
软件分析笔记:3.过程分析(Interprocedural Analysis)
本文是针对南京大学《软件分析》谭添老师的视频课的课堂笔记。
1.Motivation
此前我们讨论的问题都是过程内的,也就是不涉及到方法调用。然而实际程序中方法调用屡见不鲜,继续采用之前的分析方法会丢失精度,这也就是为什么我们需要过程(间)分析。二者的区别如下:
过程内分析Intra-procedural Analysis
- 只考虑过程内部语句,不考虑过程调用
- 目前的所有分析都是过程内的
过程间分析Inter-procedural Analysis
- 考虑过程调用的分析
- 有时又称为全程序分析Whole Program Analysis
- Call edges和Return edges
- 需要call graph
2.Call Graph(调用图)
2.1调用图的概念以及简单示例
本质上可以看做是一个调用边的集合,每个调用边从调用点连接到目标方法(target methods或者callees),简单例子如下:
void foo(){
int n = ten();
addOne(42)
}
int ten(){
return 10;
}
int addOne(int x){
int y = x + 1;
return y;
}
上面代码所对应的调用图如下所示:
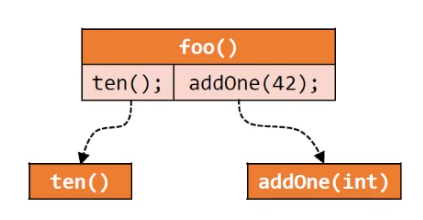
该程序有三个方法(foo()、ten()、addOne()),调用图就是由调用点引出的箭头指向被调用的方法。
2.2调用图的应用
- 理论上所有过程间(跨函数)分析的基础
- 程序的优化
