字符串总结
这里放些字符串相关,总之也就是从头再学字符串了。
基本概念
border:一个字符串的真前缀,并且它和该字符串的一个真后缀相等。
周期:对于字符串
KMP
KMP 是用来求解一个字符串的所有前缀的最长 border 的算法。具体算法流程如下:
我们定义
我们可以结合下面的图来理解:

图中我们发现
代码如下:
ne[1] = 0;
for(int i = 2, j = 0; i <= m; i ++ )
{
while(j && t[i] != t[j + 1]) j = ne[j];
if(t[i] == t[j + 1]) j ++;
ne[i] = j;
}
由于每轮循环
例题后面有。
exKMP(z 函数)
exKMP 和 KMP 相似,但是它是用来求字符串的前缀和该字符串的某个后缀的最长匹配长度。可以想象成这个字符串往后平移,平移到某个位置后从这个字符串开头进行匹配。
在 exKMP 中,我们有一个数组
首先,显然的是
代码如下:
inline void getz(char *s, int n)
{
z[1] = n;
for(int i = 2, l = 0, r = 0; i <= n; i ++ )
{
if(i <= r) z[i] = min(z[i - l + 1], r - i + 1);
while(i + z[i] <= n && s[i + z[i]] == s[z[i] + 1]) z[i] ++;
if(i + z[i] - 1 > r) r = i + z[i] - 1, l = i;
}
}
由于每次 while 循环至少使得
manacher
manacher 算法是用来快速求解字符串中回文串的算法。具体算法流程如下:
我们先对字符串进行预处理,在左右两边加入哨兵,再在每两个字符之间加入一个相同的且在原串中不存在的字符,来使得偶回文串变为奇回文串。我们再设
代码如下:
inline void manacher(char *t)
{
n = strlen(t + 1);
s[0] = '#', s[1] = '$';
for(int i = 1; i <= n; i ++ )
s[i << 1] = t[i], s[i << 1 | 1] = '$';
n = n << 1 | 1;
s[++ n] = ')';
for(int i = 1, mid = 0, r = 0; i <= n; i ++ )
{
f[i] = 1;
if(i <= r) f[i] = min(f[2 * mid - i], r - i + 1);
while(s[i - f[i]] == s[i + f[i]]) f[i] ++;
if(i + f[i] - 1 > r) r = i + f[i] - 1, mid = i;
}
}
时间复杂度分析同 exKMP。
AC 自动机
抽象的世界开始了
AC 自动机和 KMP 类似,都是求解字符串匹配的问题,但是 AC 自动机可以支持多模式串对一个文本串进行匹配,时间复杂度同样也是线性。
AC 自动机一开始可以看作一颗 trie 树。在 AC 自动机中,我们类似 KMP,我们维护一个
对于求
在 AC 自动机中,我们可以对
代码如下:
inline void insert(char *s, int ident)
{
int p = 0;
for(int i = 1; s[i]; i ++ )
{
int t = s[i] - 'a';
if(!tr[p][t]) tr[p][t] = ++ idx;
p = tr[p][t];
}
if(!id[p]) id[p] = ident;
mp[ident] = id[p];
}
inline void build()
{
queue<int> q;
for(int i = 0; i < 26; i ++ )
if(tr[0][i])
q.push(tr[0][i]);
while(q.size())
{
int t = q.front();
q.pop();
for(int i = 0; i < 26; i ++ )
{
int u = tr[t][i];
if(!u) tr[t][i] = tr[fail[t]][i];
else
{
fail[u] = tr[fail[t]][i];
din[fail[u]] ++;
q.push(u);
}
}
}
}
void query(char *s)
{
for(int i = 1, j = 0; s[i]; i ++ )
{
int t = s[i] - 'a';
j = tr[j][t];
val[j] ++;
}
}
代码来源于AC 自动机(二次加强版)。我们可以注意到,在查询出现次数时,我们为了优化复杂度,利用了树上差分的思想,某个点如果出现过,那么它
PAM(回文自动机)
我直接赫过来之前的博客得了
之前博客图挂了,还是自己复习一遍吧
PAM 中有两棵树,分别对应着字符串中的奇回文串和偶回文串。而 PAM 中的
当我们要新加入一个字符时,它可能会和原字符串中的末尾形成一个回文串。由于是回文串,因此两边同时扣掉一个字符依旧是回文串。我们发现这个回文串也就是一个回文后缀。我们直接在这个回文后缀所对应的节点后挂上这个节点即可。这个过程就可以用
建树代码:
inline int getfail(int x, int i)
{
while(i - len[x] < 1 || s[i - len[x] - 1] != s[i]) x = fail[x];
return x;
}
inline void build(int n)
{
len[1] = -1, fail[0] = 1;
idx = 1;
for(int i = 1; i <= n; i ++ )
{
pos = getfail(cur, i);
int u = s[i] - 'a';
if(!tr[pos][u])
{
fail[++ idx] = tr[getfail(fail[pos], i)][u];
tr[pos][u] = idx;
len[idx] = len[pos] + 2;
}
cur = tr[pos][u];
}
}
SA(后缀数组)
SA 是一个把所有后缀都放到一个数组,支持动态查询一个后缀的排名的结构。在其中有两个重要数组:
有一个很简单的构建方法就是把所有后缀都搂出来然后 sort 一下。但是字符串比较是

