

10.31
实验三:C4.5算法实现与测试
一、实验目的
深入理解决策树、预剪枝和后剪枝的算法原理,能够使用 Python 语言实现带有预剪枝和后剪枝的决策树算法 C4.5 算法的训练与测试,并且使用五折交叉验证算法进行模型训练与评估。
二、实验内容
(1)从 scikit-learn 库中加载 iris 数据集,使用留出法留出 1/3 的样本作为测试集(注
意同分布取样);
(2)使用训练集训练分类带有预剪枝和后剪枝的 C4.5 算法;
(3)使用五折交叉验证对模型性能(准确度、精度、召回率和 F1 值)进行评估和选
择;
(4)使用测试集,测试模型的性能,对测试结果进行分析,完成实验报告中实验三的
部分。
三、算法步骤、代码、及结果
1. 算法伪代码
函数 C4.5(数据集 D):
如果 D 中所有样本属于同一类:
返回该类标签
如果 D 中没有特征可用于划分:
返回 D 中样本数最多的类标签
选择最佳特征 F:
1. 对每个特征 F 计算信息增益比 (Gain Ratio)
2. 选择信息增益比最大的特征 F
创建一个节点 N,标签为特征 F
对于特征 F 的每个可能取值 v:
将数据集 D 按照特征 F 的取值 v 分成子集 D_v
对于子集 D_v:
如果 D_v 非空:
调用 C4.5(D_v) 创建子树,并将其作为节点 N 的子节点
否则:
将该子节点标记为 D 中最多样本类标签
返回节点 N
2. 算法主要代码
完整源代码\调用库方法(函数参数说明)

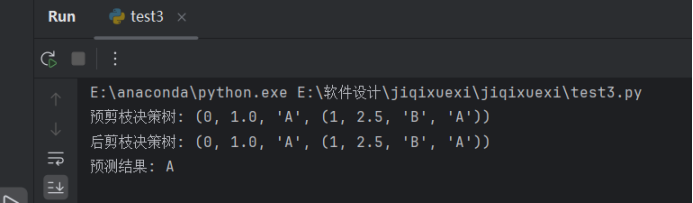
import numpy as np from collections import Counter # 计算信息熵 def entropy(data): labels = [item[-1] for item in data] label_counts = Counter(labels) total = len(data) return -sum((count / total) * np.log2(count / total) for count in label_counts.values()) # 根据特征选择最佳划分 def best_split(data): base_entropy = entropy(data) best_gain = 0 best_split_column = None best_split_value = None n_features = len(data[0]) - 1 for col in range(n_features): values = set([row[col] for row in data]) for value in values: left = [row for row in data if row[col] <= value] right = [row for row in data if row[col] > value] if len(left) == 0 or len(right) == 0: continue new_entropy = (len(left) / len(data)) * entropy(left) + (len(right) / len(data)) * entropy(right) info_gain = base_entropy - new_entropy if info_gain > best_gain: best_gain = info_gain best_split_column = col best_split_value = value return best_split_column, best_split_value # 构建决策树(带预剪枝) def build_tree(data, min_samples_split=2, max_depth=float('inf'), depth=0): # 终止条件 if len(data) < min_samples_split or depth >= max_depth: return Counter([row[-1] for row in data]).most_common(1)[0][0] col, value = best_split(data) if col is None: return Counter([row[-1] for row in data]).most_common(1)[0][0] left = [row for row in data if row[col] <= value] right = [row for row in data if row[col] > value] left_tree = build_tree(left, min_samples_split, max_depth, depth + 1) right_tree = build_tree(right, min_samples_split, max_depth, depth + 1) return (col, value, left_tree, right_tree) # 用决策树预测结果 def predict(tree, row): if not isinstance(tree, tuple): return tree col, value, left_tree, right_tree = tree if row[col] <= value: return predict(left_tree, row) else: return predict(right_tree, row) # 后剪枝方法 def prune_tree(tree, validation_data): if isinstance(tree, tuple): col, value, left_tree, right_tree = tree # 递归剪枝 left_tree = prune_tree(left_tree, validation_data) right_tree = prune_tree(right_tree, validation_data) # 计算剪枝前后的误差 error_before = sum(1 for row in validation_data if predict(tree, row) != row[-1]) error_after_left = sum(1 for row in validation_data if predict(left_tree, row) != row[-1]) error_after_right = sum(1 for row in validation_data if predict(right_tree, row) != row[-1]) # 如果剪枝后误差更小,则剪枝 if error_after_left + error_after_right < error_before: return Counter([row[-1] for row in validation_data]).most_common(1)[0][0] return (col, value, left_tree, right_tree) return tree # 构建决策树(后剪枝) def build_and_prune_tree(data, validation_data, min_samples_split=2, max_depth=float('inf'), depth=0): tree = build_tree(data, min_samples_split, max_depth, depth) pruned_tree = prune_tree(tree, validation_data) return pruned_tree # 示例数据 train_data = [ [2.0, 3.0, 'A'], [1.0, 1.0, 'A'], [1.5, 1.5, 'B'], [3.0, 4.0, 'B'], [3.5, 3.5, 'A'], [2.5, 2.5, 'B'] ] validation_data = [ [2.0, 3.0, 'A'], [2.5, 2.5, 'B'] ] # 使用预剪枝构建树 tree_pre_pruned = build_tree(train_data, min_samples_split=2, max_depth=2) print("预剪枝决策树:", tree_pre_pruned) # 使用后剪枝构建树 tree_post_pruned = build_and_prune_tree(train_data, validation_data, min_samples_split=2, max_depth=2) print("后剪枝决策树:", tree_post_pruned) # 使用树进行预测 prediction = predict(tree_post_pruned, [2.0, 3.0]) print("预测结果:", prediction)
3. 训练结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!