Linux(CentOS)上安装Apache Hadoop
在Linux(CentOS)上安装Apache Hadoop。包括两个部分
-
下载并安装Hadoop
-
配置Hadoop
在安装Hadoop之前有两个先决条件
1、下载并安装Hadoop
1.1、使用以下命令添加Hadoop系统用户
sudo groupadd hadoop_
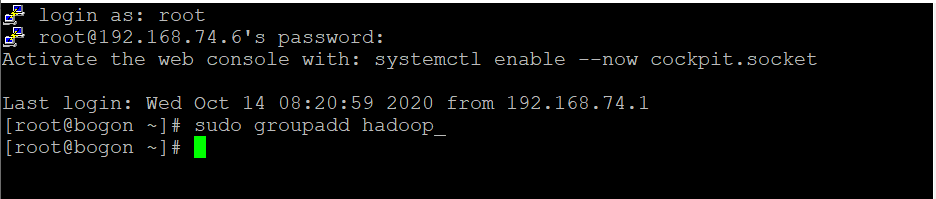
创建hduser_用户并且指定组hadoop_
sudo useradd -G hadoop_ hduser_

设置密码
passwd hduser_

注意:在此设置和安装过程中可能会出现下述错误的解决方法如下
“ hduser is not in the sudoers file.This incident will be reported.”切换到root用户下
su root
2.添加sudo文件的写权限,命令是:
chmod u+w /etc/sudoers
3.编辑sudoers文件
vi /etc/sudoers
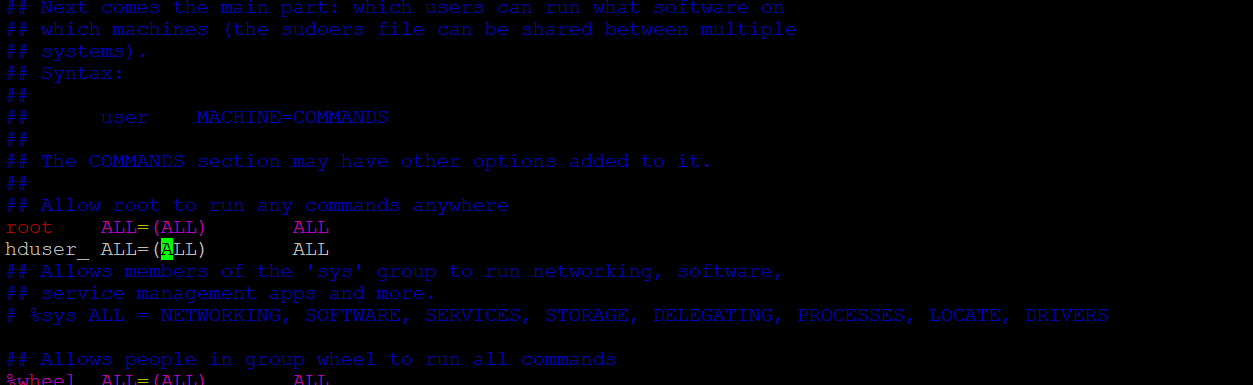
找到这行 root ALL=(ALL) ALL,在他下面添加xxx ALL=(ALL) ALL (这里的xxx是你的用户名)
1.2 配置SSH
为了管理集群中的节点,Hadoop需要SSH访问
首先,切换用户,输入以下命令
su hduser_

用下面的命令将创建一个新密钥。
ssh-keygen -t rsa -P ""

使用此密钥启用对本地计算机的SSH访问。
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys

现在,通过以“ hduser”用户身份连接到localhost来测试SSH设置。
SSH本地主机


选择稳定版本

选择tar.gz文件(而不是带有src的文件)

解压
sudo tar xzf hadoop-2.2.0.tar.gz

现在,将hadoop-2.2.0重命名为hadoop
sudo mv hadoop-2.2.0 hadoop

更改属组
sudo chown -R hduser_:hadoop_ hadoop

2、配置Hadoop
2.1 修改 ~/.bashrc
将以下行添加到文件~/.bashrc末尾
#Set HADOOP_HOME
export HADOOP_HOME=/home/hduser_/hadoop
#Set JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_261-amd64
# Add bin/ directory of Hadoop to PATH
export PATH=$PATH:$HADOOP_HOME/bin

现在,使用以下命令重载次配置
~/.bashrc

2.2 与HDFS相关的配置
在文件 $HADOOP_HOME/etc/hadoop/hadoop-env.sh中设置 JAVA_HOME


用

$HADOOP_HOME/etc/hadoop/core-site.xml 中有两个参数 需要设置-
1. “hadoop.tmp.dir” 用于指定将由Hadoop的用于存储数据文件的目录。
2. 'fs.default.name' 指定默认的文件系统。
要设置这些参数,请打开core-site.xml
sudo vim $HADOOP_HOME/etc/hadoop/core-site.xml
在标签<configuration> </ configuration>之间的行下面复制
<property> <name>hadoop.tmp.dir</name> <value>/app/hadoop/tmp</value> <description>Parent directory for other temporary directories.</description> </property> <property> <name>fs.defaultFS </name> <value>hdfs://localhost:54310</value> <description>The name of the default file system. </description> </property>

导航到目录 $ HADOOP_HOME/etc/Hadoop

现在,创建core-site.xml中提到的目录
sudo mkdir -p /app/hadoop/tmp

授予目录权限
sudo chown -R hduser_:hadoop_ /app/hadoop/tmp

sudo chmod 750 /app/hadoop/tmp

2.3 Map Reduce配置
在开始这些配置之前,让我们设置HADOOP_HOME路径
sudo vim /etc/profile.d/hadoop.sh
然后输入
export HADOOP_HOME=/home/hduser_/hadoop/
接下来输入
sudo chmod +x /etc/profile.d/hadoop.sh

退出终端,然后重新启动
键入
$HADOOP_HOME
验证路径

打开 mapred-site.xml 文件
sudo vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
在标记<configuration>和</ configuration>之间添加以下设置行
<property> <name>mapreduce.jobtracker.address</name> <value>localhost:54311</value> <description>MapReduce job tracker runs at this host and port. </description> </property>

打开 $HADOOP_HOME/etc/hadoop/hdfs-site.xml ,
sudo vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
在标记<configuration>和</ configuration>之间添加以下设置行
<property> <name>dfs.replication</name> <value>1</value> <description>Default block replication.</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hduser_/hdfs</value> </property>

创建以上设置中指定的目录-
sudo mkdir -p /home/hduser_/hdfs

sudo chown -R hduser_:hadoop_ /home/hduser_/hdfs

sudo chmod 750 /home/hduser_/hdfs

2.4 在我们首次启动Hadoop之前,请使用以下命令格式化HDFS
$HADOOP_HOME/bin/hdfs namenode -format

2.5 使用以下命令启动Hadoop单节点集群
$HADOOP_HOME/sbin/start-dfs.sh
上面命令的输出

$HADOOP_HOME/sbin/start-yarn.sh

使用 “ jps” 工具/命令,验证所有与Hadoop相关的进程是否正在运行。

如果Hadoop已成功启动,则jps的输出应显示NameNode,NodeManager,ResourceManager,SecondaryNameNode,DataNode。
2.6 停止Hadoop
$HADOOP_HOME/sbin/stop-dfs.sh

$HADOOP_HOME/sbin/stop-yarn.sh


 浙公网安备 33010602011771号
浙公网安备 33010602011771号