Netty ByteBuf(图解之 2)| 秒懂
文章很长,而且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《尼恩Java面试宝典 最新版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
Netty ByteBuf(图解二):API 图解
疯狂创客圈 Java 分布式聊天室【 亿级流量】实战系列之16 【 博客园 总入口 】
源码工程
源码IDEA工程获取链接:Java 聊天室 实战 源码
写在前面
大家好,我是作者尼恩。
今天是百万级流量 Netty 聊天器 打造的系列文章的第16篇,这是一个基础篇,介绍ByteBuf 的使用。
由于关于ByteBuf的内容比较多,分两篇文章:
第一篇:图解 ByteBuf的分配、释放和如何避免内存泄露
第二篇:图解 ByteBuf的具体使用
本篇为第二篇。
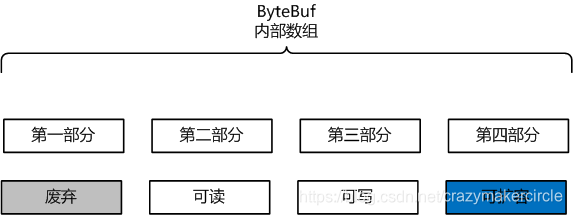
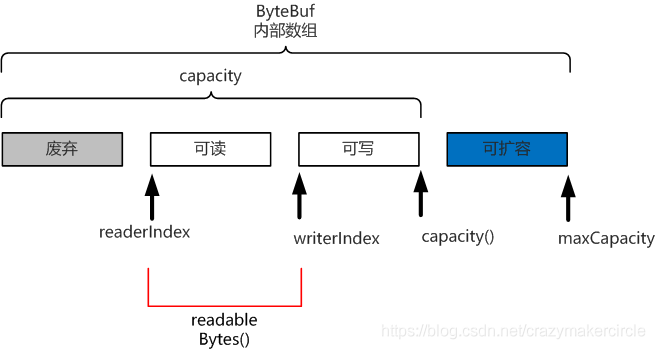
ByteBuf 的四个逻辑部分
ByteBuf 是一个字节容器,内部是一个字节数组。
从逻辑上来分,字节容器内部,可以分为四个部分:

第一个部分是已经丢弃的字节,这部分数据是无效的;
第二部分是可读字节,这部分数据是 ByteBuf 的主体数据, 从 ByteBuf 里面读取的数据都来自这一部分;
第三部分的数据是可写字节,所有写到 ByteBuf 的数据都会写到这一段。
第四部分的字节,表示的是该 ByteBuf 最多还能扩容的大小。
四个部分的逻辑功能,如下图所示:
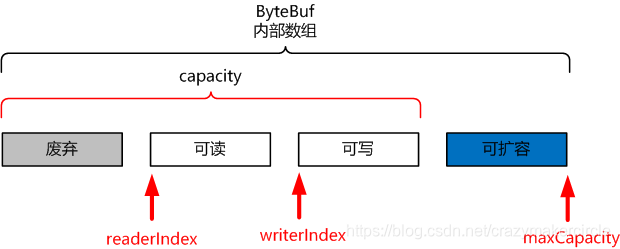
ByteBuf 的三个指针
ByteBuf 通过三个整型的指针(index),有效地区分可读数据和可写数据,使得读写之间相互没有冲突。
这个三个指针,分别是:
- readerIndex(读指针)
- writerIndex(写指针)
- maxCapacity(最大容量)
这三个指针,是三个int 型的成员属性,定义在 AbstractByteBuf 抽象基类中。
三个指针的代码截图,如下:
readerIndex 读指针
指示读取的起始位置。
每读取一个字节,readerIndex 自增1 。一旦 readerIndex 与 writerIndex 相等,ByteBuf 不可读 。
writerIndex 写指针
指示写入的起始位置。
每写一个字节,writerIndex 自增1。一旦增加到 writerIndex 与 capacity() 容量相等,表示 ByteBuf 已经不可写了 。
capacity()容量不是一个成员属性,是一个成员方法。表示 ByteBuf 内部的总容量。 注意,这个不是最大容量。
maxCapacity 最大容量
指示可以 ByteBuf 扩容的最大容量。
当向 ByteBuf 写数据的时候,如果容量不足,可以进行扩容。
扩容的最大限度,直到 capacity() 扩容到 maxCapacity为止,超过 maxCapacity 就会报错。
capacity()扩容的操作,是底层自动进行的。
ByteBuf 的三组方法
从三个维度三大系列,介绍ByteBuf 的常用 API 方法。

第一组:容量系列
-
方法 一:capacity()
表示 ByteBuf 的容量,包括丢弃的字节数、可读字节数、可写字节数。
-
方法二:maxCapacity()
表示 ByteBuf 底层最大能够占用的最大字节数。当向 ByteBuf 中写数据的时候,如果发现容量不足,则进行扩容,直到扩容到 maxCapacity。
第二组:写入系列
-
方法一:isWritable()
表示 ByteBuf 是否可写。如果 capacity() 容量大于 writerIndex 指针的位置 ,则表示可写。否则为不可写。
isWritable()的源码,也是很简单的。具体如下:
public boolean isWritable() {