- 程序理解
- 程序debugging
- 程序测试
2.3针对面向对象语言的调用图构造(以Java为例)
2.3.1代表性算法
- Class hierarchy analysis(CHA)
- Rapid type analysis(RTA)
- Variable type analysis(VTA)
- Pointer analysis(k-CFA)
以上四个算法的排列是有规律的,从上到下越往下精度越高(more precise),越往上速度越快(more efficient)。我们将重点学习第一个和最后一个算法。
2.3.2预备知识
Java中的调用
Java调用主要分为三大类,如下图所示:
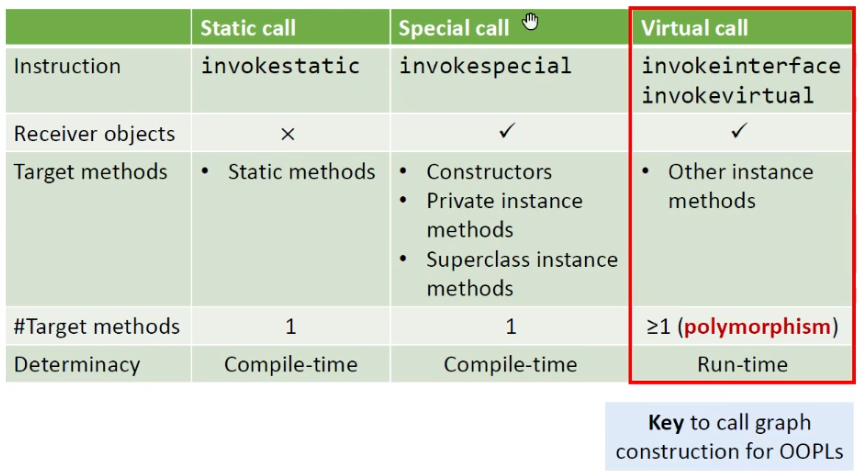
invokestatic调用的目标方法是static methods,就是静态方法。所以它是没有reciever object,目标个数只有一个,在编译期可以确定。
后两种调用的都是instance(实例)方法:
invokespecial调用的方法有构造函数、私有的实例方法以及父类的实例方法,它的目标个数也是只有一个,在编译期可以确定。
invokeinterface和invokevirtual调用其他的方法,因为有多态的存在,所以可能调用不同的方法,因此目标方法可能大于一个,具体调用的方法要在运行时才能确定。
因为前两类相对来说比较简单,所以我们过程间分析的关键是对于第三种Virtual call的分析。
Virtual call中有个关键步骤,叫Method Dispatch。因为Virtual call调用的具体方法是要在程序运行时才能得到,在这一过程中涉及到两个要素:
- reciever object的具体类型:c
- 方法的签名(method signature):m,一个signature可以充当一个方法的identifier.即通过一个signature可以唯一确定一个方法。
- Signature = class type(方法具体所在的类) + method name(方法名) + descriptor
- Descriptor = return type + parameter types
- 可以参考soot工具中采取的格式,如下图所示,红色的是class type,蓝色的是method name,绿色的就是desciptor
![]()

缩写为
求这个方法的过程,我们叫做Method Dispatch。
2.3.3Method Dispatch of Virtual Calls
我们定义了一个函数Dispatch(c,m)以模拟动态Method Dispatch的过程。参数c和m是上面定义里的两个要素(已加粗)。具体过程如下图所示:

如果非抽象方法(因为dispatch要找的是一个具体的能被调用的方法,所以必须是非抽象)里包含一个和m有着相同名字和descriptor的m’,那么就直接返回m’,我们就认为dispatch找到了目标函数。如果c中没有满足条件的方法,那么我们就去c的父类里面找,重复这个过程直到找到为止。
下面是一个利用Method Dispatch的例子:

如图所示,第一个Dispatch是先在B里面找foo方法,然后发现找不到,所以就去B的父类A里面找,找到了,所以第一个Dispatch的结果就是A中的foo方法。第二个Dispatch是先在C里面去找foo方法,在这里因为C自己就有foo方法,所以第一步我们就返回了C中的foo方法。
2.3.4Class Hierarchy Analysis*(CHA)
该方法需要程序中类继承(也就是名字里的Class hierarchy)的信息,也就是需要知道每个类的父类和子类。核心思想就是根据每一个Virtual call的receiver variable的declared type(声明类型)来解目标方法。举例说就是

对于上图a这个变量的declared type就是A,那么CHA就会根据A的方式去算。具体思想就是假设a可以指向A以及它所有子类的对象,因此CHA的实现过程就是查询A的继承结构,从A和子类继承结构去找目标方法。
CHA的具体实现过程
我们定义了一个方法Resolve(cs)以利用CHA算法找到可能的对应call site的目标方法。算法伪代码如下:

首先初始化一个空集合T以装call site的目标方法,然后我们取出调用点cs的签名,接下来对cs的类型进行判定:
-
如果cs是静态调用,那么T就等于对应类中的方法。
-
![]()
-
如果cs是special call,在预备知识中我们知道special call有三种情况(构造函数、私有方法或者父类方法),以父类方法为例:
-
![]()


如图所示,因为C继承了B类,所以C中的父方法就是B中的方法,我们应该先出去方法名的class type,在例子中也就是B类,接下来对cm和m调用Dispatch(因为B中可能并没有foo方法,我们可能还要从B的父类中去找,所以在这里调用了Dispatch()),因为Dispatch返回的目标方法是唯一的,这也就解答了之前为什么说special call目标个数也是唯一的原因。
