
软件分析笔记6:上下文敏感指针分析
对于指针分析尤其是Java指针分析来说,上下文敏感是最有效的提升精度的方法,上下文敏感的指针分析是指针分析领域最近几年研究的热点,上下文敏感不是指针分析独有的技术,理论上所有跨函数间的分析都会涉及到上下文敏感。我们当前先研究上下文敏感的指针分析。
1.上下文不敏感指针分析的缺陷
我们用一个例子来说明为什么我们需要上下文敏感技术,示例程序如下图所示:

我们使用之前的指针分析来分析上面的程序,这个程序很简单,入口是main函数,然后定义了一个接口Number,定义了两个类One和Two分别继承了这个接口,main中创建了两个对象n1和n2,并将这两个对象传导方法id里(id是identity的缩写)并分别返回x和y,我们要分析的是i的值是多少。动态运行时i的值明显为1,静态分析时用常量传播方式来判断i的值。
要知道i的值,我们需要先知道x.get()调用的对象,使用指针分析方法解决x.get的调用。
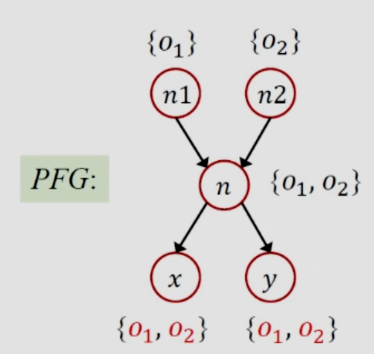
如上图所示,x来自于id方法的返回值,因为id方法有两个实参n1和n2,做指针分析时候做PFG,n1和n2都会留给形参n,二者分别指向o1和o2,因此这两个对象都留到了n的指针集里,又根据n分别返回了x和y,因此o1和o2返回了x和y,因此分析结果如下:
可得x.get()调用了两个方法(分别是One和Two中的get()方法),因此返回值就是1和2,因此结论i的值为NAC,这个结果肯定是不准的,分析过程中多了一条调用边,上下文不敏感就是这样对于调用语句不做区分,因此造成了精度的下降,因此我们提出了上下文敏感的指针分析,对于该实例的上下文敏感分析如下:

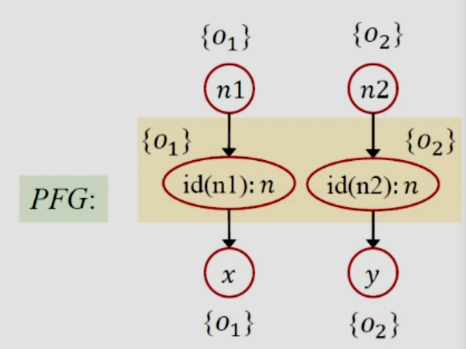
从代码来看,id方法有两个调用(前面已经提到),上下文敏感就是将这两个调用区分开,id(n1)这次分析就是将n1参数传递给id(n1)中的形参n,id(n2)同理,二者分开分析,返回值也是如法炮制,将一个方法的不同调用区分开,这样就可以得到更精确的结果。

2.Introduction
2.1上下文不敏感精度低的原因
上下文不敏感(简称C.I.)在动态执行过程中一个方法可能会被调用很多次,但是每次调用的上下文可能会不同(在指针分析中通常就是参数和返回点不一样),在C.I.中对于一个方法所有的调用都传给了同一个形参,它们混在一起不做区分,之后会通过返回值等方式将所有的调用的数据流都传回去,副作用就是假设我们对于传回来的对象的field进行修改,如果不区分的话所有的数据流都会被修改,被错误修改的数据流会传到程序的其他部分,这样就会形成假的数据流(spurious data flows)。
2.2上下文敏感(C.S.)
为了克服上面的问题,我们采用上下文敏感的方式,上下文敏感可以区分不同上下文下的数据流。
最经典的上下文敏感技术是call-site sensiticity(call-string ),对于方法的上下文,它将调用点的相关信息用一个串串起来,串的内容如下:
- call site
- call site所在方法的caller
- call site所在方法caller的caller
这个上下文实际上就是对于动态执行过程的一个抽象。我们用一个例子来理解该方法:

对于id(Number)这个方法有哪些上下文呢?
