LinkedList
四个关注点在LinkedList上的答案
| 关 注 点 | 结 论 |
|---|---|
| LinkedList是否允许空 | 允许 |
| LinkedList是否允许重复数据 | 允许 |
| LinkedList是否有序 | 有序 |
| LinkedList是否线程安全 | 非线程安全 |
LinkedList是基于链表实现的,那什么是链表呢?链表原先是c/c++的一个概念,是一种线性的存储结构,意思是将存储的数据存储在单元格里面,与数组不同的是,它还带一个存储地址的单元格,值得注意的是 LinkedList是 双向链表,那什么是双向链表呢?和单向链表不同的是,双向链表在存储数据的单元格的两端各带有一个存储地址的单元格,为什么叫链表呢,故名思意,这个结构就像一个链子一样是首尾相接的,可以随意的拆分,如图:
private static class Entry<E> {
E element;
Entry<E> next;
Entry<E> previous;
...
}
![]()
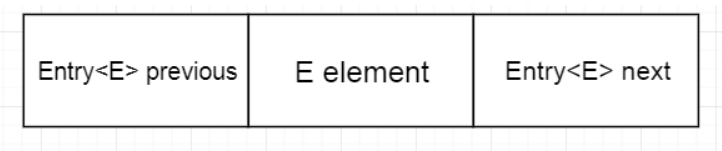
中间的element真正存储数据的单元格,头和尾是用来存储地址的引用值的
添加元素
先来一段代码
1 public static void main(String[] args)
2 {
3 List<String> list = new LinkedList<String>();
4 list.add("111");
5 list.add("222");
6 }
看做了什么:
一共五步,每一步的操作步骤都用数字表示出来了:
1、新的entry的element赋值为111;
2、新的entry的next是header的next,header的next是0x00000000,所以新的entry的next即0x00000000;
3、新的entry的previous是header的previous,header的previous是0x00000000,所以新的entry的next即0x00000000;
4、"newEntry.previous.next = newEntry",首先是newEntry的previous,由于newEntry的previous为0x00000000,所以newEntry.previous表示的是header,header的next为newEntry,即header的next为0x00000001;
5、"newEntry.next.previous = newEntry",和4一样,把header的previous设置为0x00000001;
为什么要这么做?还记得双向链表的两个特点吗,一是任意节点都可以向前和向后寻址,二是整个链表头的previous表示的是链表的尾Entry,链表尾的next表示的是链表的头Entry。现在链表头就是0x00000000这个Entry,链表尾就是0x00000001,可以自己看图观察、思考一下是否符合这两个条件。
最后看一下add了一个字符串"222"做了什么,假设新new出来的Entry的地址是0x00000002,画图表示:
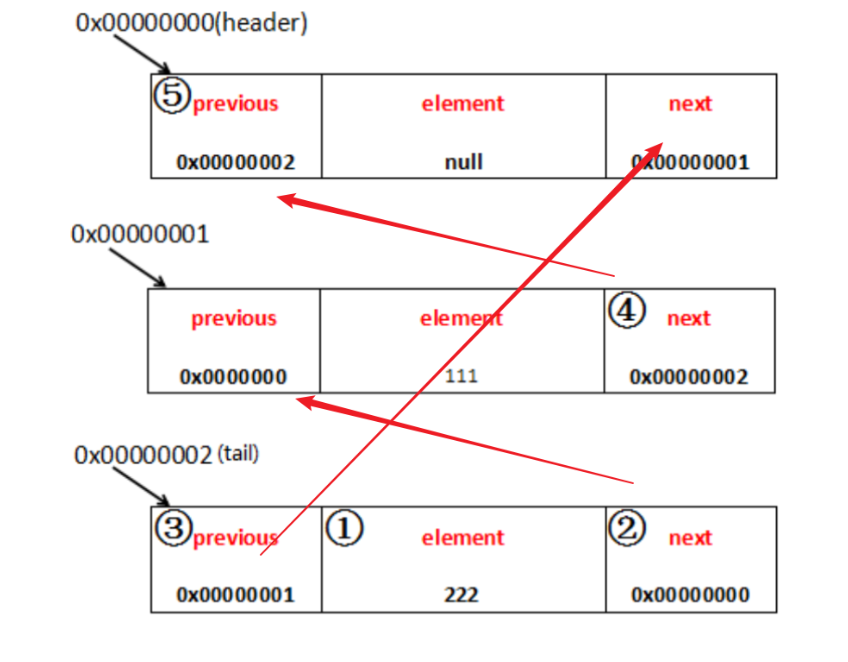
这完全可以解释了问什么双向链表既可以向前查找,有可以向后查找
查看元素
先查一下LinkedList是怎么写的:
public E get(int index) {
return entry(index).element;
}
1 private Entry<E> entry(int index) {
2 if (index < 0 || index >= size)
3 throw new IndexOutOfBoundsException("Index: "+index+
4 ", Size: "+size);
5 Entry<E> e = header;
//索引大于一半后往前查找
6 if (index < (size >> 1)) {
7 for (int i = 0; i <= index; i++)
8 e = e.next;
9 } else {
//否则顺序查找
10 for (int i = size; i > index; i--)
11 e = e.previous;
12 }
13 return e;
14 }
这段代码就体现出了双向链表的好处了。双向链表增加了一点点的空间消耗(每个Entry里面还要维护它的前置Entry的引用),同时也增加了一定的编程复杂度,却大大提升了效率。
由于LinkedList是双向链表,所以LinkedList既可以向前查找,也可以向后查找,第6行~第12行的作用就是:当index小于数组大小的一半的时候(size >> 1表示size / 2,使用移位运算提升代码运行效率),向后查找;否则,向前查找。
这样,在我的数据结构里面有10000个元素,刚巧查找的又是第10000个元素的时候,就不需要从头遍历10000次了,向后遍历即可,一次就能找到我要的元素。
删除元素
先看源码
1 public E remove(int index) {
2 return remove(entry(index));
3 }
1 private E remove(Entry<E> e) {
//先找到位置
2 if (e == header)
3 throw new NoSuchElementException();
4 //在将它置空,利用回收机制回收
5 E result = e.element;
6 e.previous.next = e.next;
7 e.next.previous = e.previous;
8 e.next = e.previous = null;
9 e.element = null;
10 size--;
11 modCount++;
12 return result;
13 }
画个图利于理解:
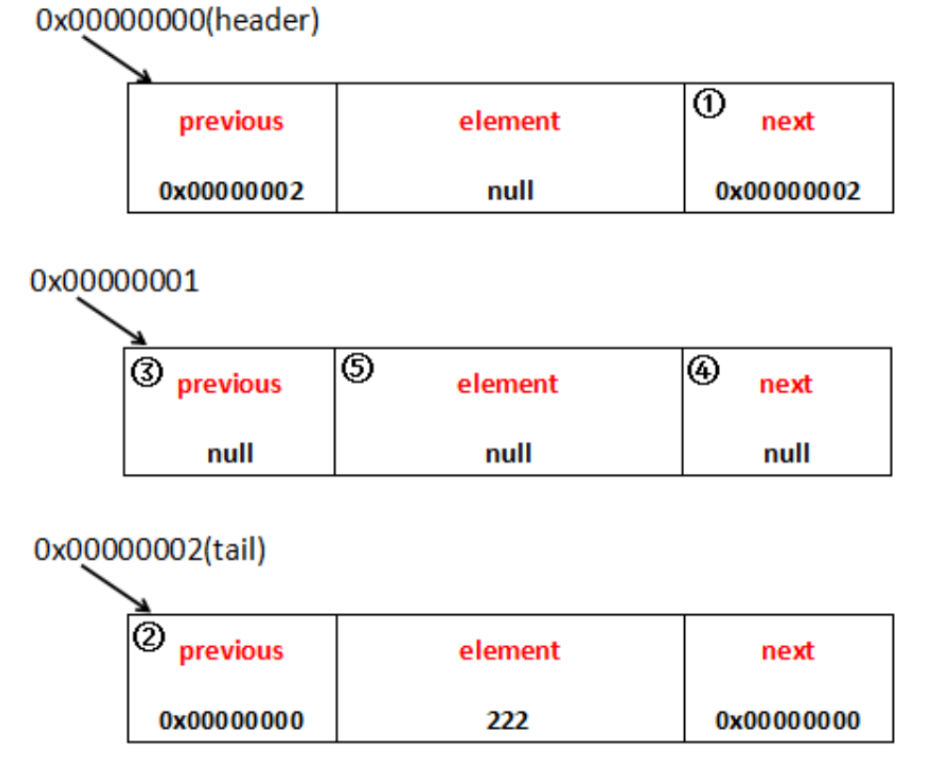
这个问题我稍微扩展深入一点:按照Java虚拟机HotSpot采用的垃圾回收检测算法----根节点搜索算法来说,即使previous、element、next不设置为null也是可以回收这个Entry的,因为此时这个Entry已经没有任何地方会指向它了,tail的previous与header的next都已经变掉了,所以这块Entry会被当做"垃圾"对待。之所以还要将previous、element、next设置为null,我认为可能是为了兼容另外一种垃圾回收检测算法----引用计数法,这种垃圾回收检测算法,只要对象之间存在相互引用,那么这块内存就不会被当作"垃圾"对待。
插入元素
public void add(int index, E element) {