- 如果cs是virtual call,如下图所示:
![]()

我们会先找出c的声明类型,也就是C,对C本身和C所有子类以及子类的子类等等(在这里我们定义它为c‘)都调用一个Dispatch(c’,m)并将返回值添加到集合T中,最后返回集合T。
一个CHA应用实例
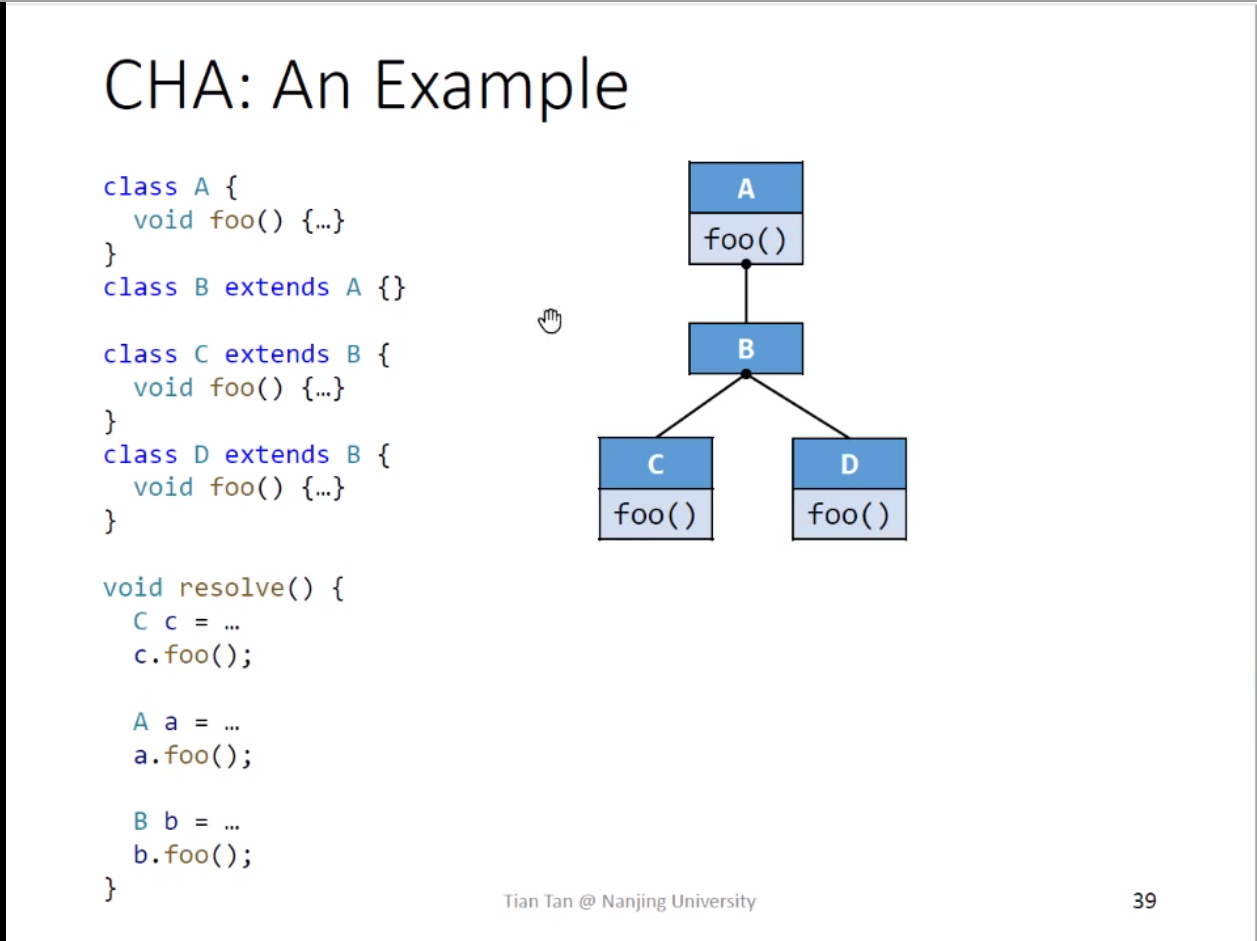
如图所示,c的声明类型是C,而C没有子类,所以Resolve(c.foo()) = {C.foo()}。同理可得Resolve(a.foo()) = {A.foo(),C.foo(),D.foo()},Resolve(b.foo()) = {A.foo(),C.foo(),D.foo()}(这里要注意因为B中没有foo方法,所以要到B的父类A中去找)。
这里也暴露了CHA算法的问题,那就是如果将“B b = ..."替换成”B b = new B()",Resolve(b.foo())还是会得出同样的结果,而事实上C.foo()和D.foo()都是错误的结果。那是因为CHA只考虑声明类型,也就是B,这样就会导致精度的下降。
CHA的特征
优点:快,只需要考虑声明类型,忽略所有数据流和控制流。
缺点:精度差,因为忽略的太多了。
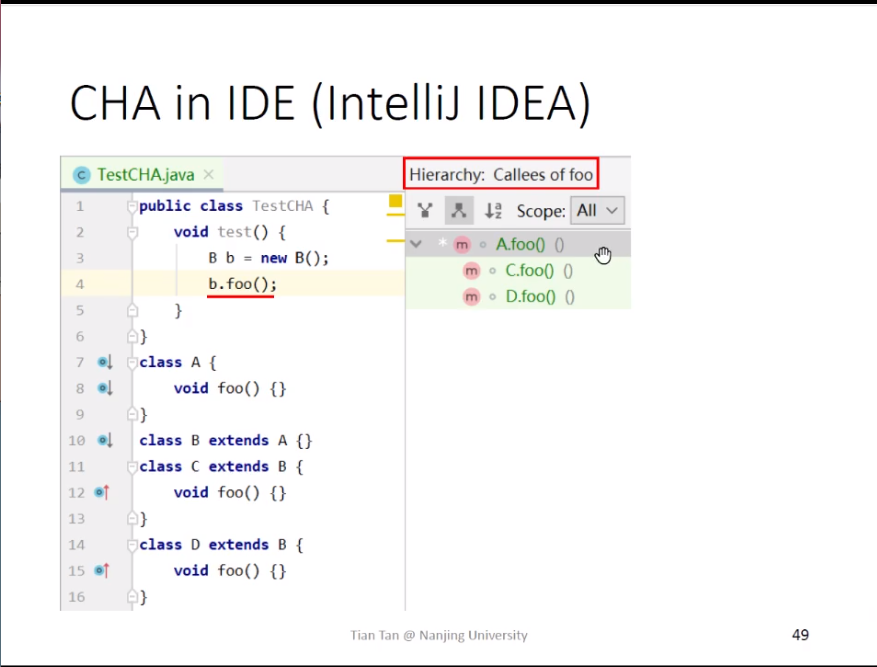
CHA最常用的场景就是IDE中,如下图所示:
2.3.5利用CHA构造调用图
简单步骤:
- 从程序的入口方法开始(如Java里的main方法)构造调用图