return this.capacity() > this.writerIndex;
}
注意:如果 isWritable() 返回 false,并不代表不能往 ByteBuf 中写数据了。 如果Netty发现往 ByteBuf 中写数据写不进去的话,会自动扩容 ByteBuf。
-
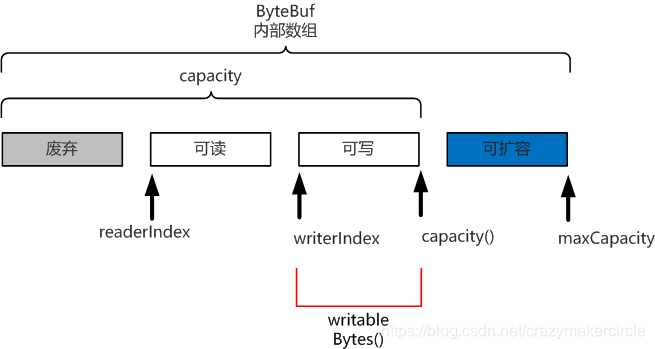
方法二:writableBytes()
返回表示 ByteBuf 当前可写入的字节数,它的值等于 capacity()- writerIndex。
如下图所示:
-
方法三:maxWritableBytes()
返回可写的最大字节数,它的值等于 maxCapacity-writerIndex 。
-
方法四:**writeBytes(byte[] src) **
把字节数组 src 里面的数据全部写到 ByteBuf。
这个是最为常用的一个方法。
-
方法五:writeTYPE(TYPE value) 基础类型写入方法
基础数据类型的写入,包含了 8大基础类型的写入。
具体如下:writeByte()、 writeBoolean()、writeChar()、writeShort()、writeInt()、writeLong()、writeFloat()、writeDouble() ,向 ByteBuf写入基础类型的数据。
-
方法六:setTYPE(TYPE value)基础类型写入,不改变指针值
基础数据类型的写入,包含了 8大基础类型的写入。
具体如下:setByte()、 setBoolean()、setChar()、setShort()、setInt()、setLong()、setFloat()、setDouble() ,向 ByteBuf 写入基础类型的数据。
setType 系列与writeTYPE系列的不同:
setType 系列 不会 改变写指针 writerIndex ;
writeTYPE系列 会 改变写指针 writerIndex 的值。
-
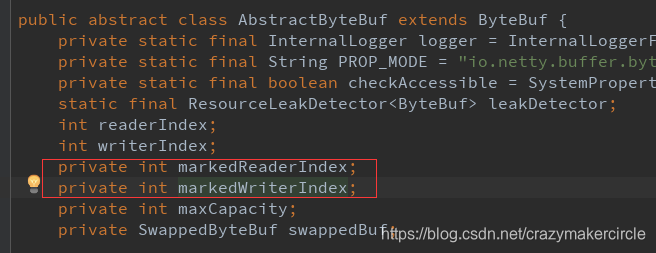
方法七:markWriterIndex() 与 resetWriterIndex()
这里两个方法一起介绍。
前一个方法,表示把当前的写指针writerIndex 保存在 markedWriterIndex 属性中;
后一个方法,表示把当前的写指针 writerIndex 恢复到之前保存的 markedWriterIndex 值 。
标记 markedWriterIndex 属性, 定义在 AbstractByteBuf 抽象基类中。
截图如下:
第三组:读取系列
-
方法一:isReadable()
表示 ByteBuf 是否可读。如果 writerIndex 指针的值大于 readerIndex 指针的值 ,则表示可读。否则为不可写。
isReadable()的源码,也是很简单的。具体如下:
public boolean isReadable() {
return this.writerIndex > this.readerIndex;
}
-
方法二:readableBytes()
返回表示 ByteBuf 当前可读取的字节数,它的值等于 writerIndex - readerIndex 。
如下图所示:
-
方法三: readBytes(byte[] dst)
把 ByteBuf 里面的数据全部读取到 dst 字节数组中,这里 dst 字节数组的大小通常等于 readableBytes() 。 这个方法,也是最为常用的一个方法。
-
方法四:readType() 基础类型读取
基础数据类型的读取,可以读取 8大基础类型。
具体如下:readByte()、readBoolean()、readChar()、readShort()、readInt()、readLong()、readFloat()、readDouble() ,从 ByteBuf读取对应的基础类型的数据。
-
方法五:getTYPE(TYPE value)基础类型读取,不改变指针值