addBefore(element, (index==size ? header : entry(index)));
}
private Entry<E> addBefore(E e, Entry<E> entry) {
Entry<E> newEntry = new Entry<E>(e, entry, entry.previous);
newEntry.previous.next = newEntry;
newEntry.next.previous = newEntry;
size++;
modCount++;
return newEntry;
}
理解了前面的原理,这个应该看的懂了
LinkedList和ArrayList的对比
老生常谈的问题了,这里我尝试以自己的理解尽量说清楚这个问题,顺便在这里就把LinkedList的优缺点也给讲了。
1、顺序插入速度ArrayList会比较快,因为ArrayList是基于数组实现的,数组是事先new好的,只要往指定位置塞一个数据就好了;LinkedList则不同,每次顺序插入的时候LinkedList将new一个对象出来,如果对象比较大,那么new的时间势必会长一点,再加上一些引用赋值的操作,所以顺序插入LinkedList必然慢于ArrayList
2、基于上一点,因为LinkedList里面不仅维护了待插入的元素,还维护了Entry的前置Entry和后继Entry,如果一个LinkedList中的Entry非常多,那么LinkedList将比ArrayList更耗费一些内存
3、数据遍历的速度,看最后一部分,这里就不细讲了,结论是:使用各自遍历效率最高的方式,ArrayList的遍历效率会比LinkedList的遍历效率高一些
4、有些说法认为LinkedList做插入和删除更快,这种说法其实是不准确的:
(1)LinkedList做插入、删除的时候,慢在寻址,快在只需要改变前后Entry的引用地址
(2)ArrayList做插入、删除的时候,慢在数组元素的批量copy,快在寻址
所以,如果待插入、删除的元素是在数据结构的前半段尤其是非常靠前的位置的时候,LinkedList的效率将大大快过ArrayList,因为ArrayList将批量copy大量的元素;越往后,对于LinkedList来说,因为它是双向链表,所以在第2个元素后面插入一个数据和在倒数第2个元素后面插入一个元素在效率上基本没有差别,但是ArrayList由于要批量copy的元素越来越少,操作速度必然追上乃至超过LinkedList。
从这个分析看出,如果你十分确定你插入、删除的元素是在前半段,那么就使用LinkedList;如果你十分确定你删除、删除的元素在比较靠后的位置,那么可以考虑使用ArrayList。如果你不能确定你要做的插入、删除是在哪儿呢?那还是建议你使用LinkedList吧,因为一来LinkedList整体插入、删除的执行效率比较稳定,没有ArrayList这种越往后越快的情况;二来插入元素的时候,弄得不好ArrayList就要进行一次扩容,记住,ArrayList底层数组扩容是一个既消耗时间又消耗空间的操作
遍历
ArrayList使用最普通的for循环遍历,LinkedList使用foreach循环比较快,主要是因为ArrayList是实现了RandomAccess接口而LinkedList则没有实现这个接口


 浙公网安备 33010602011771号
浙公网安备 33010602011771号