
穷穷穷孩子如何体验ColossalAI SFT(Kaggle篇)
Kaggle Notebook每周会提供30小时的GPU免费使用额度。这为一些想先小小熟悉一下语言模型、但是手里没有资源可用、暂时还不想租用服务器的小伙伴来说,可能带来了一丝安慰。这篇教程以能够运行ColossalAI的“RLHF Training Stage1 - Supervised instructs tuning”部分为主线,附带罗列了安装过程中可能遇到的困难以及解决办法,希望对你有一点帮助。
- 本篇教程对应代码:https://github.com/createmomo/Open-Source-Language-Model-Pocket
- Kaggle:https://www.kaggle.com/
- Colossal AI官方项目:https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat
本文微信公众号(“看个通俗理解吧”)版本(排版阅读更舒服,多配图):
https://mp.weixin.qq.com/s/Q29uSNxvPMy0rC-QxHiGZA
注意:
- 此notebook只演示在kaggle notebook下如何跑通ColossalAI的SFT部分,并不会包含超参数的调整、对结果的分析等
- 类似的操作放到google colab理论上应该也可以跑通
- 如果你有自己的机器,则此notebook对你的帮助可能不大(因为你不需要在notebook上进行训练)
- 此notebook的受众是手里没有GPU资源,但是又想熟悉和浅浅尝试ColossalAI的小伙伴
数据的准备