一个call site就是一个语句,在该示例中,id方法有两个call site id(n1)和id(n2),因此id方法就有两个上下文id(n1)和id(n2)
2.3Cloning-Based C.S
实现上下文最基本的策略是使用克隆的方法,在C.S.中,对于所有的方法都要用上下文加以修饰,对于所有变量也需要加上上下文的修饰(该上下文来自于变量所在的方法),给每个方法和变量修饰之后就相当于对它们进行了“克隆”。上面的代码用这种方法分析就可以得到:
这样就能避免上下文非敏感导致的精度的丢失。
2.4Context-Sensitive Heap
OO语言(如Java)会频繁对对象进行操作,我们将这种行为称为heap-intensive,为了取得较好的操作,我们也要给堆加上下文,称之为heap contexts。
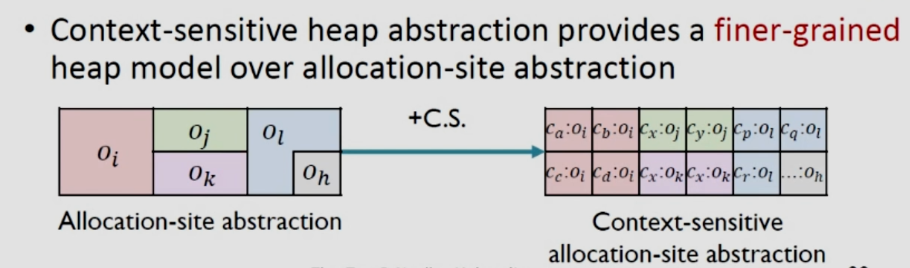
就是将上下文敏感技术应用到堆抽象之上,上图左边是将五个调用点堆抽象,而在右边用不同上下文对它们进行细分,提高了粒度。
原理
程序动态执行时一个调用点在不同的上下文时会创建不同的对象,如果上下文不敏感的话会导致假的数据流,这也就是为什么我们需要利用上下文敏感进行堆抽象。
示例
我们用一个例子来解释上下文敏感堆这个概念:
n1 = new One();
n2 = new Two();
x1 = newX(n1);
x2 = newX(n2);
n = x1.f;
XnewX(Number p){
X x = new X();
x.f = p;
return x;
}
class X{
Number f;
}
在函数newX中创建了一个对象x,然后将x的field设置成p再将它返回,n指向哪个对象呢?很明显动态执行时指向的是n1所指向的new One()对象,下面我们分别用上下文敏感堆和不敏感堆对n的指向进行分析。