- 在构造过程中可以通过调用边达到一些新的方法,每遇到一个可达方法,对他们用CHA的Resolve方法找到目标方法,以此往复,知道找到所有的可达方法,最终得到调用图。
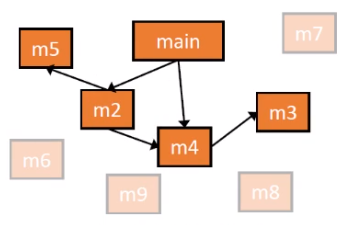
具体算法实现


如上图所示,第一行对算法进行了初始化,先是将入口方法添加到Work List里,然后将CG和RM两个集合清空。整个算法是一个大的while循环,我们不断从WL中取出方法m并将它添加到RM中(代表此方法已经被分析)并对m中的调用点进行分析,利用CHA找到对应的目标方法和调用边,将目标方法添加到WL中,并将它和调用边组成调用图。
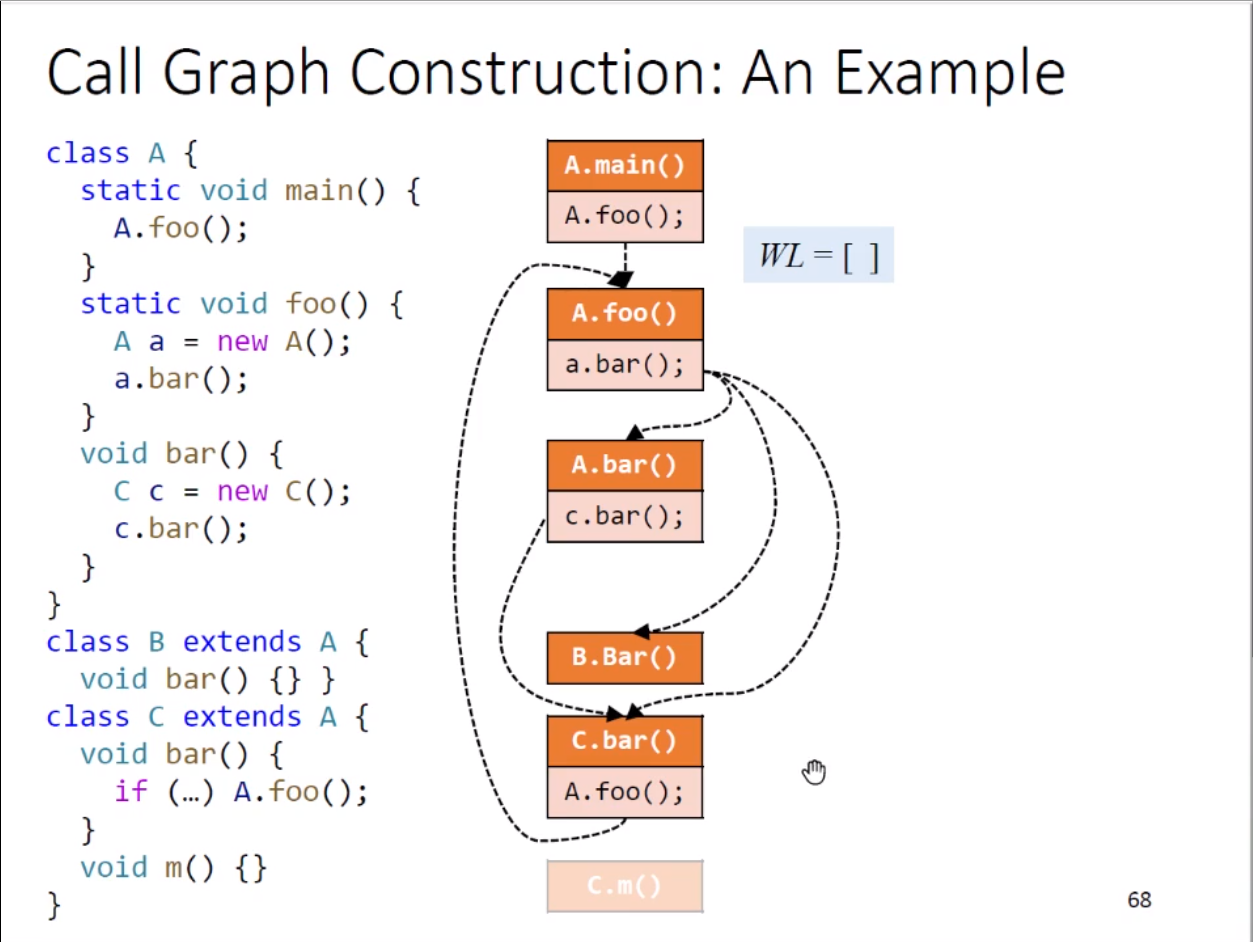
使用实例
3.过程间的控制流图(ICFG)
3.1与CFG区别
- CFG表示的是单个方法的结构
- ICFG表示的是整个程序的结构
- 我们可以用ICFG进行过程间分析
- 一个ICFG是由程序中各个方法自己的CFG再加上两种额外的边(Call edges和Return edges)组成的
- Call edges连结调用点和目标方法的入口
- Return edges从一个return语句连回到紧跟着调用点下面的语句
- Return site一般紧跟着Call site。
一个理解ICFG的例子:
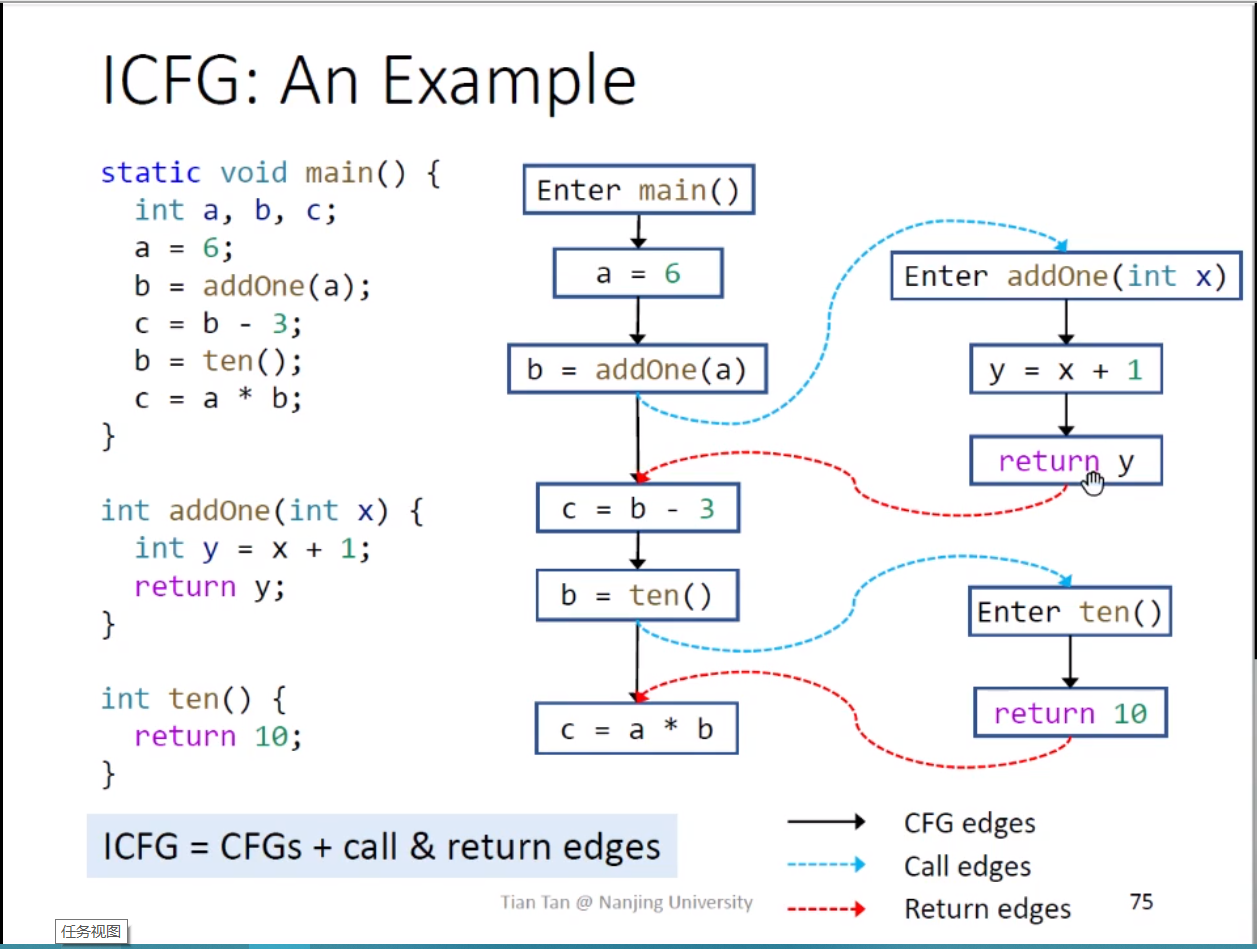
如图所示,三个方法对应了三个CFG,将这三个CFG用Call edges和Return edges连结到一起。
4.过程间的数据流分析
4.1原理