基础数据类型的读取,可以读取 8大基础类型。
具体如下:getByte()、 getBoolean()、getChar()、getShort()、getInt()、getLong()、getFloat()、getDouble() ,从 ByteBuf读取对应的基础类型的数据。
getType 系列与readTYPE系列的不同:
getType 系列 不会 改变读指针 readerIndex ;
readTYPE系列 会 改变读指针 readerIndex 的值。
-
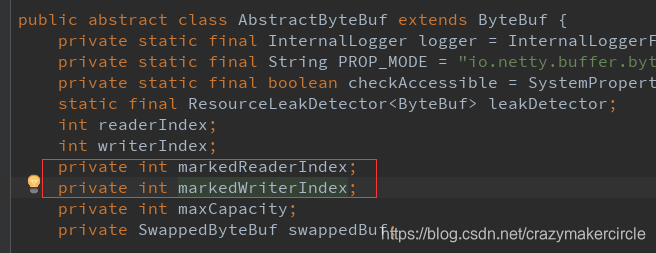
方法六:markReaderIndex() 与 resetReaderIndex()
这里两个方法一起介绍。
前一个方法,表示把当前的读指针ReaderIndex 保存在 markedReaderIndex 属性中。
后一个方法,表示把当前的读指针 ReaderIndex 恢复到之前保存的 markedReaderIndex 值 。
标记 markedReaderIndex 属性, 定义在 AbstractByteBuf 抽象基类中。
截图如下:
ByteBuf 的引用计数
Netty 的 ByteBuf 的内存回收工作,是通过引用计数的方式管理的。
大致的引用计数的规则如下:
- 默认情况下,当创建完一个 ByteBuf 时,它的引用为1。
- 每次调用 retain()方法, 它的引用就加 1 ;
- 每次调用 release() 方法,是将引用计数减 1。
如果引用为0,再次访问这个 ByteBuf 对象,将会抛出异常。
如果引用为0,表示这个 ByteBuf 没有地方被引用到,需要回收内存。
Netty的内存回收分为两种情况:
- Pooled 池化的内存,放入可以重新分配的 ByteBuf 池子,等待下一次分配。
- Unpooled 未池化的 ByteBuf 内存,确保GC 可达,确保 能被 JVM 的 GC 回收器回收到。
ByteBuf 的浅层复制
ByteBuf 的浅层复制分为两种,有切片slice 浅层复制,和duplicate 浅层复制。

slice 切片浅层复制
首先说明一下,这是一种非常重要的操作。可以很大程度的避免内存拷贝。这一点,对于大规模消息通讯来说,是非常重要的。
slice 操作可以获取到一个 ByteBuf 的一个切片。一个ByteBuf,可以进行多次的切片操作,多个切片可以共享一个存储区域的 ByteBuf 对象。
slice 操作方法有两个重载版本:
-
public ByteBuf slice();
-
public ByteBuf slice(int index, int length);
两个版本有非常紧密的联系。
不带参数的 slice 方法,等同于 buf.slice(buf.readerIndex(), buf.readableBytes()) 调用, 即返回 ByteBuf 实例中可读部分的切片。
而带参数 slice(int index, int length) 方法,可以通过灵活的设置不同的参数,来获取到 buf 的不同区域的切片。
调用slice()方法后,返回的 ByteBuf 的切片,大致如下图:
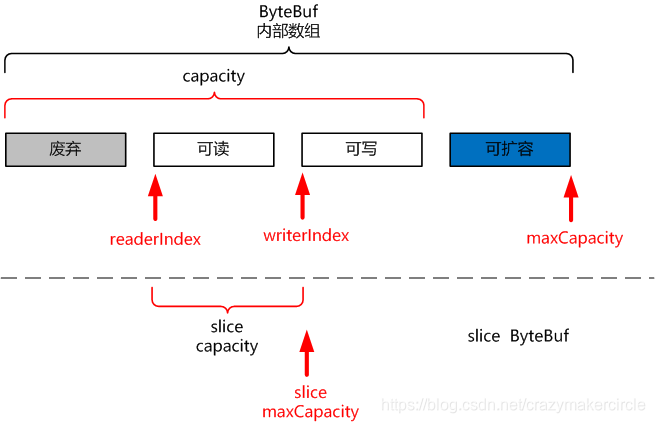
调用slice()方法后,返回的ByteBuf 切片的属性,大致如下:
-
slice 的 readerIndex(读指针)的值为 0
-
slice 的 writerIndex(写指针) 的 值为源Bytebuf的 readableBytes() 可读字节数。
-
slice 的 maxCapacity(最大容量) 的值为源Bytebuf的 readableBytes() 可读字节数。maxCapacity 与 writerIndex 值相同,切片不可以写。
-
切片的可读字节数,为自己的 writerIndex - readerIndex。所有,切片和源Bytebuf的 readableBytes() 可读字节数相同。