C.S.,no C.S.heap

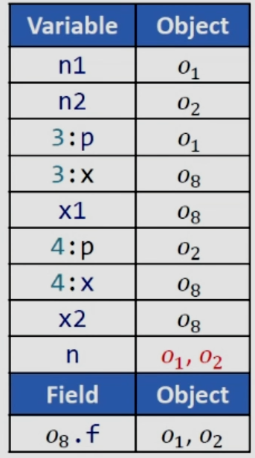
可以看到,在分析完x1和x2的指向之后,o8.f指向o1和o2,n从x1中读取,而从表格中可知x1指向o8,因此最终得到n的指向是o1和o2,我们知道动态运行时n不会指向o2,这里就产生了假的数据流。这是因为在newX中因为参数的不同我们是创建了两个不同的对象x,在当前的做法下没有区分这两个对象,这就会导致问题的出现。
C.S.+C.S.heap
通过分析第八行,对于3:x就指向了3:o8,对应的3:o8.f就指向了o1,同理分析x2,可得结果如下:
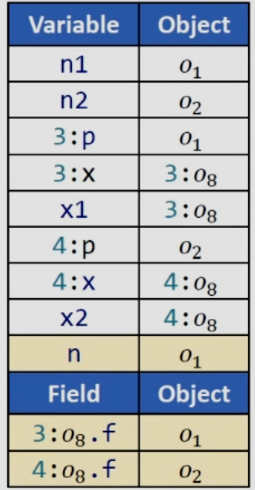
可以很明显的看到,采用C.S.heap方法能够显著的提高分析精度。
C.I.+C.S.heap
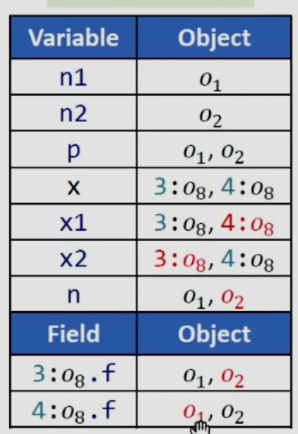
可以看到如果没有变量的上下文只是用堆上下文也不能实际上提高精度。
总结
heap上下文和变量上下文是相辅相成缺一不可的,二者缺了哪一个都不能有效的提升精度。
3.Rules
3.1Domains and Notations

在上下文敏感的指针分析中,程序中的所有部件都用上下文分析。C代表指针分析中的所有上下文,具体的上下文用小写的c来分别表示。
- 上下文敏感方法:对于域M进行扩展,将它与所有上下文C相乘
- 上下文变量同上
- 上下文对象同上
- Field本身不需要上下文,但是在引用某个具体的实例Field的时候就将它们拓展(即挂靠)。
- 上下文敏感指针,指针有两种类型,变量和field,因此上下文敏感指针就由这两部分组成
- 指向关系pt,将上下文敏感的指针指向带着上下文对象的集合
3.2指针分析的规则
3.2.1综述
