数据库的设计学习
一. 学习Chorme的数据设计
工作的时候发现, Chrome的历史记录保存在文件:
%AppData%\Local\Google\Chrome\User Data\Profile 1\History, 它是一个SQLite数据库文件.
visits表中,记录了每次的历史记录, 如下:
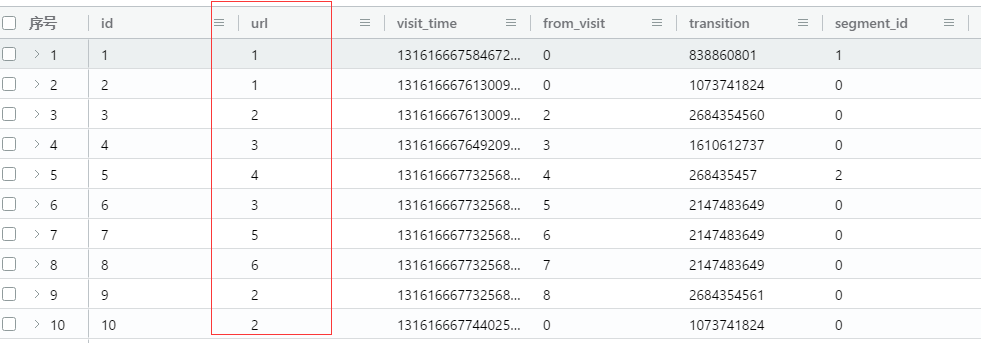
urls表中,每个url都是不重复的, 是唯一的主键, 并且它的visit_count字段记录了每个url全部访问次数.

给我的启发:
- 尽量Chrome直接写入每次的历史记录, 但是它没有那么做, 而是把每个url作为唯一的主键, 有效降低了url过多带来的存储空间浪费.
- 通过
urls和visits不同的联结机制, 实现了更快的查询.
猜测Chrome是如何做的
Case A: 当用户新增一条历史记录时:
- 更新
urls表, 如果主键已存在, 则只需更新visit_count字段和last_visit_time字段. 如果主键不存在, 则创建新的记录 - 更新
visti表, 新增一条记录, url字段填入urls表的主键.
Case B: 当用户查询全部的历史记录时:
visits左联结urls:
SELECT u.url, u.title, v.visit_time, u.visit_count
FROM visits v LEFT JOIN urls u on v.url=u.id
Case C: 当用户查询特定的历史记录时, 比如title包含'你就知道'这个字符串:
SELECT u.url, u.title, v.visit_time, u.visit_count
FROM visits v LEFT JOIN urls u on v.url=u.id
WHERE u.title LIKE '%你就知道%'
有个问题, 这种情况使用子查询语句应该更快吗? 对于数据比较多的情况, 比如先从urls表获取到相应的id, 然后基于这个id去查询visits表. 应该会避免了过多的字符串匹配.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号