每次只会对两个关键字进行比较。我们可以简单粗暴用 sort,时间复杂度
构建代码:
m = 127;
for(int i = 1; i <= n; i ++ ) rk[i] = s[i];
for(int i = 1; i <= n; i ++ ) cnt[rk[i]] ++;
for(int i = 1; i <= m; i ++ ) cnt[i] += cnt[i - 1];
for(int i = n; i >= 1; i -- ) sa[cnt[rk[i]] -- ] = i;
memcpy(oldrk + 1, rk + 1, n * sizeof(int));
for(p = 0, i = 1; i <= n; i ++ )
{
if(oldrk[sa[i]] == oldrk[sa[i - 1]])
rk[sa[i]] = p;
else rk[sa[i]] = ++ p;
}
for(w = 1; w < n; w <<= 1)
{
m = p;
for(p = 0, i = n; i > n - w; i -- ) id[++ p] = i;
for(i = 1; i <= n; i ++ )
if(sa[i] > w)
id[++ p] = sa[i] - w;
memset(cnt, 0, sizeof cnt);
for(int i = 1; i <= n; i ++ ) ++ cnt[rk[id[i]]];
for(int i = 1; i <= m; i ++ ) cnt[i] += cnt[i - 1];
for(int i = n; i >= 1; i -- ) sa[cnt[rk[id[i]]] -- ] = id[i];
memcpy(oldrk + 1, rk + 1, n * sizeof(int));
for(p = 0, i = 1; i <= n; i ++ )
{
if(oldrk[sa[i]] == oldrk[sa[i - 1]] && oldrk[sa[i] + w] == oldrk[sa[i - 1] + w])
rk[sa[i]] = p;
else rk[sa[i]] = ++ p;
}
}
我们还可以求出一个数组
对于
SAM(后缀自动机)
我会,以后再写
后缀平衡树
我不会,以后再学习
一些题目
Matching
对于整数序列
-
-
将
现在给出
数据范围:
KMP 好题。我们考虑将判定相等转化一下,可以变为:在它之前比它小的数的个数。这个映射很容易证明是和原来的序列一一对应的。因此我们可以用这个条件来判定相等。我们先预处理出来
时间复杂度
Prefix-Suffix Palindrome
给定一个字符串。要求选取他的一个前缀(可以为空)和与该前缀不相交的一个后缀(可以为空)拼接成回文串,且该回文串长度最大。求该最大长度。
数据范围:
我们考虑如何拼接才是最大的。显然,我们先选取最长逆序相等的前后缀,然后再找一个和这个前后缀相交的回文串即可。如何求这个最长逆序相等的前后缀呢,我们可以把字符串反转后拼到原串后,跑一遍 exKMP,
最长双回文串
输入长度为
数据范围:
我们先对原串跑一遍马拉车,求出每个点所对应的最长回文半径,然后从后往前递推出一个数组
动物园
给定字符串
数据范围:
我们考虑暴力:我们对于每个点暴力跳
因为 border 的 border 也是 border,因此我们可以得到一个结论:
时间复杂度
优秀的拆分
如果一个字符串可以被拆分为
数据范围:
我们考虑将
我们考虑如何求出

我们只需要考虑两个相邻检查点往前的
时间复杂度
所有公共子序列问题
给定两个字符串
数据范围:
本题介绍一种新自动机:子序列自动机。具体的说,给定字符串
它的用处主要有:统计字符串不同子序列个数、查询一个字符串是否是该字符串的子序列、两个字符串的公共子序列、因此本题说是子序列自动机的板子题也可以其实。
回到这题,我们可以同时对两个字符串在两个子序列自动机上走,每次枚举下一个字符填什么,然后走就完事了。统计答案也可以像在 DAG 上统计一样,DP 或者记忆化即可。
残缺的字符串
给定两个字符串 *,表示这个位置可以为任意一个字符。求出对于
数据范围:
这里介绍一个新东西:FFT 求字符串匹配。
先考虑没有通配符的情况,我们将每个位置附一个权值,那么两个字符串
而对于有通配符的情况,我们可以把通配符的权值设置为
展开即为差卷积形式,NTT 即可。
时间复杂度
歌唱王国
给定字符集大小
数据范围:
我们设
根据定义,我们很容易能写出
接下来就是推式子时间:
显然的,
接下来这个式子不是特别显然。我们考虑在没有结束的局面下强行在后面构造出来一个
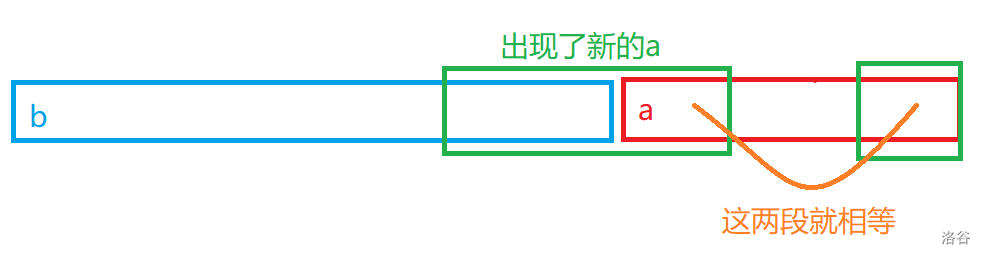
因此我们只需要枚举
我们得到这两个式子后再推推。把上面那个式子两边求导,得到:
我们把
直接


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 【杂谈】分布式事务——高大上的无用知识?