实际上就是对有method call的程序,基于该程序的ICFG对数据流进行分析。

如图所示,相较于过程内的数据流分析,过程间 的数据流分析的转换函数多了一个edge transfer的部分(包含Call edge transfer和Return edge transfer),这也跟前面说的ICFG相较于CFG多的那两种边相对应。
4.2过程间的常量传播数据流分析
对于常量传播来说:
- Call edge transfer:就是用来传参的
- Return edge transfer:就是用来传返回值的
- Node transfer:和过程内大致一样,对每一个方法调用节点,将等号左边部分去掉。
实例分析
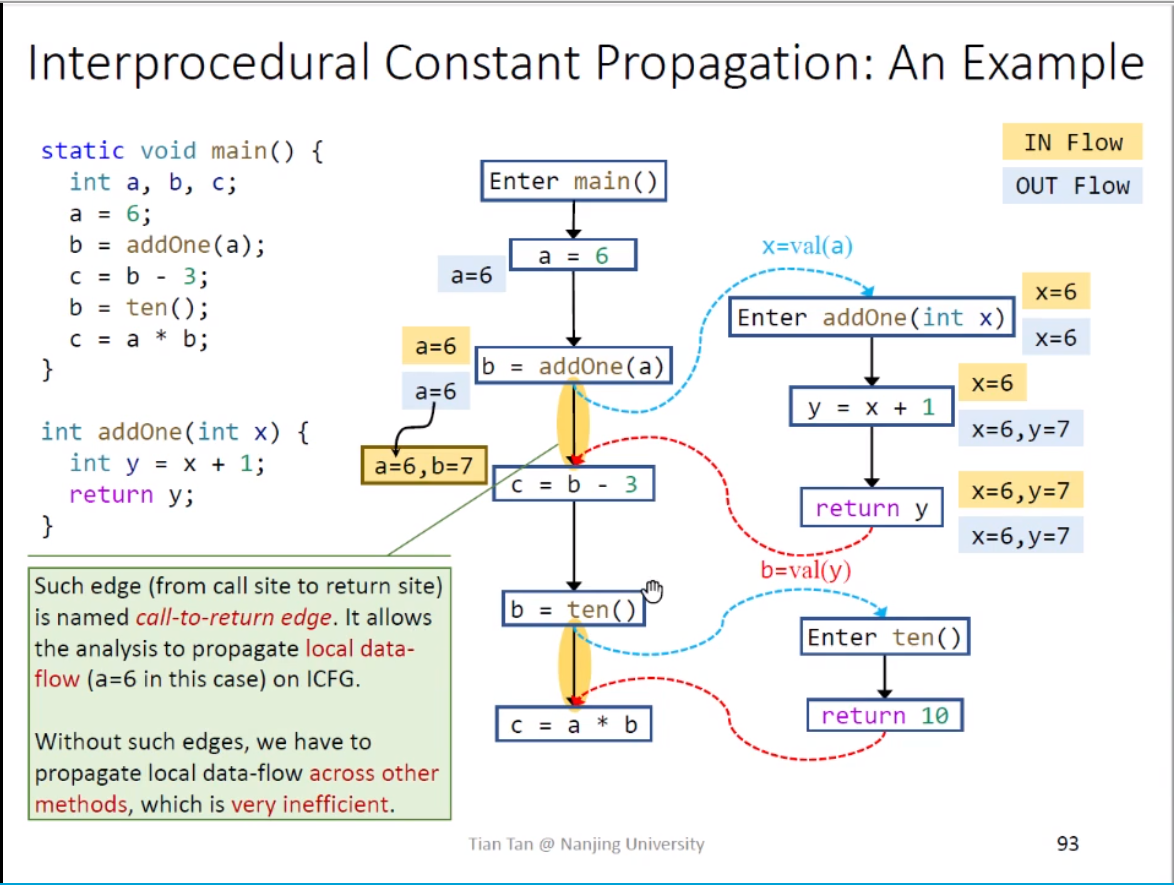
这部分很好理解,唯一需要注意的是图上两条黄色背景的边,这两条边并不是可有可无的,上面说到的node transfer提过对于每一个方法调用节点将等号左边部分去掉,也就是说从“b=addOne(a)"语句到"c=b-3"语句我们是将a的值传递了过去,而b的值由addOne()传递,如果去掉这条边的话就意味着a的值只能通过addOne()传播,而addOne()中对a并没有更改,这样会额外消耗系统资源,另外在第二个黄色边中,如果不去除掉b的值,那么最后一个节点得到的b就为NAC,出现错误,所以我们才会要求去掉等号左边的元素。
5.总结
过程间分析相较于过程内分析的精度更高,因此在实际项目中,我们应该更倾向于使用过程间分析。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号