以下是上下文敏感指针分析中前四种语句的规则,这其实就是之前不敏感指针分析的变种(添加了上下文)
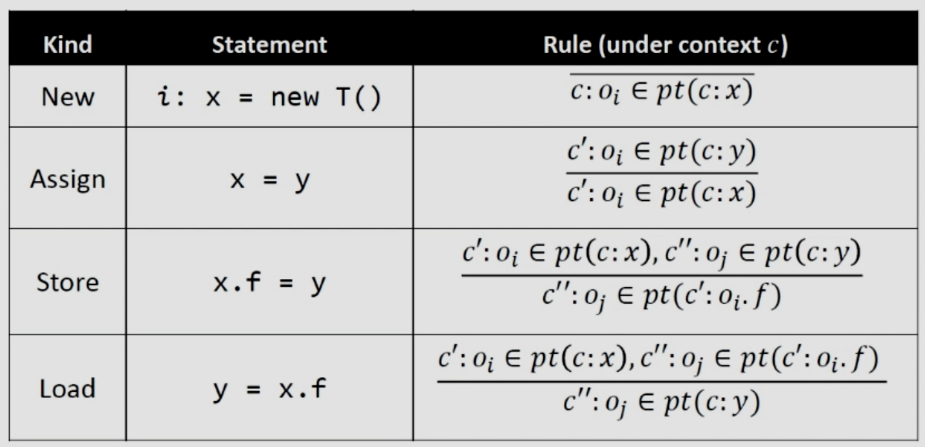
首先假设语句都是属于某个方法的,语句就会从对应的方法获取上下文进行对应的操作,下面我们分开来看这四种语句。
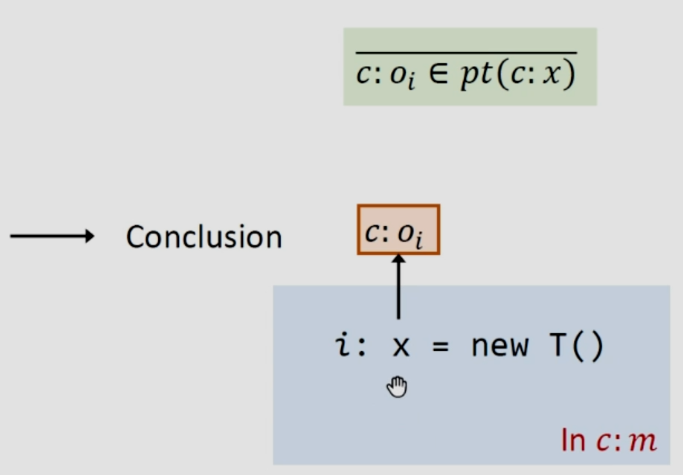
3.2.2Rule:New
就是一个对象的创建,假设语句属于某个方法m,在上下文c之下。该变量也就是上下文c之下的变量
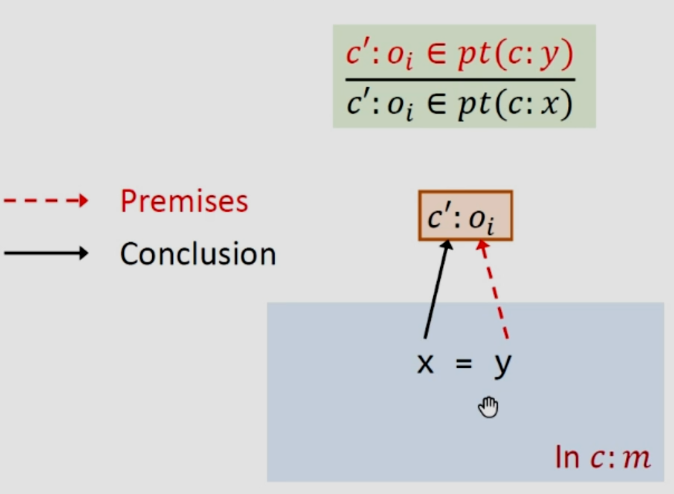 如上图所示,c之下创建出来的对象用c:oi表示,并且用c之下的x指针指向c:oi。
如上图所示,c之下创建出来的对象用c:oi表示,并且用c之下的x指针指向c:oi。
3.2.3Rule:Assign
就是赋值语句,就是将y的值给了x。
假设我们在上下文c之下分析这个赋值语句,就认为这里的x和y都是在c之下的,如果某个对象被c之下的y所指向,就将它加入到c之下x指向的集合中
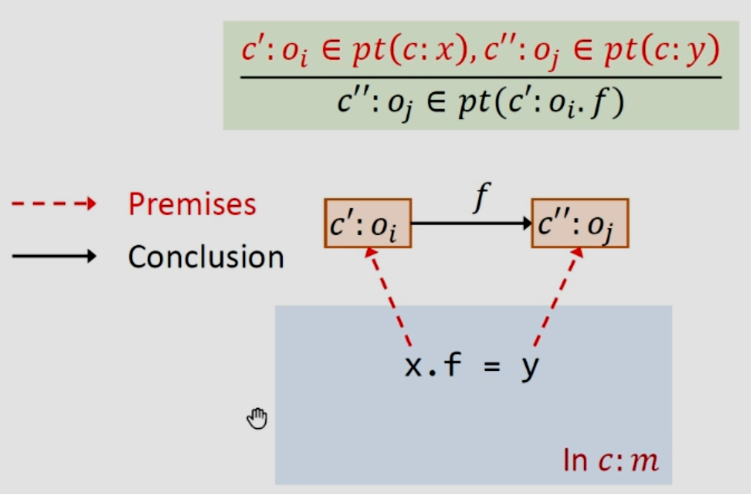
3.2.4Rule:Store
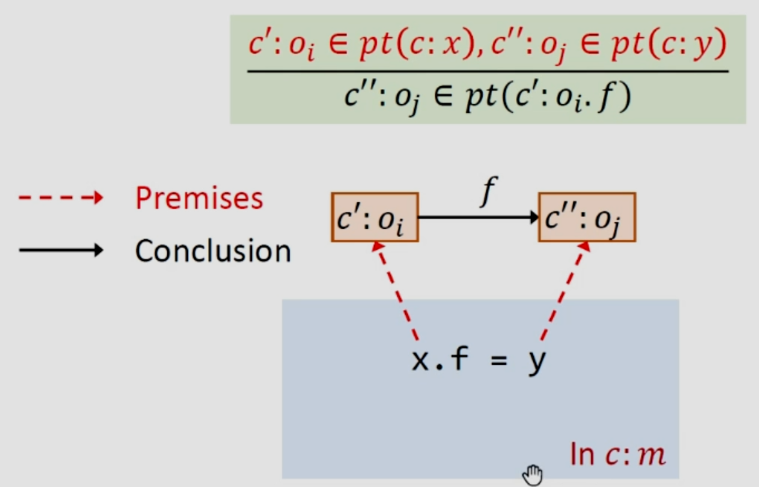
如下图,还是假设这条语句是在上下文c之中,c‘和c''可能相同也可能不同,x和y的c一定是一样的。

store是将y指向的对象存给x指向对象的一个field:f,首先我们去除x在c之下指向的对象和c之下y指向的对象,接下来将后者添加到前者的field:f所指向的集合中。
3.2.5Rule:Load
Load和Store是对称的。理解了Store再理解Load就很简单了,这里就不展开说了。
3.2.6Rule:Call
这是最复杂的上下文敏感分析。