- 根据官方文档的提示 (https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples),在运行前需要准备好数据
- 数据可以在这里下载 (https://github.com/XueFuzhao/InstructionWild/tree/main/data)。注意不要下载seed文件(因为seed文件只有instruction,而没有response)。要下载README里面提到的json文件,例如instinwild_ch.json。也可以自行准备数据,按照下载的json文件格式准备即可。
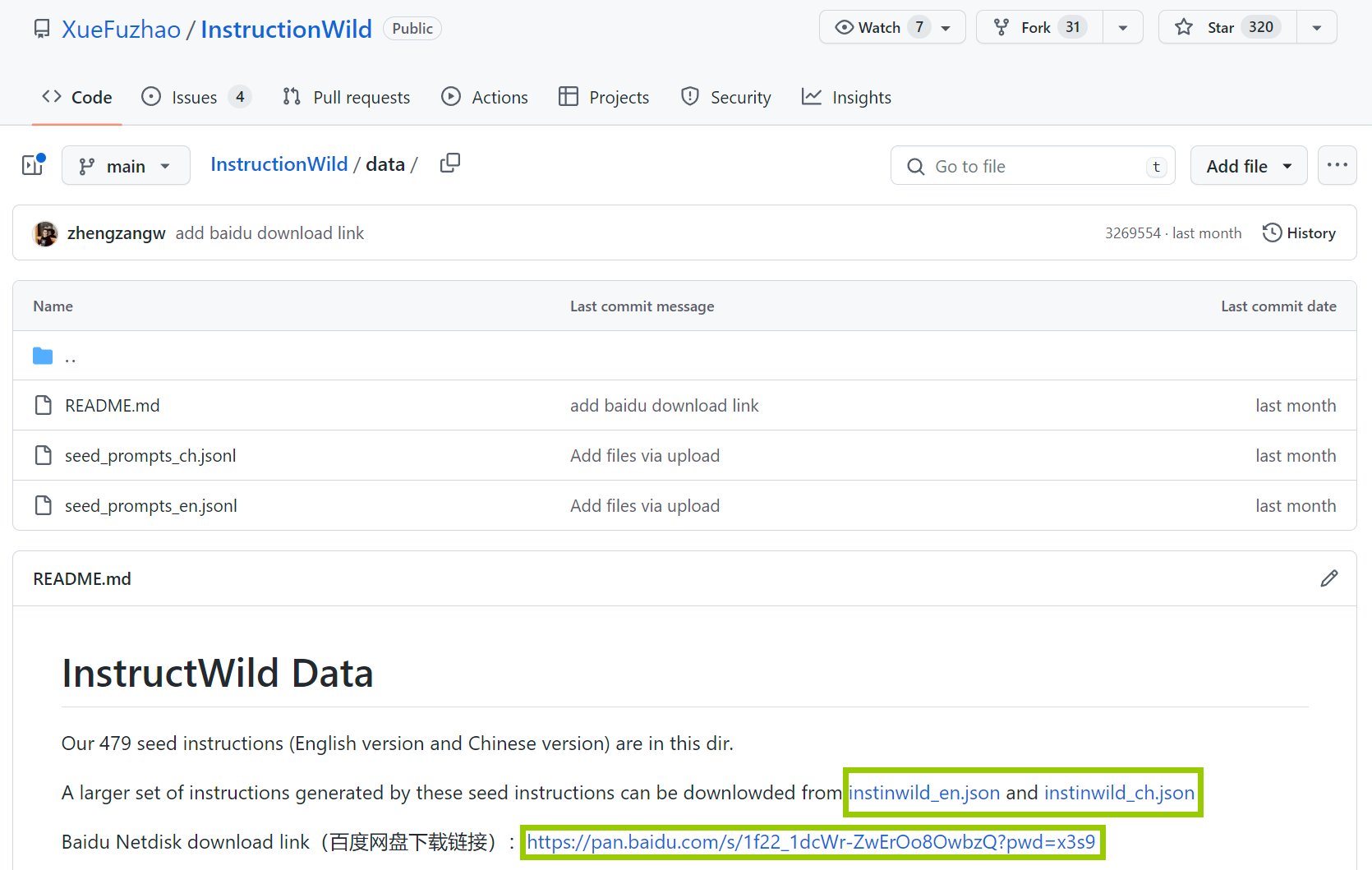
- 将数据上传到Kaggle的Dataset中(需要创建自己的Dataset,可以为仅自己可见),按照Kaggle的步骤操作就可以了
![]()

Kaggle Notebook
-
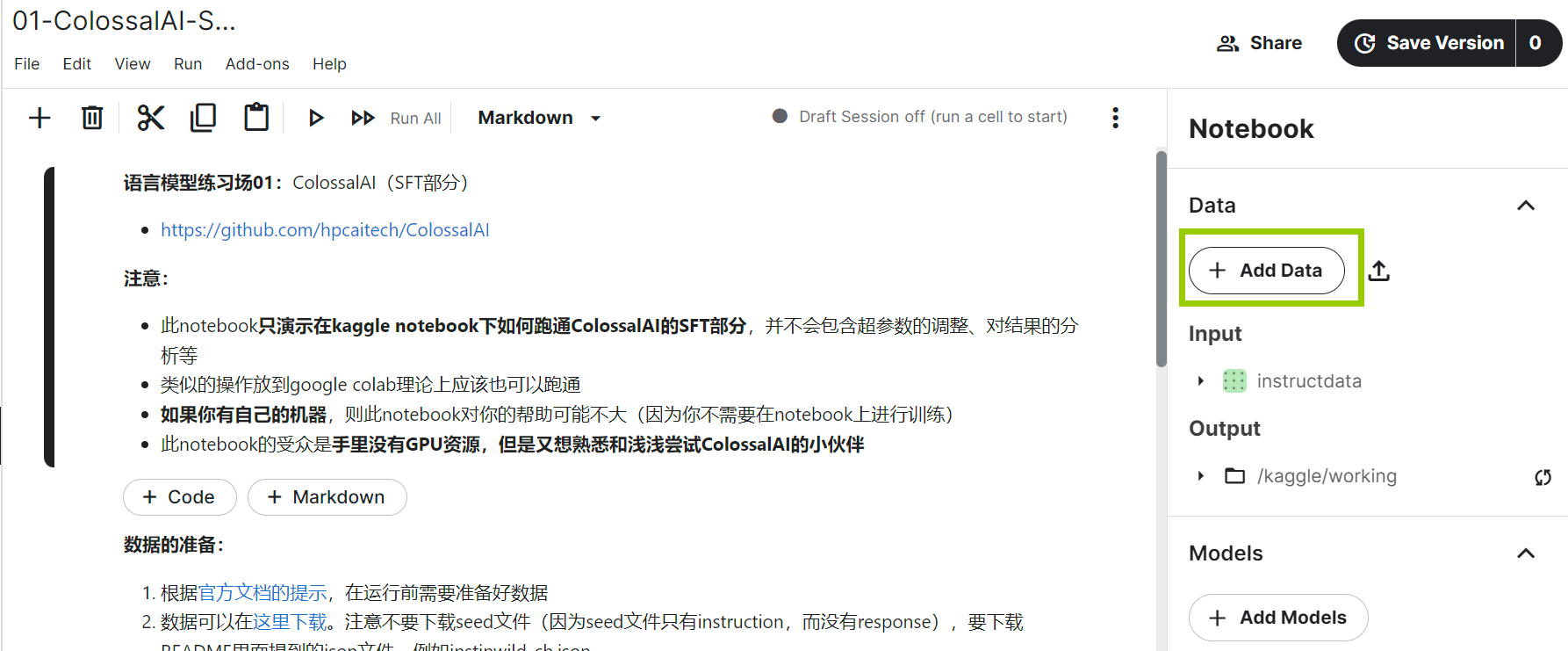
在界面右方添加Dataset,选择自己创建的Dataset。选择后,在代码中可以通过绝对路径访问。比如刚才创建的数据集名字叫做"instructdata",其中我们上传了文件"instinwild_ch_small.json",则在代码中,我们就可以通过这个路径访问数据集: /kaggle/input/instructdata/instinwild_ch_small.json
![]()
-
最好选择GPU T4x2(Kaggle Notebook界面右方的Accelerator中选择)。如果选择P100可能会在安装过程中报错
![]()

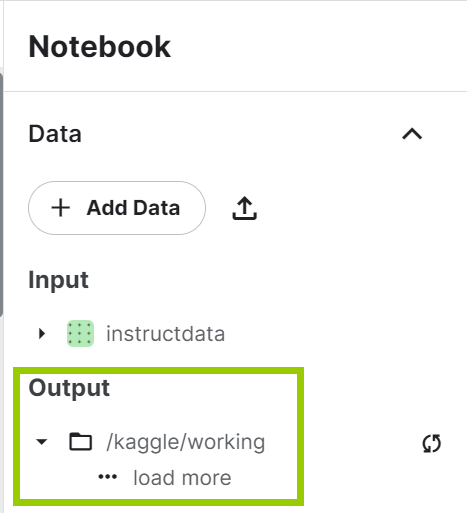
特别要注意的地方:
- 每周有30个小时的GPU使用时间
- 每一次启动notebook最长只能运行12个小时(如果启动了但是不怎么使用,比如没有运行任何cell,也没有什么编辑的动作,可能也会在12个小时以内被强行终止。与google colab不同的时,长时间运行cell是可以的)
- 一旦被终止,则不能再找回输出的数据!(输出的数据会放到/kaggle/working/路径下,如果需要里面的数据,必须在终止运行之前就下载下来)
![]()
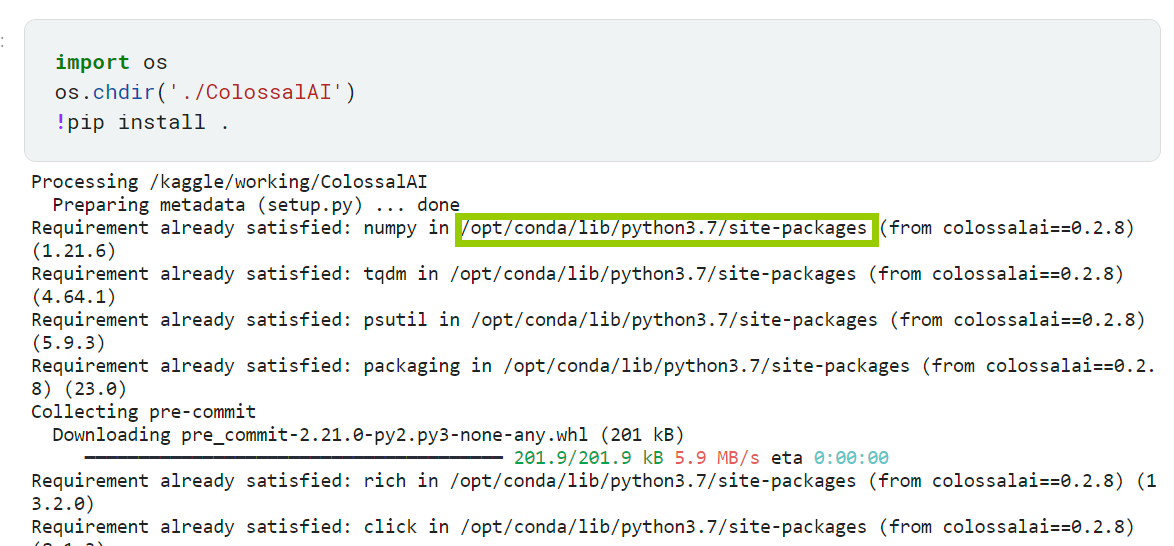
安装环境
大体上是按照官方文档说明安装。但是,如果严格按照文档安装会报错。原因是ColossalAI是一个非常活跃的项目,每日都会有不同的代码变化。文档的部分内容可能还不能及时得到更新。所以,我们针对目前的情况,对安装顺序和细节做了一点微调。
相信在不远的将来,ColossalAI团队会把这些小bug修好,并且把文档逐渐完善起来。
1 ColossalAI
执行完下面的命令后,此时你会发现,下载的文件是放在了/kaggle/working/ColossalAI下
!git clone https://github.com/hpcaitech/ColossalAI.git
安装ColossalAI
如果不执行这个安装,可能会出现错误 (https://github.com/hpcaitech/ColossalAI/issues/3629):"ImportError: cannot import name 'ColoInitContext' from 'colossalai.zero'"
import os
os.chdir('./ColossalAI')
!pip install .
