
LinkedHashMap
上两篇文章讲了HashMap,HashMap是一种非常常见、非常有用的集合,并且在多线程情况下使用不当会有线程安全问题。
不过HashMap有一个问题,就是迭代HashMap的顺序并不是HashMap放置的顺序,也就是无序。
这个时候,LinkedHashMap就闪亮登场了,它虽然增加了时间和空间上的开销,但是通过维护一个运行于所有条目的双向链表,LinkedHashMap保证了元素迭代的顺序。
四个关注点在LinkedHashMap上的答案
| 关 注 点 | 结 论 |
|---|---|
| LinkedHashMap是否允许键值对为空 | Key和Value都允许空 |
| LinkedHashMap是否允许重复数据 | Key重复会覆盖、Value允许重复 |
| LinkedHashMap是否有序 | 有序 |
| LinkedHashMap是否线程安全 | 非线程安全 |
LinkedHashMap基本数据结构
关于LinkedHashMap,先提两点:
1、LinkedHashMap可以认为是HashMap+LinkedList,即它既使用HashMap操作数据结构,又使用LinkedList维护插入元素的先后顺序
2、LinkedHashMap的基本实现思想就是----多态。可以说,理解多态,再去理解LinkedHashMap原理会事半功倍;反之也是,对于LinkedHashMap原理的学习,也可以促进和加深对于多态的理解
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
...
}
列一下Entry里面有的一些属性吧:
-
K key
-
V value
-
Entry<K, V> next
-
int hash
-
Entry<K, V> before
-
Entry<K, V> after
其中前面四个,也就是红色部分是从HashMap.Entry中继承过来的;后面两个,也就是蓝色部分是LinkedHashMap独有的。不要搞错了next和before、After,next是用于维护HashMap指定table位置上连接的Entry的顺序的,before、After是用于维护Entry插入的先后顺序的。
还是用图表示一下,列一下属性而已:

LinkedHashMap添加元素
继续看LinkedHashMap添加元素,也就是put("111","111")做了什么,首先当然是调用HashMap的put方法:
继续看LinkedHashMap添加元素,也就是put("111","111")做了什么,首先当然是调用HashMap的put方法:
1 public V put(K key, V value) {
2 if (key == null)
3 return putForNullKey(value);
4 int hash = hash(key.hashCode());
5 int i = indexFor(hash, table.length);
6 for (Entry<K,V> e = table[i]; e != null; e = e.next) {
7 Object k;
8 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
9 V oldValue = e.value;
10 e.value = value;
11 e.recordAccess(this);
12 return oldValue;
13 }
14 }
15
16 modCount++;
17 addEntry(hash, key, value, i);
18 return null;
19 }
第17行又是一个多态,因为LinkedHashMap重写了addEntry方法,因此addEntry调用的是LinkedHashMap重写了的方法:
1 void addEntry(int hash, K key, V value, int bucketIndex) {
2 createEntry(hash, key, value, bucketIndex);
3
4 // Remove eldest entry if instructed, else grow capacity if appropriate
5 Entry<K,V> eldest = header.after;
6 if (removeEldestEntry(eldest)) {
7 removeEntryForKey(eldest.key);
8 } else {
9 if (size >= threshold)
10 resize(2 * table.length);
11 }
12 }
因为LinkedHashMap由于其本身维护了插入的先后顺序,因此LinkedHashMap可以用来做缓存,第5行~第7行是用来支持FIFO算法的,这里暂时不用去关心它。看一下createEntry方法:
1 void createEntry(int hash, K key, V value, int bucketIndex) {
2 HashMap.Entry<K,V> old = table[bucketIndex];
3 Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
4 table[bucketIndex] = e;
5 e.addBefore(header);
6 size++;
7 }
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
第2行~第4行的代码和HashMap没有什么不同,新添加的元素放在table[i]上,差别在于LinkedHashMap还做了addBefore操作,这四行代码的意思就是让新的Entry和原链表生成一个双向链表。假设字符串111放在位置table[1]上,生成的Entry地址为0x00000001,那么用图表示是这样的:
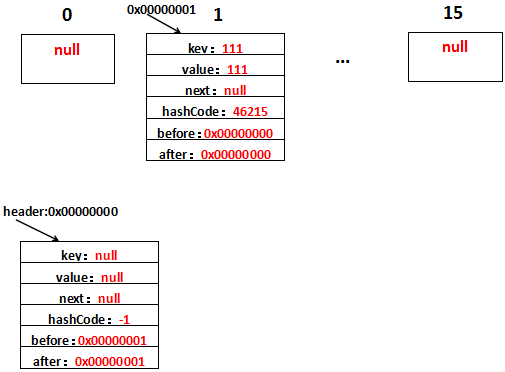
如果熟悉LinkedList的源码应该不难理解,还是解释一下,注意下existingEntry表示的是header:
1、after=existingEntry,即新增的Entry的after=header地址,即after=0x00000000
2、before=existingEntry.before,即新增的Entry的before是header的before的地址,header的before此时是0x00000000,因此新增的Entry的before=0x00000000
3、before.after=this,新增的Entry的before此时为0x00000000即header,header的after=this,即header的after=0x00000001
4、after.before=this,新增的Entry的after此时为0x00000000即header,header的before=this,即header的before=0x00000001
这样,header与新增的Entry的一个双向链表就形成了。再看,新增了字符串222之后是什么样的,假设新增的Entry的地址为0x00000002,生成到table[2]上,用图表示是这样的:
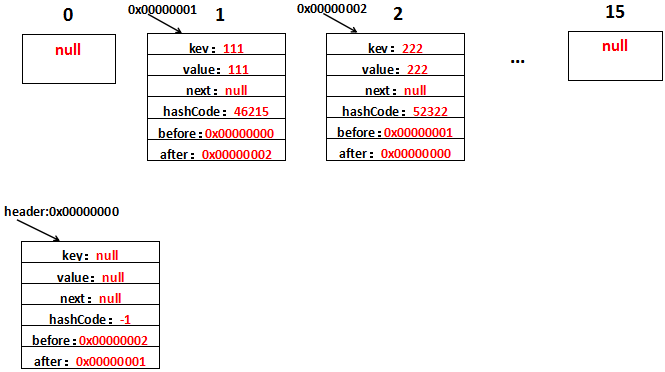
就不细解释了,只要before、after清除地知道代表的是哪个Entry的就不会有什么问题。
总得来看,再说明一遍,LinkedHashMap的实现就是HashMap+LinkedList的实现方式,以HashMap维护数据结构,以LinkList的方式维护数据插入顺序。

