
为数据节点添加新硬盘
- 挂载硬盘到指定文件夹。如`/dfs_diskb`;
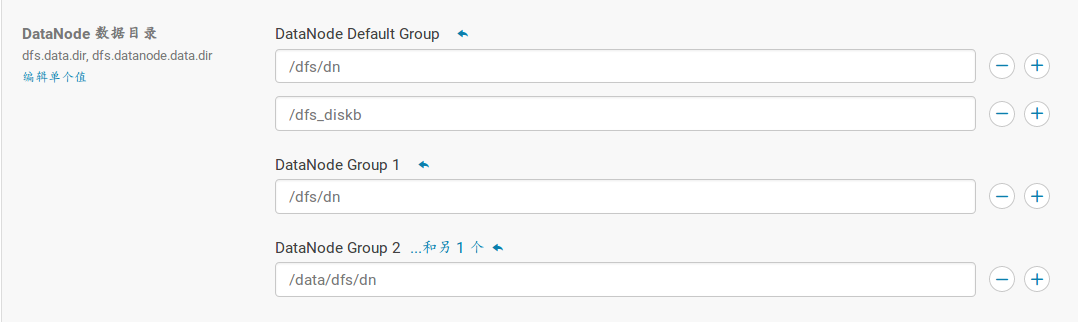
- 打开cloudera manager -> hdfs -> 配置 -> DataNode -> DataNode Default Group,添加新硬盘所挂载的目录,注意节点所在群;
- 重启hdfs服务。
hdfs数据平衡
在主节点(其它节点未测试)执行命令:sudo -u hdfs hdfs balancer。
集群时钟同步
- ntp服务端和外网同步:`sudo /etc/init.d/ntp restart`
- 客户端与内网ntp服务器同步`sudo ntpdate ntp_server_ip`
hive表在生成过程中产生过多的小文件导致chd报警,Concerning : The DataNode has 814,837 blocks. Warning threshold: 500,000 block(s).
- 通过命令`hadoop fsck /user/hive/warehouse/db_name`查询后发现该数据块下平均文件块仅仅为5kb,远远小于128m。
- 设置参数似的hive在存储sql执行后对执行结果中的大小较小的文件进行合并
```
hive.merge.mapfiles 在map-only job后合并文件,默认true
hive.merge.mapredfiles 在map-reduce job后合并文件,默认false
hive.merge.size.per.task 合并后每个文件的大小,默认256000000
hive.merge.smallfiles.avgsize 平均文件大小,是决定是否执行合并操作的阈值,默认16000000
```
修改hive的配置参数
<name>mapred.max.split.size</name><value>512000000</value></property><property><name>hive.merge.mapredfiles</name><value>true</value></property><property><name>hive.exec.compress.output</name><value>true</value></property><property><name>mapred.min.split.size.per.node</name><value>100000000</value></property><property><name>hive.merge.smallfiles.avgsize</name><value>64000000 </value></property>
对于输出文件是压缩文件的,需要将表的存储格式修改为SEQUENCEFILE
NFS Gateway服务启动失败
原因:节点已经启动了nfs服务,需要关闭
命令:sudo service nfs-kernel-server stop
重启该服务,成功上线
host monitor与agent失去连接
造成该问题的原因是在root权限下启动了cloudera manager服务。可以关闭当前的cloudera manager服务,然后在非root用户下来启动cloudera manager的angent和service服务,问题解决。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号