Call语句决定了上下文是怎样产生的,所以对于Call语句的上下文分析是最重要的。
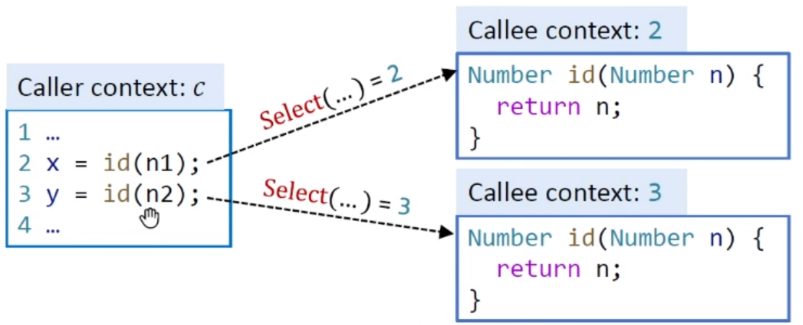
我们先假设调用是在某个方法里,该方法上下文是c,我们可以先求出c'.oi,这个是recieve object,然后进行Dispatch,根据对象类型以及方法签名k可以得到目标方法,用m表示,接下来我们要选择上下文,我们定义了一个Select函数,对于一个目标函数m,根据call site l这一点能拿到的信息选择上下文,得到ct,用我们前面的例子来解释如下:
假设我们出去左边的代码,上下文为c,先处理第二行代码,假设我们使用Select方法对语句2得到的结果是2,那么我们就说对于第二行的上下文就是2,同理对第三行进行一样的操作(这里沿袭了clone-based的方法),这样就将语句的上下文就取出来了,我们真正的目标方法就是这个上下文之下的该方法。
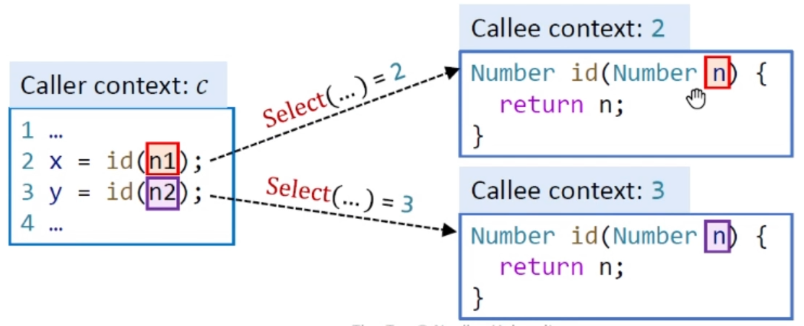
接下来我们要开始传recieve object,将它传给ct之下的mthis,然后就是传参,这个过程跟recieve object类似,将c之下所有的实参取出来,将它们传给特定上下文的形参。如下图所示
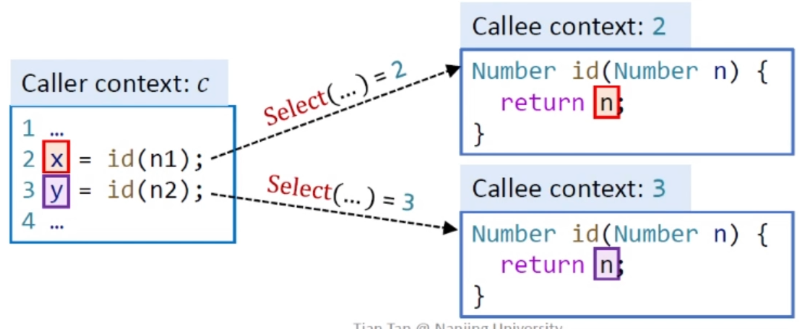
我们要将n1传给上下文2中的n(即2:n),n2传给上下文3中的n(即3:n),二者不会混合和冲突。
最后一步是传返回值,如果是ct中返回值指向的就将它传给当前上下文c中等号左边的变量。
还是之前的例子,在处理第二行调用时,上下文2中的返回值n应该传给第二行中的x,同理上下文3中的返回值n应该传给第三行中的y。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号