-
也就是说,切片可读,不可写。
slice()切片和原ByteBuf的联系:
- 切片不会拷贝原ByteBuf底层数据,底层数组和原ByteBuf的底层数组是同一个
- 切片不会改变原 ByteBuf 的引用计数。
根本上,调用slice()方法生成的切片,是 源Bytebuf 可读部分的浅层复制。
下面的例子展示了 ByteBuf.slice 方法的演示:
public static void testSlice() {
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(9, 100);
print("allocate ByteBuf(9, 100)", buffer);
buffer.writeBytes(new byte[]{1, 2, 3, 4});
print("writeBytes(1,2,3,4)", buffer);
ByteBuf buffer1= buffer.slice();
print("buffer slice", buffer1);
}
结果如下:
after ===========allocate ByteBuf(9, 100)============
capacity(): 9
maxCapacity(): 100
readerIndex(): 0
readableBytes(): 0
isReadable(): false
writerIndex(): 0
writableBytes(): 9
isWritable(): true
maxWritableBytes(): 100
after ===========writeBytes(1,2,3,4)============
capacity(): 9
maxCapacity(): 100
readerIndex(): 0
readableBytes(): 4
isReadable(): true
writerIndex(): 4
writableBytes(): 5
isWritable(): true
maxWritableBytes(): 96
after ===========buffer slice============
capacity(): 4
maxCapacity(): 4
readerIndex(): 0
readableBytes(): 4
isReadable(): true
writerIndex(): 4
writableBytes(): 0
isWritable(): false
maxWritableBytes(): 0
duplicate() 浅层复制
duplicate() 返回的是源ByteBuf 的整个对象的一个浅层复制,包括如下内容:
- duplicate() 会创建自己的读写指针,但是值与源ByteBuf 的读写指针相同;
- duplicate() 不会改变源 ByteBuf 的引用计数
- duplicate() 不会拷贝 源ByteBuf 的底层数据
duplicate() 和slice() 方法,都是浅层复制。不同的是,slice() 方法是切取一段的浅层复制,duplicate() 是整个的浅层复制。
浅层复制的问题
浅层复制方法不会拷贝数据,也不会改变 ByteBuf 的引用计数,这就会导致一个问题。
在源 ByteBuf 调用 release() 之后,引用计数为零,变得不能访问。这个时候,源 ByteBuf 的浅层复制实例,也不能进行读写。如果再对浅层复制实例进行读写,就会报错。
因此,在调用浅层复制实例时,可以通过调用一次 retain() 方法 来增加引用,表示它们对应的底层的内存多了一次引用,引用计数为2,在浅层复制实例用完后,需要调用两次 release() 方法,将引用计数减一,不影响源ByteBuf的内存释放。
写在最后
至此为止,终于完成ByteBuf的具体使用B介绍。
如果想知道ByteBuf的分配、释放, 请看:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号