(chdir的作用是变换目前Python的工作目录)
安装transformers
这里我们安装的是hpcaitech下的transformers,如果直接pip install transformers是否可行并没有测试
!git clone https://github.com/hpcaitech/transformers
os.chdir('./transformers')
!pip install .
安装Chat部分需要的库
os.chdir('/kaggle/working/ColossalAI/applications/Chat/')
!pip install .
我们还需要将analyzer的部分复制到当前操作系统的对应的python packages目录中(否则可能将来会报错:找不到analyzer)。如果你问,我怎么知道packages的路径是哪里呢?其实在上面执行各种pip install的过程中,就可以发现这个路径。
!cp -r /kaggle/working/ColossalAI/colossalai/_analyzer/ /opt/conda/lib/python3.7/site-packages/colossalai/
2 预训练模型的下载(以bloom为例)
首先需要执行下面的命令(如果你是在colab中做尝试,可能也需要)
如果不安装下面的命令会出现什么情况呢?
- 从huggingface中git clone下来的模型看似下载下来了,但是其实下载下来的并不是实质的模型文件(如果你检查文件的大小,只有几B)
- 一旦下载下来的文件并不是实质的模型,则在运行SFT代码的时候会报错:safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge
!sudo apt-get install git-lfs
!git lfs install
下载ColossalAI支持的系列模型,我们以bloomz-560m为例。在下面,我们将模型放在了/kaggle/working/中,但是这里并不是强制的,可以根据自己的喜欢变换位置。
os.chdir('/kaggle/working/')
!git clone https://huggingface.co/bigscience/bloomz-560m
3 运行SFT
os.chdir('/kaggle/working/ColossalAI/applications/Chat/examples')
执行SFT代码
我们这里是直接运行的py文件,如果你按照文档的说明 (https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples),运行sh脚本文件(!bash train_sft.sh)也是可以的。其本质上,都是运行这个train_sft.py文件。
在下面的命令中,我们以演示为目的(不以训练为目的):
- 我们只是用一个非常非常非常小的数据集(--dataset)去跑程序(小到就只有5条数据)
- model:改为了"bloom"
- pretrain:改成了我们自己下载的模型地址
- save_path: 改成了我们想放的目录地址
需要注意的是:
- Kaggle Notebook的GPU是T4x2,所以显存大概有14.8+14.8=29.6G。所以我们在运行训练的时候可以设置 --nproc_per_node=2(如果是1的话,则有一块GPU会闲置,显存也会砍半)
- 其他参数可能需要你自己去多多探索:比如lora、gradient checkingpoint等。更多参数的说明见官方文档 (https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples)
!torchrun --standalone --nproc_per_node=2 train_sft.py \
--pretrain "/kaggle/working/bloomz-560m" \
--model 'bloom' \
--strategy colossalai_zero2 \
--log_interval 50 \
--save_path "/kaggle/working/bloomz-560m-finetuned" \
--dataset "/kaggle/input/instructdata/instinwild_ch_small.json" \
--batch_size 4 \
--accumulation_steps 8 \
--lr 2e-5 \
--max_datasets_size 512 \
--max_epochs 1
4 下载SFT完成的模型
os.chdir('/kaggle/working/')
理论上,我们是可以通过Kaggle Notebook右边的界面,选择想要下载的文件进行下载。但是由于Kaggle界面做的并不是很好,经常会出现目录不能显示的问题。好在,你应该是知道训练好的模型是放在了哪里。我们可以找到另一种办法将文件下载下来。
首先,我们把完成的模型进行打包(这样我们就可以一下字全都下载下来了,而不用一个一个的下载)
!tar -czvf bloomz-560m-finetuned.tar.gz bloomz-560m-finetuned
完成打包后,我们想办法获得下载链接。执行下面的命令后,直接点击链接便可下载。
from IPython.display import FileLink
FileLink(r'bloomz-560m-finetuned.tar.gz')
5 小结
跑起来只是一个开始。祝愿每个小伙伴最终都会获得更好的GPU资源、更棒的数据和更出色的属于自己的语言模型!
本篇教程对应代码:https://github.com/createmomo/Open-Source-Language-Model-Pocket

 浙公网安备 33010602011771号
浙公网安备 33010602011771号