kubectl rollout restart deployment/abc
使用这个命令可以将 abc 这个 deployment 进行滚动更新,这个更新操作发生在 kubernetes 的服务端,执行的步骤和方案二差不多,只是 kubernetes 实现的比我的更加严谨。
后来我在查看 Istio 的官方升级指南中也是提到了这个命令:

所以还是得好好看官方文档
整合 kubectl
既然有现成的了,那就将这个命令整合到我的脚本里即可,再遍历 namespace 下的 deployment 的时候循环调用就可以了。
但这个 rollout 命令在 kubernetes 的 client-go 的 SDK 中是没有这个 API 的。
所以我只有参考 kubectl 的源码,将这部分功能复制过来;不过好在可以直接依赖 kubect 到我的项目里。
require (
k8s.io/api v0.28.2
k8s.io/apimachinery v0.28.2
k8s.io/cli-runtime v0.28.2
k8s.io/client-go v0.28.2
k8s.io/klog/v2 v2.100.1
k8s.io/kubectl v0.28.2
)
源码里使用到的 RestartOptions 结构体是公共访问的,所以我就参考它源码魔改了一下:
func TestRollOutRestart(t *testing.T) {
kubeConfigFlags := defaultConfigFlags()
streams, _, _, _ := genericiooptions.NewTestIOStreams()
ns := "dev"
kubeConfigFlags.Namespace = &ns
matchVersionKubeConfigFlags := cmdutil.NewMatchVersionFlags(kubeConfigFlags)
f := cmdutil.NewFactory(matchVersionKubeConfigFlags)
deploymentName := "deployment/abc"
r := &rollout.RestartOptions{
PrintFlags: genericclioptions.NewPrintFlags("restarted").WithTypeSetter(scheme.Scheme),
Resources: []string{deploymentName},
IOStreams: streams,
}
err := r.Complete(f, nil, []string{deploymentName})
if err != nil {
log.Fatal(err)
}
err = r.RunRestart()
if err != nil {
log.Fatal(err)
}
}
最终在几次 debug 后终于可以运行了,只需要将这部分逻辑移动到循环里,加上 sleep 便可以有规律的重启 Pod 了。
参考链接:
作者: crossoverJie

欢迎关注博主公众号与我交流。
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出, 如有问题, 可邮件(crossoverJie#gmail.com)咨询。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号